







 哈希表是一种数据结构,通过散列函数将关键字映射到地址,实现快速查找。冲突是不可避免的,处理方法包括开放地址法(线性探测、二次探测、伪随机探测)和链地址法。选择合适的散列函数和冲突解决策略能提高查找效率。
哈希表是一种数据结构,通过散列函数将关键字映射到地址,实现快速查找。冲突是不可避免的,处理方法包括开放地址法(线性探测、二次探测、伪随机探测)和链地址法。选择合适的散列函数和冲突解决策略能提高查找效率。


7.4.1 哈希表(散列表)的基本概念
7.4.1散列表的基本概念
介绍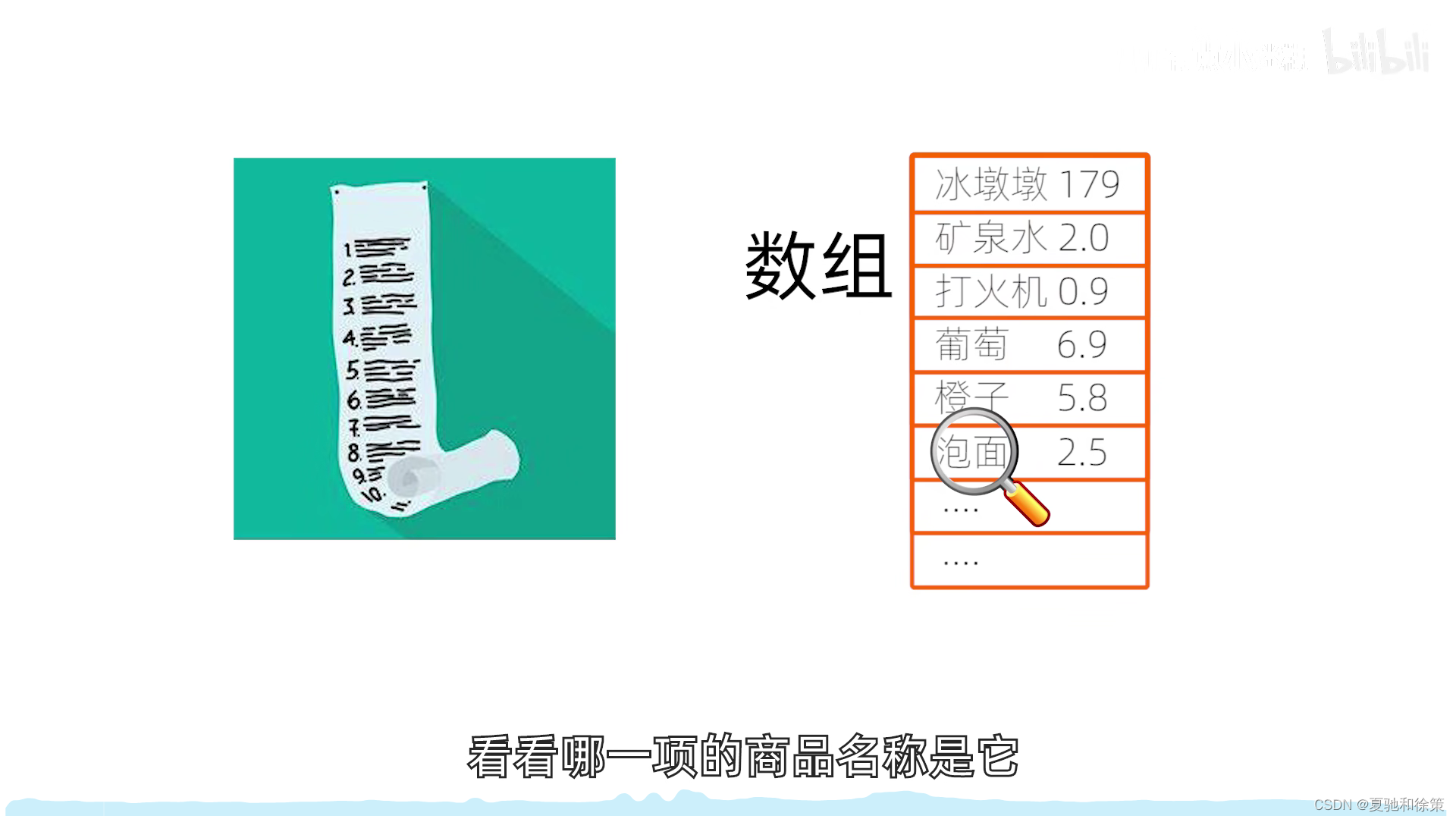
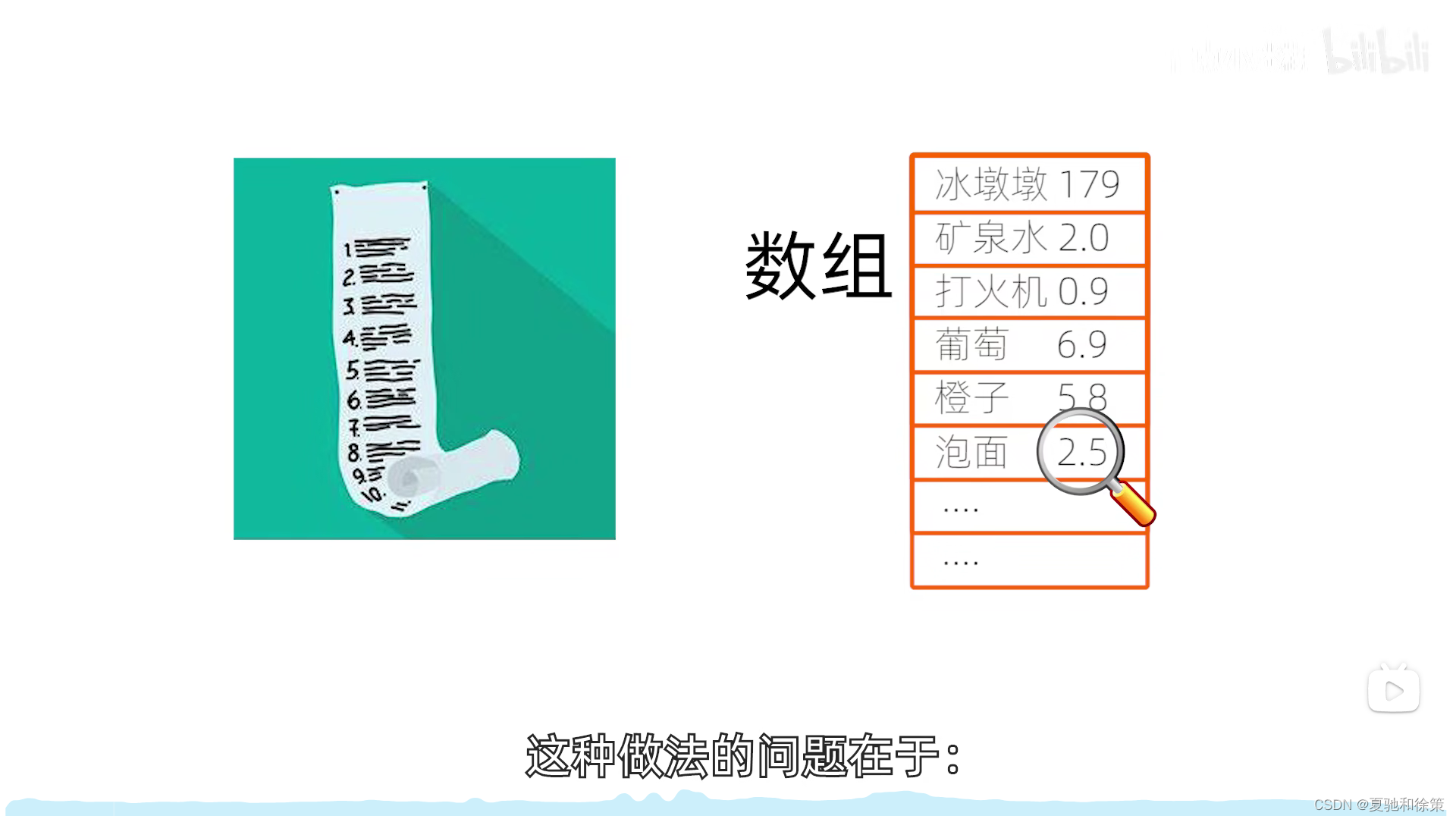
