








动手学深度学习 - 计算性能 - 13.3 自动并行
13.3.1 GPU上的并行计算
现代深度学习框架(如 MXNet 和 PyTorch)可以自动构建计算图,并借助依赖分析实现任务的并行执行。在不相互依赖的操作中,系统能够智能并行计算,以提升整体运行效率。
我们使用 run(x) 函数执行 50 次矩阵乘法操作,并分别在两个 GPU 上进行测试,结果显示两块 GPU 并行时整体耗时更短:
devices = d2l.try_all_gpus()
def run(x):
return [x.mm(x) for _ in range(50)]
x_gpu1 = torch.rand(size=(4000, 4000), device=devices[0])
x_gpu2 = torch.rand(size=(4000, 4000), device=devices[1])
在启用并行计算时,两个 GPU 同时执行任务,整体效率显著提升:
with d2l.Benchmark('GPU1 & GPU2'):
run(x_gpu1)
run(x_gpu2)
torch.cuda.synchronize()
13.3.2 并行计算与通信
自动并行计算不仅体现在计算任务本身,还包括设备间的数据传输。例如将 GPU 的输出复制回 CPU,在同步和非阻塞方式之间效率差异明显:
def copy_to_cpu(x, non_blocking=False):
return [y.to('cpu', non_blocking=non_blocking) for y in x]
同步方式复制:
with d2l.Benchmark('Copy to CPU'):
y_cpu = copy_to_cpu(y)
torch.cuda.synchronize()
非阻塞方式可以边计算边传输,显著提升性能:
with d2l.Benchmark('Run on GPU1 and copy to CPU'):
y = run(x_gpu1)
y_cpu = copy_to_cpu(y, True)
torch.cuda.synchronize()
13.3.3 两层 MLP 的多设备执行图
如下图所示,两层全连接神经网络(MLP)在两个 GPU 上分批并行执行,通过 CPU 聚合梯度并更新参数,最后再广播回各 GPU,展示了自动并行下计算与通信协作的全过程: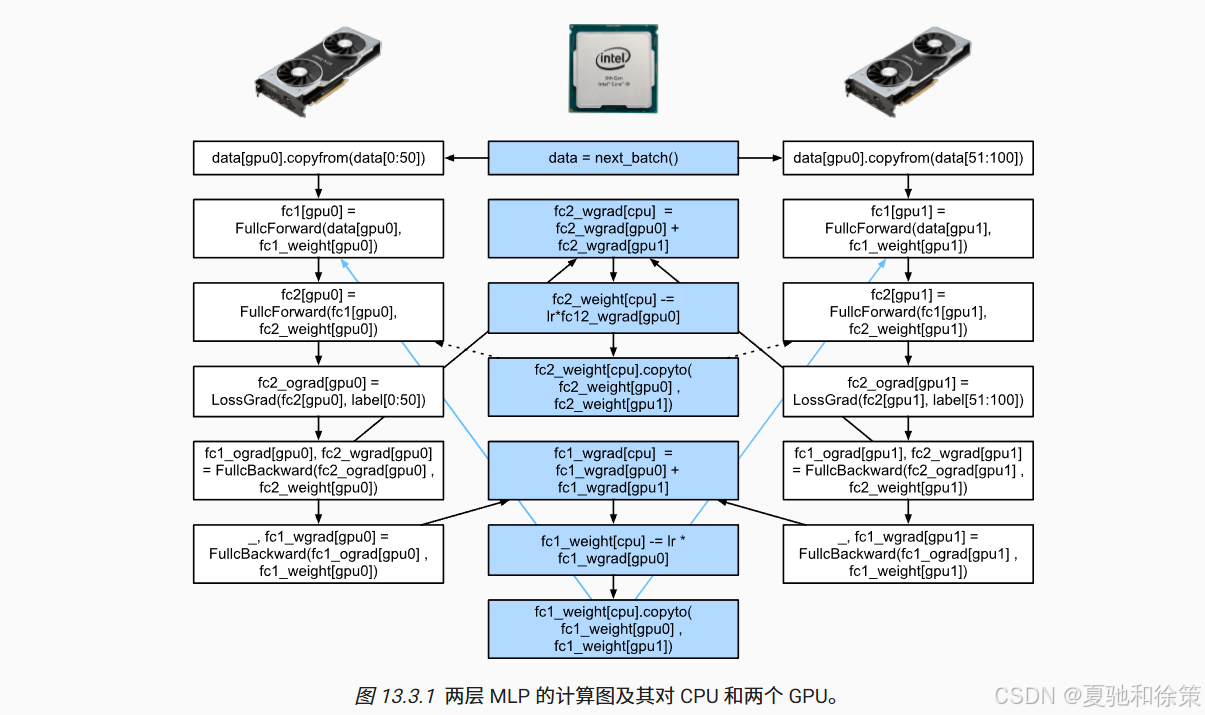
13.3.4 小结
-
深度学习框架自动识别任务依赖关系并进行并行调度。
-
多设备(如多个 GPU 和 CPU)之间的并行可提升训练效率。
-
数据通信可与计算同时进行,减少空闲资源等待。
-
利用
non_blocking=True和torch.cuda.synchronize()可优化 GPU-CPU 数据交互。
13.3.5 练习
-
在
run()函数中执行多个无依赖任务,观察是否自动并行。 -
设计小任务测试并行是否仍然有效。
-
构建包含 CPU、GPU 和通信的实验,分析性能表现。
-
使用 Nsight 等调试工具验证是否真实实现并行。
-
构造复杂依赖的计算图,验证系统是否能保持正确性并并行执行。
📘 理论理解
什么是自动并行?
