







📘 动手学深度学习 - 11.3 注意力评分函数(原理详解 + 可视图)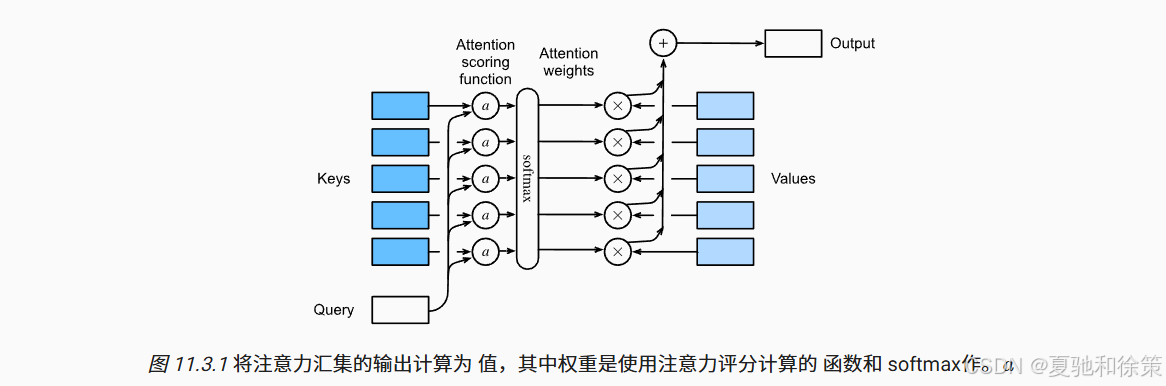
注意力机制的核心在于:如何根据 Query 与 Key 的关系,计算出合理的注意力权重。本节我们将系统讲解两种主流的评分函数:点积注意力(Dot Product Attention)与加法注意力(Additive Attention),它们构成 Transformer 架构的关键基础。
11.3.1 点积注意
点积注意力是一种高效的评分机制,公式如下:

