







一、mini_batch梯度下降法
如果使用batch梯度下降法,mini-batch的大小为m,每个迭代需要处理大量的训练样本,弊端在于巡林样本巨大的时候,单次迭代耗时过长。
如果使用随机梯度下降法(mini-batch为1),只处理一个样本,通过减小学习率,噪声得到改善或者减小。缺点是失去向量化带来的加速,效率低下。且永远不会收敛,会一直在最小值附近波动,并不会达到最小值并停留在此。
所以实践中,通常选择不大不小的mini-batch尺寸。一方面,得到了大量向量化,比一次性处理多个样本快得多。另一方面,不需要等待整个训练集被处理完就可以开始后续工作。mini-batch梯度下降法不会总朝向最小值靠近,但比随机梯度下降更持续的靠近最小值的方向,也不一定在很小的范围内收敛或波动,如果出现这个问题,可以慢慢减少学习率。
mini-batch的选取指导原则:
如果训练集较小,直接使用batch梯度下降法,比如少于2000个样本;
样本数目较大的话,一般的mini-batch大小设置为64到512。考虑到电脑内存设置和使用的方式,mini-batch大小为2的n次方,代码运行的会快一些。
二、指数加权平均数
指数加权移动平均(Exponentially Weighted Moving Average),他是一种常用的序列处理方式。在 t t t时刻,他的移动平均值公式是: V t = β V t − 1 + ( 1 − β ) θ t V_{t}=\beta V_{t-1}+(1-\beta) \theta_{t} Vt=βVt−1+(1−β)θt , t = 1 , 2 , 3 , . . . n t=1,2,3,...n t=1,2,3,...n ,其中 V t V_{t} Vt是 t t t时刻的移动平均预测值; θ t \theta_{t} θt为 t t t时刻的真实值; β \beta β是权重;
以下该链接有β与平均多少天之间的关系:
参考链接
偏差修正:
在估测初期,不用 v t v_{t} vt,而是用 v t 1 − β t \frac{v_{t}}{1-\beta _{t}} 1−βtvt
但在机器学习中,大部分时候并不在乎执行偏差修正,熬过初始时期,继续计算。
三、动量梯度下降法(momentum)
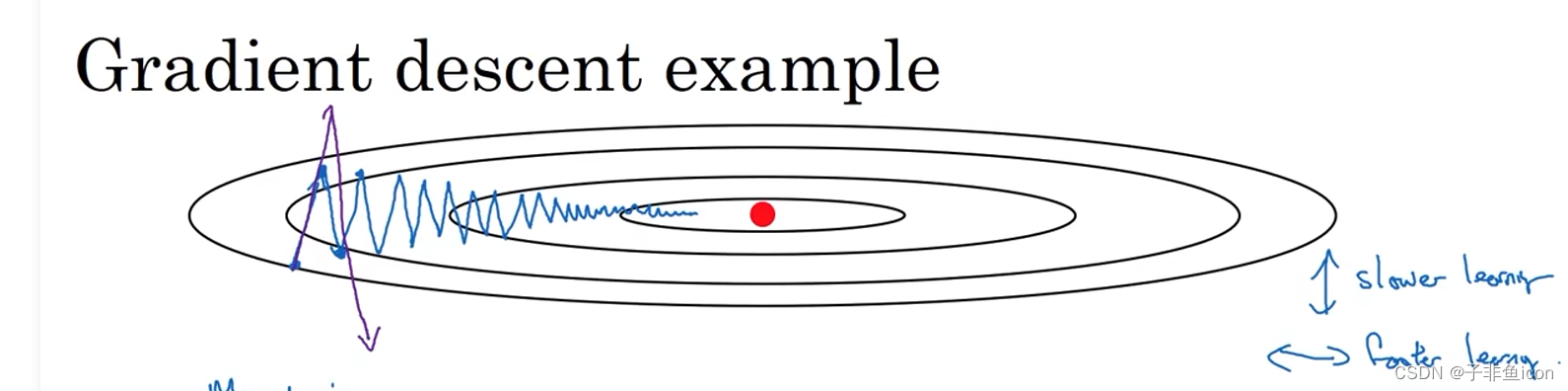
对于梯度下降法,很可能会出现上图那样的情况,需要很多的计算步骤。这种上下的波动会减慢梯度下降法的速度,无法使用更大的学习率(否则摆动较大,紫色箭头),就只能使用较小的学习率。但从横轴来说,希望加快学习,能够快速从左到右,移动到最小值。
动量梯度下降法的实现:



注:
1. β \beta β最常用的值是0.9,是很棒的鲁棒数。
2.关于偏差校正,一般也不会进行。因为10次迭代后,移动平均已经过了初始阶段。
3. v d w v_{dw} vdw是维数和 d w dw dw, w相同的零矩阵。
4.有的资料会把后面的项 1 − β 1-\beta 1−β删除,这导致的结果是:学习率 α \alpha α要根据 1 1 − β \frac{1}{1-\beta} 1−β1相应变化。
四、RMSprop
RMSprop也可以加速梯度下降。
假设纵轴是b,横轴是W,虽然横轴方向在缓慢推进,但纵轴方向会有大幅度地摆动。RMSprop就能减缓b方向的学习,加快横轴的学习。