自动并行是一种由深度学习框架自动完成的计算调度优化技术,旨在加速训练或推理过程。在计算图中,系统会自动分析各个算子(如矩阵乘法、卷积等)之间的依赖关系,在不影响计算正确性的前提下,实现并发执行。
并行计算 VS 串行计算
-
串行执行: 每一步操作等待前一步完成;
-
并行执行: 多个操作若无依赖,则可同时在多个 GPU/CPU 上运行。
例如,在代码中对两个不同的张量进行 mm() 运算且二者没有依赖关系时,框架可以将它们调度到不同的 GPU 并行运行。
非阻塞复制(non_blocking)
将数据从 GPU 移动到 CPU 的过程中,若使用 non_blocking=True,就可以边复制边计算,充分利用带宽,减少等待,提高吞吐率。
GPU 与 CPU 协作机制
当模型分布在多个 GPU 上进行训练时,梯度汇总和参数更新通常发生在 CPU,随后再广播回 GPU。这种计算-通信交错执行是典型的自动并行策略。
🏢 大厂实战理解(以 Google、字节跳动、NVIDIA 为例)
✅ Google(TensorFlow XLA)
Google 的 XLA(Accelerated Linear Algebra)编译器自动识别可并行操作,并将其映射到多个 TPU 或 GPU 上。例如在 TPUEstimator 中,训练图会自动转换为多个设备的流水线,并融合不依赖的操作以减少内存带宽消耗。
关键词:XLA Graph Fusion、TPU Multi-core Mapping
✅ 字节跳动(多任务训练框架)
在推荐系统或多模态任务中,字节跳动的训练平台将不同模块(如图像编码、文本编码、视频编码)部署到不同 GPU 上并行运行,并通过 NCCL 实现参数同步。后台使用异步的非阻塞通信避免性能瓶颈。
关键词:异构计算、NCCL、模型流水线切分
✅ NVIDIA(CUDA Graph & TensorRT)
NVIDIA 在其 CUDA Graph 模型中提供了更底层的自动并行机制,通过构建“图执行计划”将一批无依赖的 kernel 并行调度,避免 CPU 频繁调用,提高 GPU 利用率。
TensorRT 的优化器则会自动将多个操作融合为一个 CUDA Kernel,减少启动开销,实现低延迟部署。
关键词:CUDA Graph、Kernel Fusion、Asynchronous Copy
🔚 小结
| 维度 | 理论层面 | 实战层面 |
|---|---|---|
| 并行单位 | 操作级(Op)、任务级(Task) | GPU/TPU 核心、集群调度 |
| 执行控制 | 依赖分析、拓扑排序 | 调度器、编译器(XLA/CUDA Graph) |
| 优化策略 | 非阻塞数据传输、流水线 | NCCL 通信融合、Kernel 合并 |
| 应用场景 | 多 GPU 训练、分布式推理 | AIGC 推理、实时推荐、多模态训练 |
经典面试题汇总(含答案思路)
🧠 一、基础原理类
Q1:什么是自动并行?在深度学习训练中有什么用?
难度:★☆☆☆☆(字节跳动面试中基础问题)
参考答案思路:
-
自动并行指框架自动调度计算图中没有依赖的操作,并发执行。
-
减少等待时间,提高 GPU 利用率,加快模型训练速度。
-
框架如 PyTorch 和 TensorFlow 具备自动依赖分析和调度能力。
Q2:你如何判断两段张量操作可以并行执行?
难度:★★☆☆☆(百度飞桨面试中出现)
参考答案思路:
-
是否存在数据依赖关系是判断能否并行的关键。
-
若两个操作使用的输入张量互不依赖,输出也无交叉,就可以并行。
-
PyTorch 会在后台构建计算图,依据依赖自动调度。
🧩 二、编译与加速类
Q3:请简述 PyTorch 中 non_blocking=True 的作用。
难度:★★☆☆☆(美团面试中出现)
参考答案思路:
-
表示数据拷贝过程为非阻塞,GPU 数据迁移到 CPU 后不阻塞主线程;
-
常用于
Tensor.to('cpu', non_blocking=True),配合pin_memory=True提高数据预处理效率; -
本质是为了提升数据传输和计算的并发性。
Q4:你了解 CUDA Graph 吗?它和自动并行有什么关系?