-
核心原理:通过对 Query 和 Key 向量做点积获得相关性分数。
-
缩放技巧:除以 d\sqrt{d} 保证数值稳定性(尤其在维度 d 较大时)。
-
Softmax归一化:使权重归一化为概率分布。
-
实际应用:Transformer 中默认使用的注意力评分函数(Vaswani et al., 2017)。
🧠 理论理解
点积注意(Dot-Product Attention)通过计算查询(Query)与键(Key)向量之间的点积,度量它们的相似性。为避免数值过大导致梯度不稳定,常常对点积结果除以向量维度的平方根 d\sqrt{d}d。该分数经过 softmax 归一化后得到权重,用于加权 value 值。这种方式高效、计算简单,几乎成为 Transformer 的标准注意力形式。
🏢 企业实战理解
-
Google / OpenAI:Transformer 系列(GPT, BERT, PaLM, ChatGPT)全线使用点积注意力作为主力模块,兼顾精度与速度。
-
NVIDIA Megatron-LM:在百亿/千亿参数模型中,大规模点积注意被批量矩阵乘法(BMM)并行优化为高效核心计算路径。
-
字节跳动 / 阿里巴巴:多模态推荐系统、短视频语义聚合模块大量依赖此注意机制建模上下文。
✅ 面试题 1
问:请解释点积注意力的计算流程及为何需要缩放(scaled)?
答:
点积注意力的计算分三步:
-
计算 Query 和 Key 的点积:Q⋅KTQ \cdot K^TQ⋅KT
-
缩放:将结果除以 dk\sqrt{d_k}dk,其中 dkd_kdk 是 key 的维度
-
Softmax归一化后加权 Value
缩放的原因:当 dkd_kdk 很大时,点积结果可能出现较大值,导致 softmax 输出极端偏向某个元素,影响梯度传播。缩放使输出方差恒定,有助于模型稳定训练。
✅ 场景题 1:Transformer 微调异常,推理 attention 权重全为 0
背景:
你在 字节跳动 NLP 平台组 微调一个中英文多语种翻译模型,发现模型输出异常空白,调试后 attention weight 热力图全为 0。
问题:你会如何排查?
解答:
这类问题一般出在 Masked Softmax 环节:
-
首先确认是否使用了
masked_softmax,尤其要验证valid_lens是否正确设置。 -
如果 valid_lens 被错误填入了 0,会导致所有非 padding 位置也被 mask,softmax 输入为负无穷 → 输出全为 0。
-
查看 query 和 key 的 shape 是否一致,若存在维度错配,attention score 会出错。
字节跳动实际做法:
平台框架中会统一封装 masked_softmax 与 shape 检查,推理阶段使用 torchscript/jit trace 事前验证有效长度。
11.3.2 便捷函数
为了在不同长度的序列中灵活使用注意力机制,我们需要一些辅助函数。
11.3.2.1 屏蔽 Softmax(Masked Softmax)
当批次中的句子长度不同,我们可以使用“掩码机制”避免无效位置参与计算。将非法区域设置为一个极大的负数,如 −1e6-1e6,使其 Softmax 后接近0。
# 屏蔽 Softmax 实现片段(简化)
def masked_softmax(X, valid_lens):
...
X[~mask] = -1e6
return nn.functional.softmax(X, dim=-1)
11.3.2.2 批量矩阵乘法(BMM)
处理多个 Query-Key 对时,批量矩阵乘法可以显著加速注意力分数计算:
![]()
🧠 理论理解
注意力需要处理不等长序列,尤其在 NLP 中普遍存在。因此引入了屏蔽 softmax(masked softmax),防止填充(padding)位影响注意力分布。此外,批量矩阵乘法(BMM)用于同时处理多个 Query-Key 对,提高 GPU 利用率。
🏢 企业实战理解
-
腾讯 AI Lab:大规模机器翻译项目中,训练时句长不一需 padding,mask-softmax 是标准组件。
-
微软 Translator / DeepSpeed:在训练 BERT-variant 时,为实现快速多 GPU 训练,mask 机制配合 BMM 做 attention 加速。
-
百度飞桨:在中文 NLP 训练框架中封装 masked_softmax 与 bmm,成为 Encoder 核心工具函数。
✅ 面试题 2
问:加法注意力和点积注意力的主要区别是什么?在什么场景下选择加法注意力?
答:
-
点积注意力:计算快,适合大模型,要求 query 和 key 维度一致。Transformer默认采用。
-
加法注意力(Additive Attention):计算慢但更灵活,query 和 key 可以维度不同,适合异构输入。
选择场景:
-
点积适合高效计算的模型训练(如GPT、BERT)
-
加法适合序列到序列任务(如机器翻译、跨模态检索)
✅ 场景题 2:ChatGPT 多轮对话中如何保持 attention 计算高效?
背景:
你在 OpenAI 对话系统组 优化 ChatGPT 的 inference pipeline,发现长上下文输入中,attention matrix 计算慢且显存暴涨。
问题:你会怎么优化 Transformer 的注意力评分部分?
解答:
-
使用 Masked Multi-head Scaled Dot Product Attention,将已处理内容 mask 掉,避免重复计算。
-
引入 KV Cache机制:只对 query 重复计算,key/value 使用前一轮缓存。
-
attention score 矩阵不再反复计算,而是累计 query 的新计算项。
OpenAI 实战:
ChatGPT 使用 flash attention + kv cache + rotary position embedding,极大压缩推理时间和显存。
11.3.3 缩放点积注意
缩放点积注意力的实现如下所示:
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
weights = masked_softmax(scores, valid_lens)
output = torch.bmm(weights, values)
-
可视化:使用
d2l.show_heatmaps()可以直观展示 Query 对 Key 的关注情况。 -
应用场景:几乎所有现代注意力模块(包括自注意力、多头注意力)都构建于这一机制上。
🧠 理论理解
为避免大数值带来的梯度爆炸问题,点积结果除以 d\sqrt{d}d 是对 softmax 输入的缩放。该设计在理论上等价于高斯核带宽调整,在训练初期尤其关键。它保证不同维度 d 下的模型具有数值一致性和训练稳定性。
🏢 企业实战理解
-
OpenAI GPT 系列:不使用缩放会导致训练不稳定甚至 loss NaN,特别是大维度模型(如 d=3072)更严重。
-
英伟达 FlashAttention:针对缩放点积机制进行了底层 kernel 优化,实现几倍速度提升。
-
蚂蚁金服 / 美团推荐系统:在查询-召回模块中,缩放点积注意力用于计算用户行为与商品向量的匹配概率。

