







动手学深度学习 - 计算性能 - 13.2 异步计算
现代计算机是高度并行的系统,包含多个 CPU 核心(每个核心可能有多个线程)、多个处理单元以及多个 GPU。我们可以同时处理多个任务,通常运行在不同的设备上。然而,Python 本身并不擅长并行和异步编程,尤其在不借助外部框架的情况下,因为它是单线程语言。
幸运的是,深度学习框架如 MXNet 和 TensorFlow 采用了异步编程模型,而 PyTorch 则主要使用 Python 的调度器,两者在性能和易用性之间做出了不同的权衡。在 PyTorch 中,GPU 操作默认是异步的,这意味着在调用使用 GPU 的函数时,操作会被加入设备队列,但不会立刻执行。这种方式允许 CPU 或其他 GPU 同时继续其他计算任务。
理解异步计算的工作原理可以帮助我们优化程序性能,主动控制计算顺序,降低内存开销,提高处理器利用率。
13.2.1 通过 Backend 进行异步
我们从一个简单的例子入手:生成一个随机矩阵并计算其乘积。我们比较 NumPy(CPU)和 PyTorch(GPU)的性能差异:
# Warmup for GPU computation
device = d2l.try_gpu()
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
执行如下:
with d2l.Benchmark('numpy'):
for _ in range(10):
a = numpy.random.normal(size=(1000, 1000))
b = numpy.dot(a, a)
with d2l.Benchmark('torch'):
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
结果:
numpy: 1.4693 sec
torch: 0.0022 sec
尽管 GPU 本应更快,但差距之大说明了 GPU 操作是异步的。强制同步如下:
with d2l.Benchmark():
for _ in range(10):
a = torch.randn(size=(1000, 1000), device=device)
b = torch.mm(a, a)
torch.cuda.synchronize(device)
同步后时间变为:
Done: 0.0058 sec
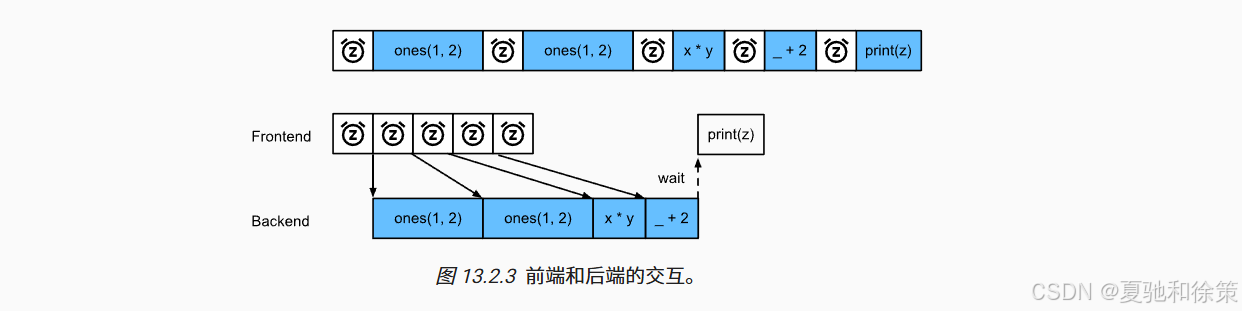
PyTorch 有一个前端(Python)和一个后端(C++),前端发出操作,后端排队并异步执行。图 13.2.1 至 13.2.3 展示了前后端之间的交互和依赖关系。
13.2.2 障碍和阻塞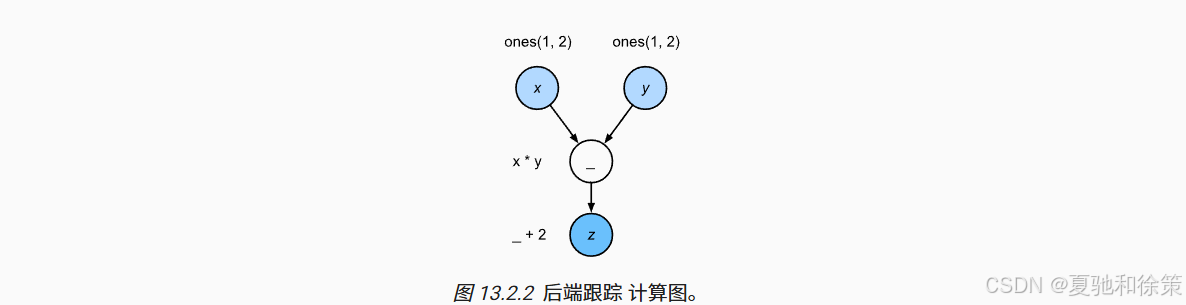
某些操作会强制 Python 等待后端计算完成,例如:
-
npx.waitall()等待所有任务完成; -
z.wait_to_read()等待特定变量计算完成。
with d2l.Benchmark('waitall'):
b = np.dot(a, a)
npx.waitall()
with d2l.Benchmark('wait_to_read'):
b = np.dot(a, a)
b.wait_to_read()
它们执行时间相近,但隐式阻塞更需注意。像 print(z)、z.asnumpy()、z.item() 都会导致阻塞。频繁地将 MXNet 变量转换为 NumPy 数据可能严重影响性能。
