







深度学习 - GPT是什么?直观解释Transformer
作者:夏驰和徐策
标签:GPT、Transformer、深度学习、自然语言处理、视觉讲解
在人工智能领域,“GPT”已经成为一个家喻户晓的词汇。从GPT-2到ChatGPT,再到最近发布的GPT-4o,每一代都在刷新人们对AI语言理解与生成能力的认知。那么,GPT到底是什么?它的核心——Transformer结构又是怎么运作的?今天,我们通过一组直观有趣的图示,带你理解GPT背后的关键概念。
一、GPT = Generative + Pre-trained + Transformer
在名字里,GPT 分别代表:
-
Generative:生成型模型,可以自动生成文本、图像,甚至音频等内容。
-
Pre-trained:预训练模型,先在大规模语料上学习,再根据具体任务进行微调。
-
Transformer:一种神经网络架构,已成为现代AI模型的主力框架。
你可以理解为:
先让模型读几百万本书,熟悉世界的语言,然后再教它写邮件、写代码、做客服……这样就不需要从零学起,既聪明又高效。
二、预训练的“可调表盘” —— 微调机制

图片中展示的是:预训练模型的每一个神经元就像一个可以调节的表盘,预训练阶段把这些表盘大致调到合适的方向,而在**微调(fine-tuning)**阶段,我们只需要针对特定任务(如写诗、翻译、识别图片等)稍微调节即可。
这就是GPT能“一专多能”的关键。
三、Transformer 是如何运作的?
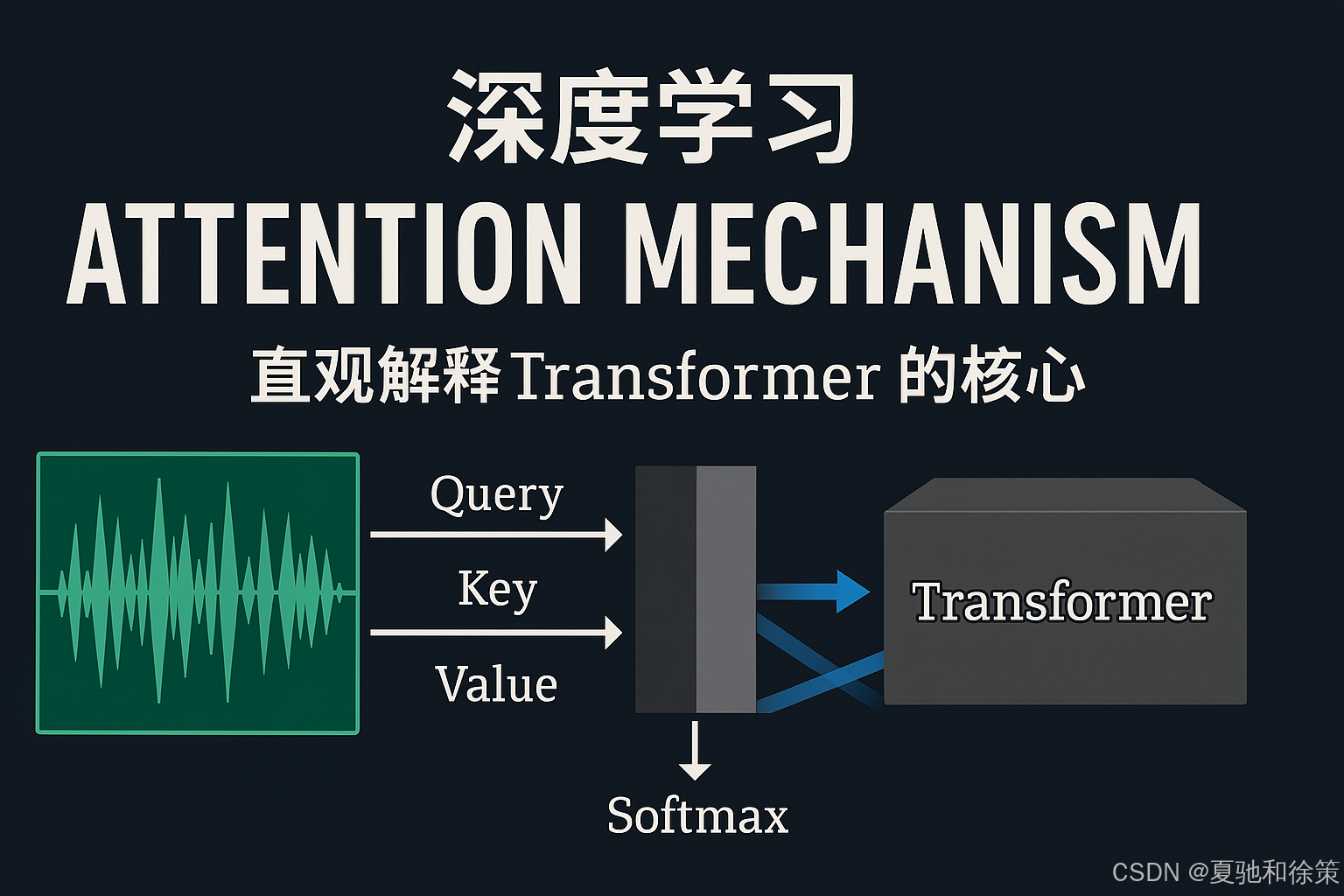
Transformer 是GPT的核心,下面我们用一个图解来直观了解它的内部运作方式:

