







深度学习 - 直观解释注意力机制,Transformer的核心
作者:夏驰和徐策
标签:深度学习、注意力机制、Transformer、NLP、视觉化讲解
“注意力机制”常被称为 Transformer 的灵魂。没错,今天大热的 GPT、BERT、SAM、DALL·E 都是基于 Transformer 构建的,而 Transformer 又是建立在注意力机制上的。如果你想真正理解 GPT 的底层逻辑,那就必须搞懂——
注意力机制(Attention Mechanism)到底在干什么?
一、什么是注意力机制?
我们来个类比👇
假如你在读一句话:
“The cat sat on the mat because it was warm.”
请问,“it” 指的是谁?大脑会自动联想到 “mat”。
为什么?
因为你的大脑给“mat”分配了更高的注意力权重,而不是“cat”。
同样地,注意力机制的核心思想就是:
👉 在处理每一个词的时候,根据其他词的重要性,分配不同的注意力分数,让模型“重点关注”上下文中与当前词相关的部分。
二、数学不讲,图来讲!
以下是经典的 Transformer 可视化图解(截图源自 3Blue1Brown 的视频讲解):

在处理句子 “a fluffy blue creature…” 时,模型对每个词都计算了对应的注意力得分。
比如在计算 “blue” 这个词时,它会去“看”其他词(比如 fluffy、creature):
-
给 fluffy 分数 0.3
-
给 creature 分数 0.6
-
给其它词分数 0.1
然后把这些词的表示“加权求和”,形成一个新的“上下文感知”表示。
这个过程我们称为:
Scaled Dot-Product Attention
三、注意力机制的结构公式(直观解释)
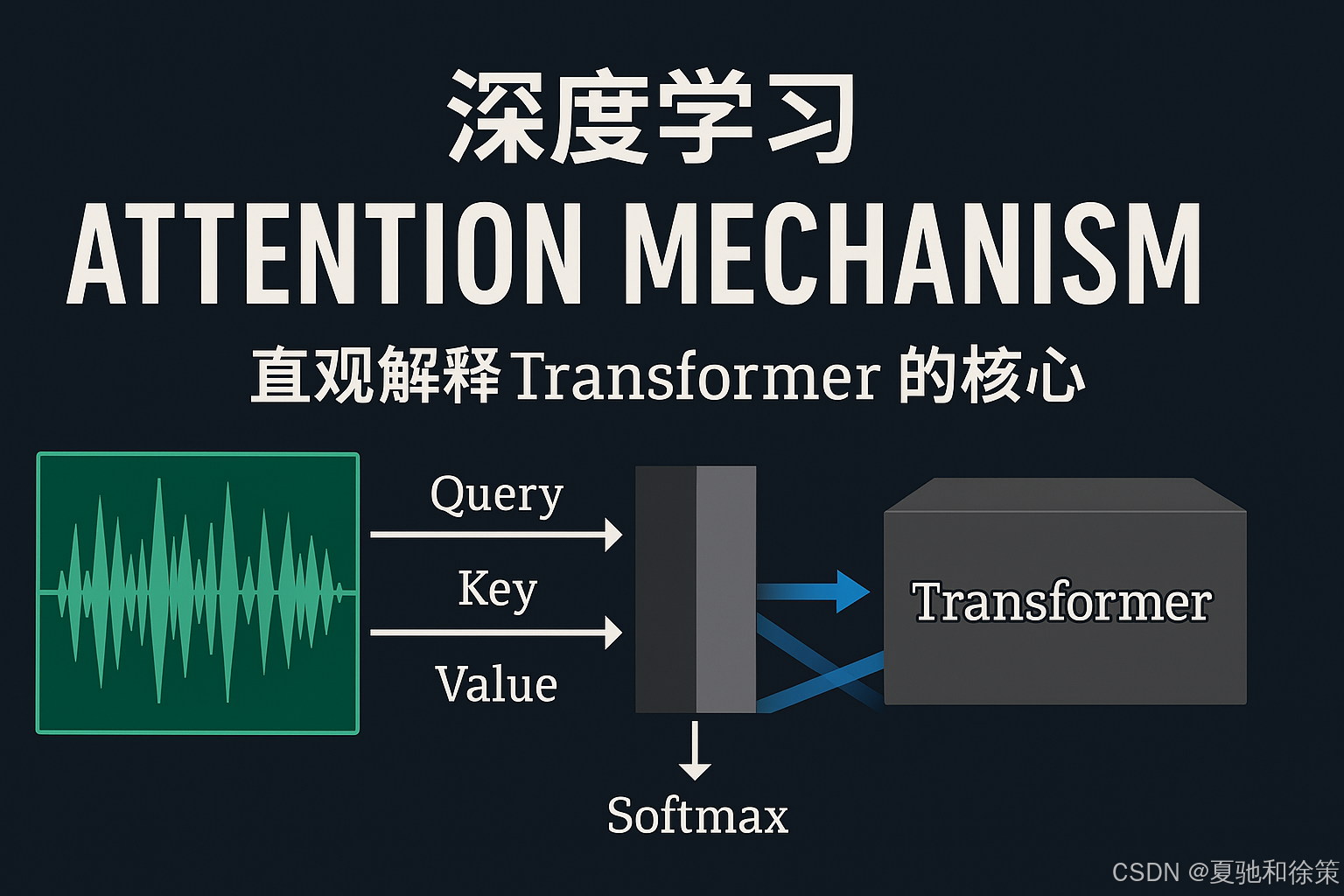
Transformer 中的注意力机制由三个重要部分组成:
-
Query(查询)
-
Key(键)
-
Value(值)
我们可以把它想象成一次图书馆检索:
| 模型部分 | 类比 |
|---|---|
| Query | 你想查找什么内容 |
| Key | 图书馆中所有书的目录信息 |