with d2l.Benchmark('numpy conversion'):
b = np.dot(a, a)
b.asnumpy()
with d2l.Benchmark('scalar conversion'):
b = np.dot(a, a)
b.sum().item()
13.2.3 改进计算
在多线程系统中,过多的同步会增加调度开销。如下对比同步与异步递增 1 万次的性能:
with d2l.Benchmark('synchronous'):
for _ in range(10000):
y = x + 1
y.wait_to_read()
with d2l.Benchmark('asynchronous'):
for _ in range(10000):
y = x + 1
npx.waitall()
结果:
synchronous: 3.1623 sec
asynchronous: 0.9288 sec
原理如图 13.2.3 所示:前端提交任务,后端执行计算,并异步返回结果。异步执行显著减少了等待时间。
13.2.4 小结
-
深度学习框架通过前后端架构支持异步并行计算;
-
异步提升了响应速度,但要注意内存消耗和任务积压;
-
同步操作应谨慎使用,避免频繁数据拷贝带来性能下降;
-
建议每个 minibatch 同步一次,以保持系统稳定;
-
可借助硬件厂商的分析工具获得更细粒度的性能洞察。
13.2.5 练习
-
在 CPU 上运行本节代码,是否还能观察到异步行为?
-
修改 waitall 和 wait_to_read 的调用频率,验证其对性能的影响。
-
模拟更大计算图,观察同步操作对整体效率的影响。
📘 理论理解:为什么要异步计算?
现代计算资源(CPU/GPU)高度并行,但 Python 是单线程的,不能天然发挥多核设备的最大效率。深度学习中很多操作(比如 GPU 上的矩阵乘法)计算代价大,如果我们总是等待一个操作完成再进行下一个,整个 pipeline 会阻塞,导致显卡等硬件资源闲置,严重浪费吞吐能力。
异步计算的核心目标就是:前端指令快速返回,把任务扔给后端队列执行,让前端可以继续做别的事。这种机制本质上类似于操作系统中的“非阻塞 I/O”思想。
举个例子:
z = x * y + 2
print(z)
在 PyTorch 中,x * y + 2 的计算会放入后端 GPU 的任务队列,前端不会立刻等它完成。只有到 print(z) 这样的操作时,系统才会同步等待结果返回。这种机制允许多个 GPU 并发跑不同任务,前端也不被计算阻塞,大大提升了系统的并发能力和吞吐效率。
💼 大厂实战理解:异步计算在工程中的具体应用
在工业级深度学习训练系统中(如字节跳动的飞桨、腾讯的 Angel、NVIDIA 的 Megatron),异步机制不仅仅体现在一个 GPU 任务调度上,而是:
-
数据加载与预处理异步:使用多线程 DataLoader,不阻塞训练主线程。
-
多 GPU 训练异步调度:通过 NCCL 或 Horovod,实现梯度的异步 AllReduce。
-
模型推理异步化:在 TensorRT、ONNX Runtime 等推理引擎中,通过异步张量计算提高 QPS。
例如在 Google 的 TensorFlow 中,当你写:
@tf.function
def train_step():
...
