




🧠 吴恩达机器学习 - 监督学习
“学习的本质,是从已知中预测未知。”
—— 从吴恩达课程走进机器学习的第一步
前言:大家要想看理论部分可以看我之前的博客:李航统计学习方法
🧭 一、什么是监督学习?
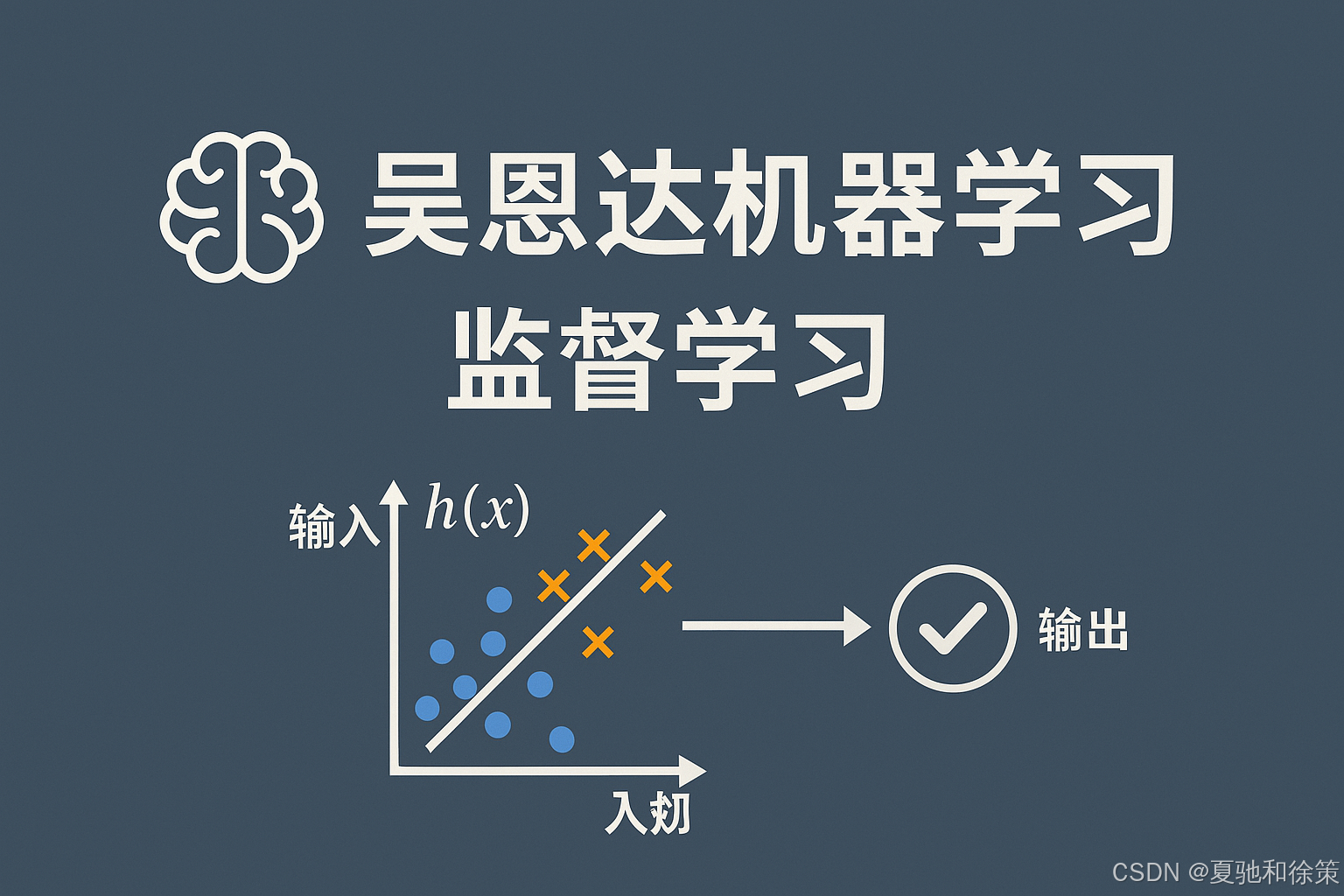
在机器学习的世界里,监督学习(Supervised Learning)是我们踏入智能预测的第一道大门。它的核心思想非常简单:
给定输入和输出样本,通过学习,建立一个能够对新输入做出预测的模型。
更直白一点:
就像教一个孩子识字,我们告诉他“这个是‘狗’、那个是‘猫’”,教多了,他就能自己看图说话。
在数学形式上,我们拥有一个训练数据集:
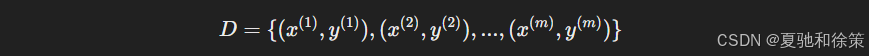
我们要学习一个函数 $h_\theta(x)$,让它能尽可能接近真实输出 $y$。
🧩 二、监督学习的两大任务类型
1. 回归(Regression)
-
目标:预测一个连续值
-
典型应用:房价预测、温度预测、销售额预测
-
常见模型:线性回归、多项式回归
公式示意:
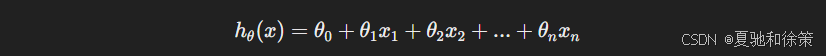
✅ 例子:根据面积、楼层预测房子的价格
2. 分类(Classification)
-
目标:预测一个离散类别
-
典型应用:垃圾邮件识别、猫狗识别、肿瘤良恶性分类
-
常见模型:逻辑回归、决策树、K近邻、支持向量机(SVM)
逻辑回归示意:
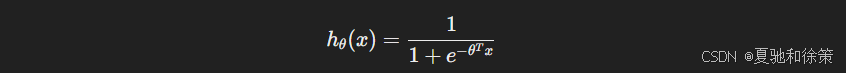
✅ 例子:预测一封邮件是否为垃圾邮件(1表示垃圾,0表示正常)
🧠 三、学习的本质:从误差中优化
我们要想办法让 $h_\theta(x)$ 预测得越来越准,这就是“学习”的过程。
📉 损失函数(Cost Function)
它衡量我们模型有多“蠢”。
例如在线性回归中,常用的是均方误差(MSE):
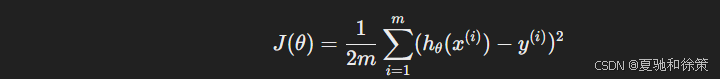