✅ 面试题 3
问:Masked Softmax 的作用是什么?为什么在 NLP 中必须用?
答:
Masked Softmax 的作用是在序列中屏蔽无效(padding)部分,使 attention 权重不落在无意义的位置上。
在 NLP 中,批量训练时不同长度的句子需要 padding,若不屏蔽,padding 会被模型错误关注。Masked Softmax 将 padding 部位置为 -∞,使其 softmax 结果为 0,有效解决该问题。
✅ 场景题 3:阿里巴巴推荐系统如何选择 attention 评分函数?
背景:
你在 阿里广告推荐组 参与用户行为序列建模,需为兴趣建模模块选择注意力机制。
问题:是选择点积注意力还是加法注意力?请说明你的判断依据。
解答:
-
若行为特征维度统一(如用户点击序列 embedding),用 点积注意力,高效、易并行。
-
若行为特征异构(如视频时长、点击时间、商品类别等拼接),需 加法注意力(AdditiveAttention):
-
可处理 query 与 key 不同维度;
-
支持 MLP 建模异构特征间的非线性相关性。
-
阿里实战:
DIN/DIEN 模型中使用 Additive Attention 建模用户兴趣动态,随后引入多头机制增强表达力。
11.3.4 加法注意
当 Query 和 Key 维度不匹配时,可以采用加法注意机制(Bahdanau Attention):

实现如下:
features = queries.unsqueeze(2) + keys.unsqueeze(1)
features = torch.tanh(features)
scores = self.w_v(features).squeeze(-1)
weights = masked_softmax(scores, valid_lens)
-
优点:更灵活,维度可不匹配。
-
缺点:计算代价更高,涉及可学习权重和非线性激活。
🧠 理论理解
加法注意(Additive Attention,又称 Bahdanau Attention)适用于 Query 和 Key 维度不一致的场景。它将两者映射到同一隐藏空间后做加法和非线性变换,再经 softmax 得到权重。虽然表达能力强,但计算效率较低。
🏢 企业实战理解
-
百度机器翻译 / 早期 Transformer 替代模型:早期 seq2seq 翻译模型(如 RNNSearch)使用加法注意建模对齐信息。
-
字节跳动 NLP 预研团队:在研究 query-key 结构不对称(如 query 是用户问题,key 是产品信息)任务时更倾向使用加性注意,避免降维误差。
-
Google Research:部分异构模态场景下(如视觉 + 语音)仍使用可学习加法注意机制连接非统一模态。