背后实际上是构建一个静态图(符号式 + 异步执行),由 XLA 编译器将操作并行化并异步调度,从而最大限度压榨 TPU/GPU 资源。而 PyTorch 自 1.5 开始也引入了 torch.jit.script 和 torch.cuda.Stream 机制,进一步释放异步编程能力。
🚦 工程建议
-
避免频繁
.item()或.numpy()操作:它们会强制 GPU 同步,打断异步流; -
尽量使用异步数据加载器、异步显存调度器;
-
每个 minibatch 后调用
torch.cuda.synchronize()可控制同步点; -
监控任务队列长度:避免队列过长导致 OOM,可用 NVIDIA Nsight 查看。
💼 大厂面试题 · 异步计算篇
✅ 一、基础概念题
Q1. 什么是异步计算?它在深度学习框架中如何体现?
答:
异步计算是指操作在调用后并不会立即完成,而是将任务放入执行队列,主线程继续向下执行,其结果在后续需要时才同步获取。在深度学习中,如 PyTorch 或 TensorFlow,很多 GPU 操作(如张量乘法)默认是异步的,只有在执行如 .item()、.numpy() 或 print() 等需要 CPU 结果时才会同步。
Q2. PyTorch 中哪些操作会触发 GPU 与 CPU 同步?
答:
-
.item() -
.numpy() -
print(tensor) -
tensor.tolist() -
DataLoader的pin_memory=True时将数据拷贝回 CPU -
显式调用
torch.cuda.synchronize()
这些操作都会等待 GPU 当前队列中的所有计算完成,从而形成同步点,阻塞主线程。
✅ 二、工程原理题
Q3. 异步计算如何提升 GPU 资源利用率?
答:
GPU 是高度并行的计算设备,但如果每次操作都阻塞前端,GPU 的并发执行能力会被浪费。异步计算通过将任务排入队列、释放主线程控制权,使得多个任务可以并行执行,减少等待和空闲,从而提升吞吐量和整体利用率。
Q4. 如何在 PyTorch 中实现多 Stream 异步并发执行?
答:
使用 torch.cuda.Stream() 可以构建多个 CUDA 流,实现在一个 GPU 上的并发任务调度。例如:
s1 = torch.cuda.Stream()
s2 = torch.cuda.Stream()
with torch.cuda.stream(s1):
a = torch.randn(1000, device='cuda') * 2
with torch.cuda.stream(s2):
b = torch.randn(1000, device='cuda') + 3
两个计算任务分别在两个流中调度,避免互相阻塞。
✅ 三、故障排查题
Q5. 某深度学习训练程序 GPU 利用率很低,但无报错,请问可能原因?
答:
可能原因包括:
-
每一步训练都包含
.item()或print(),强制同步导致吞吐低; -
DataLoader未设置num_workers > 0,导致数据加载阻塞主线程; -
未使用混合精度训练,造成显存使用效率低;
-
未使用多流(Stream)或显式同步点控制 GPU 并发性。
✅ 四、开放题 / 场景类
Q6. 假设你在优化一个实时推理服务,推理时间波动大,QPS 不稳定。你会考虑异步计算优化吗?如何做?
答:
是的,可以通过引入异步机制稳定推理性能:
-
使用
torch.jit.script或ONNX Runtime等引擎提前编译模型; -
利用异步推理队列处理多个请求;
-
在 GPU 上使用多个 Stream 并发处理不同请求;
-
异步加载数据和处理输出,避免阻塞主线程;
-
控制同步点位置(例如延迟
.item()),减少等待。
✅ 总结
| 维度 | 理论原理 | 工程实战 |
|---|---|---|
| 意义 | 解耦计算与控制流,释放硬件并行能力 | 提高 GPU 利用率,降低内存等待时间 |
| 实现 | 前端指令立即返回,后端排队异步执行 | 动态图框架中自动调度计算任务 |
| 典型应用 | 矩阵乘法、深度网络前向传播 | 训练、推理、梯度同步、模型并行 |
异步计算不仅是一种框架底层的优化,更是现代深度学习工程不可或缺的一环。掌握它,才能真正发挥硬件潜力,构建高吞吐、低延迟的 AI 系统。
💡 大厂场景题 · 异步计算篇(13.2)
🎯 场景题 1:异步引发训练性能抖动
背景:
你所在的团队在训练一个高精度目标检测模型,部署于单张 A100 GPU 上。训练过程中的 GPU 利用率在 35%~99% 间波动很大,训练吞吐量不稳定。模型没有报错,工程代码中使用了 .item() 获取每个 batch 的 loss 值用于日志打印。
问题:
-
请分析可能的原因;
-
如何通过异步计算相关优化手段解决该问题?