简单解释一下就是:db大,所以算得的Sab也大,b的更新式除以了一个较大的数,所以减缓了b的摆动。蓝色的前进曲线被压缩为绿色的:

注:如果 S d w S_{dw} Sdw的平方根趋近于0,要确保算法不会除以0,所以就要在分母上加上一个很小很小的数 ϵ \epsilon ϵ,比如 1 0 − 8 10^{-8} 10−8,保证数值稳定。
五、Adam优化算法
结合了Momentum和RMSprop


超参数的选择(常用):
β 1 \beta _{1} β1:0.9
β 2 \beta _{2} β2:0.999
ϵ \epsilon ϵ: 1 0 − 8 10^{-8} 10−8
六、学习率衰减
加快学习算法的一个办法就是:随时间慢慢减少学习率。
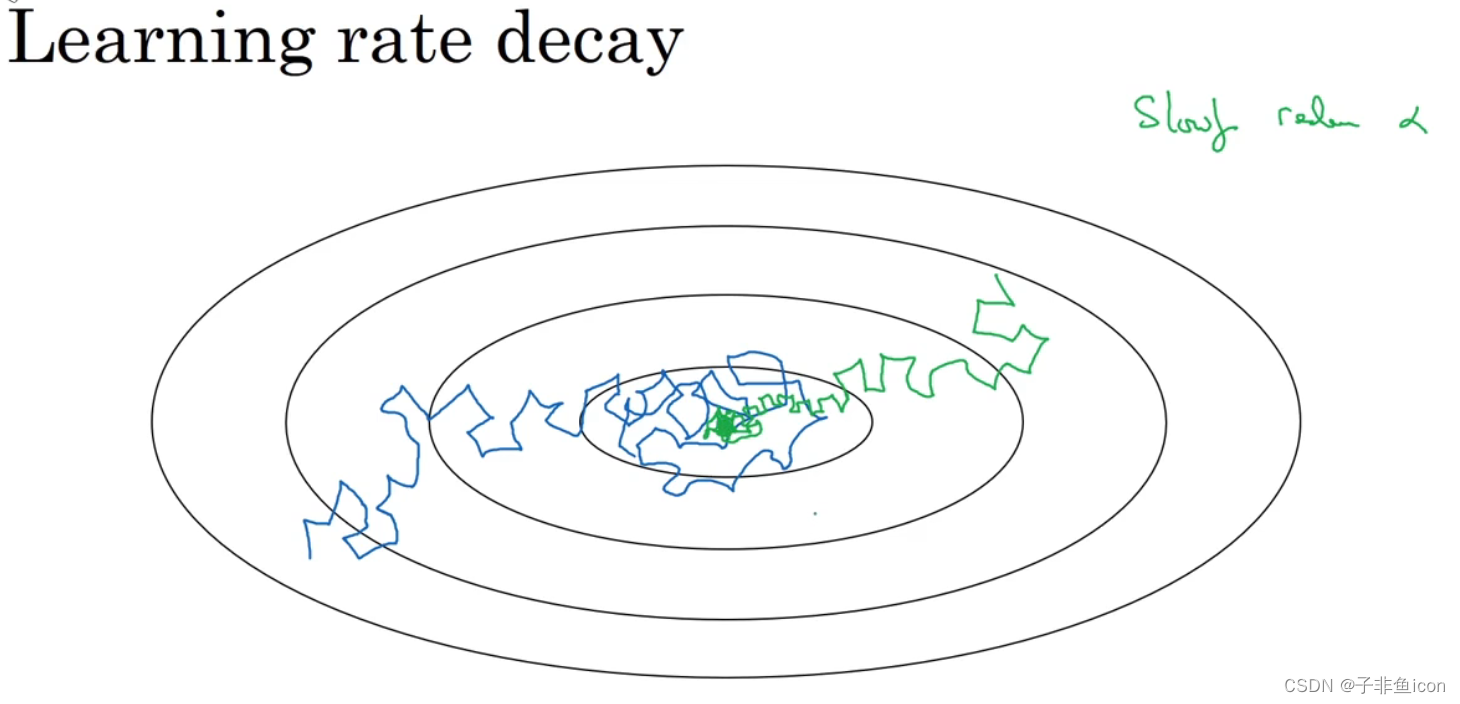
蓝色线:使用mini-batch梯度下降法,在迭代过程中,存在着噪音,下降朝向最小值,但不会精确收敛,在附近摆动。这是因为用的 α \alpha α是固定值。
绿色线:但如果随着 α \alpha α变小,步伐也会变小,最后曲线会在最小值附近很小的一块区域内摆动。
拆分成不同的mini-batch,第一次遍历训练集叫做第一代。

其他的一些衰减方式:
1. α = 0.9 5 e p o c
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 702
702

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