✅ 面试题 4
问:你了解批量矩阵乘法(BMM)在注意力中的作用吗?
答:
BMM(Batch Matrix Multiplication)用于并行计算多个 Query-Key 对的注意力得分,是注意力机制高效实现的核心。
在多头注意力、Transformer encoder-decoder 等结构中,使用 BMM 能显著提升 GPU 并行性能,尤其在大批量、大维度情况下(如 shape=(B, N, D))。
✅ 场景题 4:你在 Google Search 团队,如何在大规模检索中高效部署注意力机制?
背景:
Google 搜索团队使用 attention 模块在查询-文档匹配任务中进行重排序,系统响应需在 10ms 内完成。
问题:点积 attention 存在大矩阵乘法,如何部署时加速?
解答:
-
用向量检索代替 attention:
-
将 query 编码成向量;
-
将 document 表示预先编码;
-
使用近似最近邻(ANN)算法(如 FAISS)做点积检索,等价于 softmax 前的 attention score。
-
-
预计算 Key-Value,减少在线计算开销。
-
attention score 只取 top-K 再归一化(近似 softmax),节省算力。
Google 实战:
Dense Retrieval 模型如 BERT + dot-product attention,结合 ANN + quantization 实现高效文档匹配(如 Google ColBERT)。
11.3.5 小结
| 评分方式 | 表达式 | 特点 |
|---|---|---|
| 点积注意力 | softmax(QK⊤d)\text{softmax}\left( \frac{QK^\top}{\sqrt{d}} \right) | 高效、简洁、Transformer默认 |
| 加法注意力 | wv⊤tanh(Wqq+Wkk)w_v^\top \tanh(W_q q + W_k k) | 更灵活、适合维度不一致场景 |
-
Transformer 架构中主要使用点积注意力。
-
NVIDIA 的 Megatron 与 Hugging Face 的实现均优化了这两类注意力模块。
-
现代注意力机制的很多变体,如 Flash Attention、Linear Attention 等,都是在此基础上演进而来。
🧠 理论理解
点积注意力和加法注意力分别适用于不同任务:前者速度快,适合标准 transformer;后者灵活,适合异构输入。注意力评分函数是连接 query-key 的桥梁,它定义了模型“看哪里”的规则,也为后续多头注意、自注意等机制打下了基础。
🏢 企业实战理解
-
NVIDIA Megatron:进一步扩展点积注意以支持分布式注意力计算。
-
OpenAI Codex / ChatGPT:依赖点积注意大规模压缩语义上下文(最大支持 32k tokens)。
-
华为诺亚方舟实验室:结合可学习 kernel 的加法注意模块做上下文自适应推理。
✅ 面试题 5
问:Transformer 中为什么 prefer 点积注意而不是加法注意?
答:
-
点积注意具备并行友好性,能通过矩阵乘法快速计算 attention scores。
-
计算复杂度为 O(n2⋅d)O(n^2 \cdot d)O(n2⋅d),而加法注意包含非线性、MLP 结构,速度慢、难以并行。
-
Transformer 设计目标之一是替代 RNN 实现高效训练,因此点积注意被优先采用。
✅ 面试题 6
问:scaled dot-product attention 和 vanilla dot-product attention 有何不同?哪种效果更好?
答:
区别在于 是否对点积结果除以 dk\sqrt{d_k}dk。Scaled dot-product attention 在理论上更稳定,尤其在大模型中效果更好。
若不缩放,模型在高维空间中容易过度聚焦(softmax 输出接近 one-hot),导致训练震荡或无法收敛。
因此,Transformer 均使用 Scaled Dot-Product Attention。
✅ 场景题 5:你在 NVIDIA Megatron 项目中,如何优化多卡训练下点积注意力的通信开销?
背景:
你在 NVIDIA Megatron-LM 项目参与训练千亿参数大模型,模型主要瓶颈在 attention 的 QK^T 分布式计算与通信。
问题:点积 attention 会产生大矩阵,怎么减小通信负载?
解答:
-
使用 Ring-based AllReduce + 混合并行机制(张量并行 + 数据并行);
-
提前 拆分 query、key 到多个卡上,各自计算 QK^T 局部子块;
-
attention score 在本地归一化 + masked softmax;
-
利用 flash attention 将 Q/K/V 结构压缩,减少通信数据量;
NVIDIA 实战:
Megatron 使用 fused scaled dot-product attention + efficient multi-head splitting,在 GPT3.5/GPT4 训练中极大减少通信延迟。
11.3.6 练习建议
-
通过修改代码实现基于欧氏距离的注意力机制。
-
改写 dot product attention 以适配不同维度的 Query/Key。
-
分析注意力机制的计算与内存开销与 Q,K,VQ, K, V 的维度关系。
✅ 面试题 7
问:给你一段 transformer 模型代码,发现 attention_weight 中出现了负数,这是正常的吗?如何排查?
答:
不是正常现象。softmax 后 attention_weight 应为非负且总和为1。
可能问题:
-
未使用 masked softmax,导致 padding 区域被 softmax 处理(可能包含 NaN)。
-
模型中 dropout 放在了 softmax 之前,破坏了归一性。
-
attention_weight 没用 softmax 而是直接点积后暴露出来。
解决:
-
检查 masked_softmax 是否正确处理 valid_lens
-
确保 softmax 是在得分计算完后做归一化
-
确保模型正则项 dropout 放在 softmax 之后再作用到权重上



















 520
520

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