这张图展示了 Transformer 的注意力机制:每个单词会和其它所有单词进行“信息交流”,通过“查询(Query)-键(Key)-值(Value)”的方式进行注意力加权计算,最后用 Softmax 做归一化。
比如,单词 “blue” 会关注 “fluffy” 和 “creature” 的程度不同,这种机制让 Transformer 理解上下文变得非常强大。
四、Transformer 的多模态扩展能力
Transformer 并不只用于文本:
| 类型 | 输入 | 输出 |
|---|---|---|
| Voice-to-Text | 音频波形 | 转写成文本 |
| Text-to-Image | 文本描述 | 生成图像(如DALL·E) |
| Text-to-Text | 一段文字 | 生成新文本(如GPT) |
例如,输入一句话:“一只蓝色毛茸茸的π形动物在森林中觅食”,模型就能输出一张极具创意的图片。
五、回到文本预测本质:一步步拼接词语
Transformer 的“生成”其实是:
预测下一个词 → 拼接 → 再预测 → 再拼接……
最终拼成一段完整的话。如下图所示:
在这个例子中,从句子“Behold, a wild pi creature, foraging in its native ___”开始,模型会给出多个可能的词(如land、forest、territory等),并为每个打上概率,选择概率最大者作为下一个输出。
六、早期的GPT模型和它的故事逻辑问题
这是早期GPT-2的输出示例,可以看出虽然语法通顺,但整体故事逻辑很混乱,比如“为了不杀死它,他放火烧了这片土地”。这表明早期模型只是在词与词之间做概率连接,而不是理解“含义”。
不过,正是通过不断扩大模型规模、改进训练数据和算法,才有了现在的ChatGPT、GPT-4o这样的强大对话引擎。
七、小结:为什么GPT如此强大?
GPT模型之所以强大,是因为它结合了三种力量:
-
Transformer:具备理解上下文的深层能力;
-
预训练:通读全网内容,拥有“常识”;
-
生成机制:可以灵活创造、联想、回答问题。
八、未来展望
随着GPT技术的演化,我们已经看到它在:
-
辅助编程(如Copilot)
-
文案生成
-
客服机器人
-
医疗问诊
-
自动驾驶感知融合
等多个场景广泛落地。而背后的Transformer架构,也在视觉(ViT)、语音(Whisper)、多模态(GPT-4o)中持续发光发热。



















 648
648

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











