




🧠 吴恩达机器学习 - 非监督学习
“没有标签的世界,不是混乱,而是等待理解。”
—— 带你走进机器学习的“无人区探索”领域
🎯 一、非监督学习是什么?
非监督学习(Unsupervised Learning)是一类在没有标签的情况下学习数据结构的算法。
与监督学习不同,它不给你答案,你也不能问“正确的输出是多少”。它只给你数据。你要做的是:
从海量的无标签数据中,自动找出规律、模式、结构、分布。
这正是非监督学习的意义:
在无声的数据中听见秩序,在无标签的世界里重建逻辑。
🧩 二、非监督学习的主要任务
1. 聚类(Clustering)
任务描述:
自动将相似的样本归为一类,而无需任何预先定义的标签。
🧊 常用算法:K-Means 聚类
-
输入:无标签数据
-
输出:每个样本的簇编号
-
原理:找到 $K$ 个簇中心,最小化每个样本到其所属中心的距离
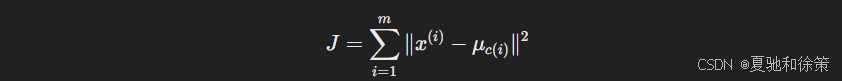
实际应用:
-
用户行为划分(电商推荐系统)
-
市场细分(CRM 精准营销)
-
文本聚类(新闻、评论自动归类)
🎯 小结:K-Means 是一个空间划分模型,让我们从混乱数据中“找边界”。
2. 降维(Dimensionality Reduction)
任务描述:
将高维数据压缩为低维表达,同时尽量保留有用信息。
🌌 常用算法:主成分分析(PCA)
-
原理:寻找最大方差方向,将数据投影到这些方向上
-
应用:数据可视化、特征压缩、噪声过滤
PCA 的目标是保留信息最密集的“主轴”,去除冗余维度,使学习更高效。
原始维度:2048 → 降维后:50
仍然保留 95% 的数据方差信息。
🎯 小结:PCA 帮你“看清楚”数据最重要的特征维度,是信息空间的“主旋律提取器”。
🔍 三、非监督学习能解决哪些问题?
| 场景 | 用途说明 |
|---|---|
| 电商用户分析 | 发现不同消费群体(聚类) |
| 图像压缩 | 保留清晰度同时减少存储成本(PCA) |
| 网络入侵检测 | 在无标签情况下识别异常行为(聚类+异常检测) |
| 文本主题建模 | 从海量文本中提取潜在主题(LDA 等) |
| 生物信息分析 | 基因表达数据聚类,辅助疾病发现 |
⚖️ 四、非监督 vs 监督学习
| 对比维度 | 监督学习 | 非监督学习 |
|---|---|---|
| 是否有标签 | ✅ 有(x, y) | ❌ 无(只有 x) |
| 学习目标 | 拟合输入 → 输出映射关系 | 探索结构、分布、相似性 |
| 输出形式 | 分类标签或连续数值 | 簇编号、主成分、嵌入表示等 |
| 学习方式 | 教学式(模仿、纠错) | 自学式(观察、感知、发现) |
| 应用核心 | 预测未来 | 洞察现在 |
🧠 五、我的理解:非监督学习的本质
这不仅是一种学习方式,更是一种思考方式。
-
它不是问:“正确答案是什么?”
-
而是问:“这堆数据内部有没有规律?有没有隐藏的结构?”
-
它教我们放下“被训练的思维”,用开放式的眼光去重新观察世界
🌀 换个角度来看:
-
聚类:是把世界划分片区,让不同现象归类
-
降维:是从混杂维度中提取最有用的信号
-
异常检测:是通过学习“正常”,从而识别“不同”
-
可视化:是把混沌变成结构,把高维变成直观
非监督学习,是机器对世界“主动理解”的第一步。
✅ 总结一句话:
非监督学习就是:在无标签中找结构、在混乱中找模式、在未知中重建逻辑。
如果你觉得这篇文章有帮助,欢迎点赞、评论或关注我,一起从“监督走向无监督”,从“模仿走向洞察”!
👉 下一篇我们将讲解“异常检测”或“聚类算法实战”,你想看哪一个?欢迎留言!



















 1230
1230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











