








📘 吴恩达机器学习 - 梯度下降
本文旨在从理论到实践,系统讲解机器学习中最核心的优化方法之一 —— 梯度下降算法(Gradient Descent)。通过六个板块,带你从原理出发,一步步深入理解梯度下降的数学逻辑、直观几何意义、实际应用与 Python 实现。
✳️ 1. 梯度下降:什么是它?
梯度下降是一种用于 最小化函数的优化算法。在机器学习中,我们通常定义一个代价函数(cost function)来衡量模型预测与真实值之间的误差。我们的目标是通过调整模型参数,使得这个代价函数的值尽可能小。
数学上,设参数为 θ\thetaθ,代价函数为 J(θ)J(\theta)J(θ),则梯度下降的基本更新规则为:
![]()
其中:
-
∇θJ(θ)\nabla_{\theta} J(\theta)∇θJ(θ) 是代价函数关于参数 θ\thetaθ 的梯度(偏导向量)
-
α\alphaα 是学习率(learning rate),控制每次参数更新的“步长”
换句话说,每次迭代我们都顺着梯度的“反方向”走一步,因为梯度的方向是函数增长最快的方向,走它的反方向就是下降最快。
✳️ 2. 实现梯度下降:代码实现(Python版)
我们以最基础的线性回归为例,假设模型为:
![]()
代价函数为:
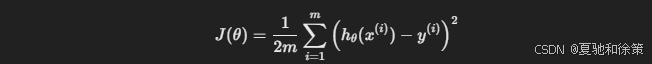
代码如下:
import numpy as np
# 计算代价函数
def compute_cost(X, y, theta):
m = len(y)
error = X.dot(theta) - y
return (1 / (2 * m)) * np.dot(error, error)
# 梯度下降算法实现
def gradient_descent(X, y, theta, alpha, num_iters):
m = len(y)
cost_history = []
for _ in range(num_iters):
gradient = (1 / m) * X.T.dot(X.dot(theta) - y)
theta -= alpha * gradient
cost_history.append(compute_cost(X, y, theta))
return theta, cost_history
# 示例数据
X = np.array([[1, 1], [1, 2], [1, 3]]) # 包含 x0 = 1
y = np.array([1, 2, 3])
theta = np.zeros(2)
alpha = 0.1
iterations = 100
final_theta, cost_hist = gradient_descent(X, y, theta, alpha, iterations)
print("Final theta:", final_theta)
✳️ 3. 梯度下降的直观理解
想象你在一个复杂的山谷中,四周是起伏的地形,而你站在山的一处陡坡上。你看不见整个地图,但你知道脚下的坡度,于是每一步都往下降最快的方向走,最终你就能走到谷底。
这正是梯度下降的几何意义:
-
代价函数 J(θ)J(\theta)J(θ) 在二维空间中构成一个类似碗状的三维曲面
-
每次迭代更新参数,其实是“从当前点在碗面上往下滑动”
-
直到滑到最低点,也就是最优解
例如吴恩达课程中展示的代价函数图像,其切面是椭圆,整个函数是个 凸函数,保证了不会卡在局部最小值。
✳️ 4. 学习率:如何决定“走多远”
学习率 α\alphaα 是梯度下降的核心参数。
-
学习率过大:容易越过最优点,甚至导致发散(代价函数值越来越大)
-
学习率过小:收敛很慢,训练效率低
一个合理的做法是:从一个适中的学习率开始训练,通过观察损失下降曲线动态调整。例如,使用 0.01、0.03、0.1、0.3、1 等多组尝试。
学习率就像我们走山路时每一步的步长。步子太大可能摔跤,步子太小又太慢。
✳️ 5. 梯度下降在线性回归中的作用
在单变量线性回归中:
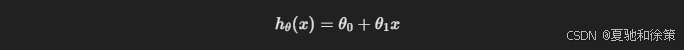
我们定义的代价函数是一个凸函数,图像是一个“碗型”,且具有唯一的全局最小值。此时梯度下降非常有效。
更新公式如下:
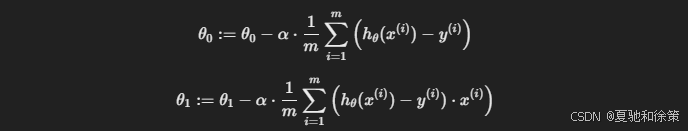
这样迭代更新,就能逼近最佳的 θ0,θ1\theta_0, \theta_1θ0,θ1 参数值。
✳️ 6. 运行梯度下降:如何评估效果
每次训练完,我们可以画出 cost function 的下降曲线:
import matplotlib.pyplot as plt
plt.plot(range(len(cost_hist)), cost_hist)
plt.xlabel("Iterations")
plt.ylabel("Cost J(theta)")
plt.title("Gradient Descent Convergence")
plt.grid(True)
plt.show()
如果曲线平滑下降并趋于稳定,说明训练正常;如果震荡或不收敛,需要重新调整学习率。
✅ 结语(逻辑总结)
梯度下降本质是一种一阶近似 + 局部最速逼近的数值优化方法,其效果建立在如下假设前提之上:
-
目标函数 J(θ)J(\theta)J(θ) 可导(必要条件)
-
J(θ)J(\theta)J(θ) 是凸函数(保证唯一最小值)
-
学习率 α\alphaα 合理(控制收敛稳定性)
该算法在形式上简洁,在几何上直观,在工程上可实现,是机器学习算法中最核心的数值基础之一。
梯度下降不是一个黑盒,它的每一步都有明确定义、明确目的、明确边界——这是工程系统中极为罕见的“可解释性最强的优化器”。



















 417
417

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