难度:★★★☆☆(NVIDIA 面试常问)
参考答案思路:
-
CUDA Graph 是将一串 GPU 操作编译为图结构,避免每次调用高昂的 Kernel 启动开销;
-
自动并行的高级形式,自动识别图中并发部分;
-
PyTorch 和 TensorRT 均支持 CUDA Graph 推理,性能大幅提升。
🧠 三、工程场景类
Q5:在一个多卡模型训练任务中,自动并行机制可能出现什么问题?你如何优化?
难度:★★★★☆(字节、阿里P7常问)
参考答案思路:
-
问题:
-
计算和通信不重叠;
-
参数同步等待;
-
内存占用不均;
-
-
解决:
-
使用
torch.distributed+torch.cuda.Stream控制并行流; -
引入梯度累积、混合精度减少通信;
-
数据并行 + 模型并行结合。
-
Q6:如何在模型推理中实现自动并行加速?
难度:★★★☆☆(腾讯优图场景题)
参考答案思路:
-
利用
torch.jit.trace()生成计算图; -
多路输入批次化,通过异步复制 + 推理 +结果拉回(流水线);
-
TensorRT 重写模型执行图,自动融合算子提升并行性。
🏁 总结建议
| 方向 | 建议掌握点 |
|---|---|
| 框架支持 | PyTorch 自动依赖图、non_blocking、pin_memory |
| 多卡并行 | torch.nn.DataParallel, torch.nn.parallel.DistributedDataParallel |
| 推理加速 | CUDA Graph、TensorRT、JIT trace/fusion |
| 通信优化 | NCCL、AllReduce、异步通信 |
📌 大厂真实场景题与参考答案(含项目上下文)
🎯 场景题 1:字节跳动视频推荐推理延迟优化
背景:你负责优化字节跳动视频推荐系统中深度学习模型的 GPU 推理效率。模型为多路塔式结构(Multi-Tower),包含多个子模块如用户塔、视频塔、标签塔等,在预测点击率时联合输出。你注意到推理过程中 GPU 利用率只有 30%。
问题:请你分析可能的性能瓶颈,并给出利用自动并行的优化策略。
参考答案:
-
性能瓶颈分析:
-
模型内部模块串行执行,缺乏并行度;
-
子塔之间没有依赖,理论上可以并行;
-
各子塔加载数据后依赖主线程统一调度,存在空闲等待。
-
-
自动并行优化方案:
-
**模块级并行:**重构模型,将多个子塔的前向传播拆成多个
torch.jit.script或异步流; -
**数据迁移并行:**使用
non_blocking=True加快 CPU→GPU 的传输; -
使用
torch.cuda.Stream: 为每个子塔分配独立的 CUDA 流,允许子模块并发; -
**异步批处理:**提前将输入 batch 分块预处理,提升流水线吞吐量。
-
🎯 场景题 2:阿里巴巴商品搜索模型训练优化
背景:在阿里商品搜索中,正在训练一个跨品类商品识别的图神经网络模型。模型结构复杂,包含多个 GNN 层 + 多维嵌入融合层,在多 GPU 分布式训练时速度很慢。
问题:请提出一套基于自动并行的优化建议,提升训练吞吐量。
参考答案:
-
并行粒度判断:
-
多维嵌入处理层之间无显著依赖,可并行;
-
图卷积层存在跨节点依赖,需考虑依赖边界;
-
-
优化策略:
-
**模块级自动并行:**利用 PyTorch 的计算图调度,在模型结构允许的部分开启并行;
-
**GraphShard 拆图:**图结构切片,将子图映射到不同 GPU 上计算;
-
**异步梯度同步:**使用
torch.distributed中的no_sync()分批同步,减少通信瓶颈; -
**梯度累积 + 混合精度训练:**减小每次反向传播内存开销,提高并行效率。
-
🎯 场景题 3:腾讯广告点击模型离线训练管道优化
背景:你维护的离线训练管道每天训练大规模点击预估模型,在训练中需要从多个 CSV 文件中加载历史点击数据、特征归一化并送入模型。虽然用了 GPU,但训练时间仍然太久。
问题:请你定位瓶颈,并利用自动并行思路改造训练过程。
参考答案:
-
问题定位:
-
数据加载与模型训练串行;
-
数据在 CPU 处理耗时多,占据训练主线程;
-
DataLoader无法充分并发加载。
-
-
自动并行方案:
-
**
DataLoader配置多进程 +pin_memory=True:**加快数据搬运; -
**数据预处理异步:**归一化、编码操作移到 GPU 前的异步线程;
-
**训练推理并行:**训练 loop 中提前加载下一批数据;
-
混合精度训练 +
torch.compile():减少每 step 内核数量,提升整体并行度。
-
✅ 总结一句话
自动并行 ≠ 自动变快,但在模块无依赖的条件下,是优化大型模型结构和输入管道的核心加速方式,结合多线程、CUDA stream 与模型结构重构使用,效果更佳。



















 655
655

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