参考答案:
-
原因分析:
-
.item()是一个同步操作,会触发 GPU → CPU 的阻塞,等待所有 CUDA 操作完成。 -
每 batch 使用
.item()频繁同步,主线程等待 GPU 队列执行完毕,破坏异步流水线,导致 GPU 空闲时间增加; -
GPU 利用率抖动即反映了同步点造成的执行不连续。
-
-
优化方案:
-
✅ 改用
loss.detach()存储或延后调用.item(),将同步频率从每 step 减为每 epoch; -
✅ 在训练日志中异步记录 loss,可结合
torch.no_grad()+detach().cpu().numpy(); -
✅ 使用
torch.cuda.synchronize()明确同步位置,避免意外同步点; -
✅ 如果使用多个模型或分支结构,考虑多 CUDA Stream 并发加速;
-
✅ 使用 Profiler(如
torch.profiler.profile)确认瓶颈是否在 GPU–CPU 数据同步阶段。
-
🎯 场景题 2:部署延迟不稳定问题
背景:
公司某推荐系统模型部署上线后,在线推理接口出现请求响应时间波动,有时在 10ms 内,有时超过 100ms。模型是 PyTorch 导出、部署在 GPU 上的 Flask API 服务。
问题:
-
哪些异步计算相关机制可能引发这种不稳定?
-
如何改进部署策略以稳定响应时间?
参考答案:
-
可能原因:
-
推理流程未控制同步点,
.numpy()等操作随机出现在不同位置,打乱 CUDA 执行顺序; -
多个请求未使用独立 CUDA Stream,彼此阻塞;
-
GPU 上有其他任务打断当前 CUDA 流,或者主线程存在 I/O 阻塞;
-
CPU 数据预处理或模型输出强制转换过早导致 GPU → CPU 同步过早;
-
Batch 推理粒度不稳定,影响执行时间。
-
-
优化方案:
-
✅ 用
torch.cuda.Stream()为不同请求配置独立流; -
✅ 控制
.numpy()出现在所有 CUDA 操作完成之后; -
✅ 在 Flask 中引入线程池/异步任务队列(如 Celery + Redis)隔离推理任务;
-
✅ 将预处理和后处理尽量放在 GPU 中完成,减少 GPU–CPU 往返;
-
✅ 若为高并发场景,引入 TensorRT + ONNX Runtime 部署,提升异步执行调度能力。
-
🎯 场景题 3:异步训练日志系统设计
背景:
你在负责设计一个多 GPU 异步训练的监控系统,需要记录每秒钟的训练损失(loss)变化图,同时不能影响模型训练速度。
问题:
-
请设计一种既能实时记录 loss,又不干扰训练异步机制的方案。
参考答案:
-
基本思路:
-
不在训练主线程中使用
.item(); -
构建独立日志线程异步收集数据;
-
利用
.detach()+cpu()+ 队列传输 loss。
-
-
实现策略:
import threading, queue
loss_queue = queue.Queue()
def log_writer():
while True:
if not loss_queue.empty():
log_item = loss_queue.get()
# 写入 CSV/绘图/数据库等
print(f"[LOG] {log_item}")
threading.Thread(target=log_writer, daemon=True).start()
# 训练中
for batch in data_loader:
...
loss = criterion(output, target)
loss_queue.put(loss.detach().cpu().item())
-
优点:
-
保证主线程不阻塞;
-
不破坏异步流水线;
-
可拓展为异步监控图或 Prometheus 插件等。
-



















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