逻辑回归使用的是交叉熵损失(更适合概率问题):
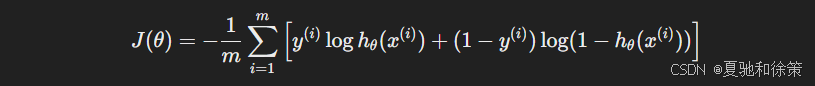
🧮 优化器:梯度下降(Gradient Descent)
最常见的优化方法是梯度下降。
它就像是爬山时不断朝最低处走,每一步都靠当前梯度方向更新参数:
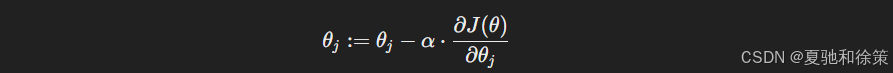
-
$\alpha$ 是学习率,控制我们每一步走多远
-
不断迭代,直到损失函数降到最低
🎯 四、监督学习的实际应用
| 应用场景 | 任务类型 | 模型 | 输出 |
|---|---|---|---|
| 房价预测 | 回归 | 线性回归 | 连续数值(如 $350,000) |
| 邮件分类 | 分类 | 逻辑回归 | 0(正常) / 1(垃圾) |
| 图像识别 | 分类 | CNN(卷积神经网络) | 类别标签(猫/狗) |
| 疾病预测 | 分类 | 决策树 | 有病 / 没病 |
| 销售趋势预测 | 回归 | 多项式回归 | 连续变化的销售额 |
🧠 五、我的理解:监督学习是“编织规则的艺术”
站在“徐策”的角度看,它是一个构造因果链的过程。你定义变量、选择特征、建立逻辑关系,然后推演未来。
而在“夏驰”的世界里,它是一种行为映射建模,你试图用数据去模拟这个世界的反应机制。
现实世界没有答案,而监督学习中的数据给了我们确定性——这就是它的强大之处。
✅ 总结:监督学习就是教机器“看图说话”
-
有输入、有输出、有规则
-
训练 = 调整规则参数
-
最终目标 = 在未见过的新数据上做出准确判断
下一篇我将继续讲解“非监督学习”,那是让机器自己去“观察世界结构”的思维方式。
如果你觉得这篇文章有用,欢迎点赞、评论,或者分享给正在学习机器学习的朋友!



















 1274
1274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