| Value | 这些书的实际内容 |
模型会将 Query 和每个 Key 做点积,得到相似度,再用 Softmax 转成概率(注意力权重),再乘上 Value,得出最终的加权表示。
公式是:
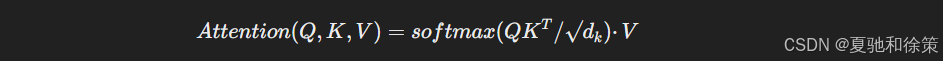
✅ QK<sup>T</sup> 是匹配程度
✅ √d<sub>k</sub> 是防止数值爆炸
✅ softmax 变成概率分布
✅ 最后乘 V,获得上下文融合的表示
四、多头注意力机制(Multi-head Attention)
为什么要多头?
因为一个注意力头只能看一个角度,比如“语法结构”,但我们还想看“语义含义”、“词性”、“上下文关系”……
所以 Transformer 干脆:
🚀 开多个注意力头,并行计算不同视角的注意力分布,然后拼接融合。
这就构成了强大的 Multi-head Attention。
五、动画演示注意力机制
可以参考这张图的动画结构:
每个词都在动态地“看”其他词,并根据 Softmax 权重重新组合信息。最终得到的是:
每个词的表示,不再是孤立的词向量,而是综合了上下文的动态表示!
六、为什么注意力机制如此强大?
| 传统RNN/GRU | Attention(Transformer) |
|---|---|
| 顺序执行,无法并行 | 可并行训练,速度快 |
| 长句依赖难捕捉 | 任意距离都能关联 |
| 表示受限,容易遗忘 | 注意力保留更多信息 |
七、应用举例
-
文本生成(GPT系列)
-
翻译任务(原始Transformer就是用于英法互译)
-
图像理解(ViT: Vision Transformer)
-
语音识别(Whisper)
未来甚至还有:
-
多模态(如图文音联合理解)
-
生物序列建模(DNA/RNA)
-
强化学习策略建模(Agent)
八、总结
你可以把“注意力机制”看作是:
“让模型像人一样专注,决定哪里该多看一眼,哪里可以略过。”
这就是 Transformer 强大的底层基础,也是 GPT 得以理解复杂语义、生成流畅文本的关键。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