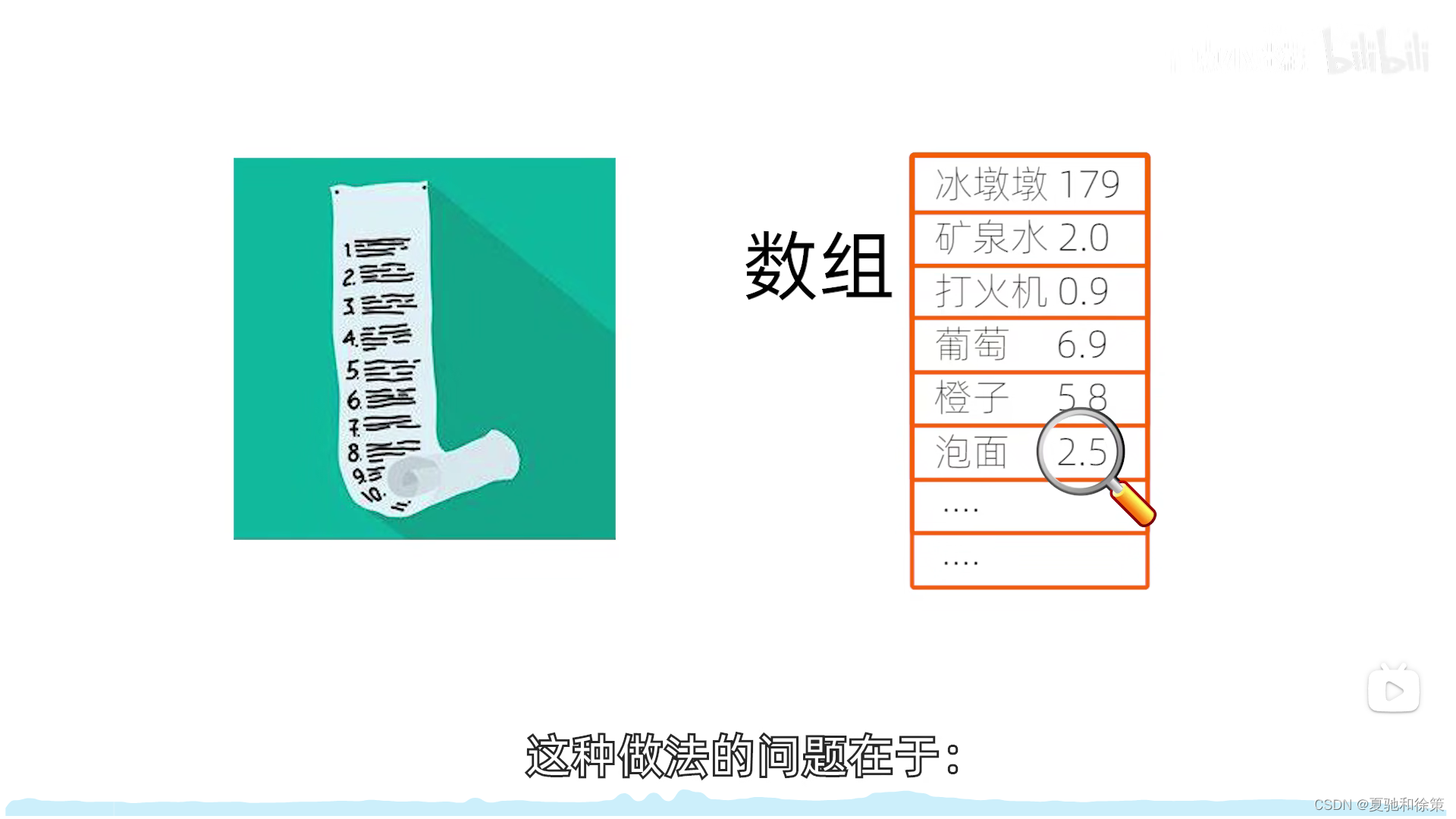
传统的查找方法,如线性表和树表结构,是基于关键字的比较进行的。这种方法常常需要大量的比较操作,尤其是当节点数量庞大时。为了加快查找速度,我们可以通过创建一个直接关系,将元素的关键字与其存储位置直接联系起来,从而大大减少查找时所需的比较次数。这种查找方法称为散列查找法,或叫杂凑法或散列法。
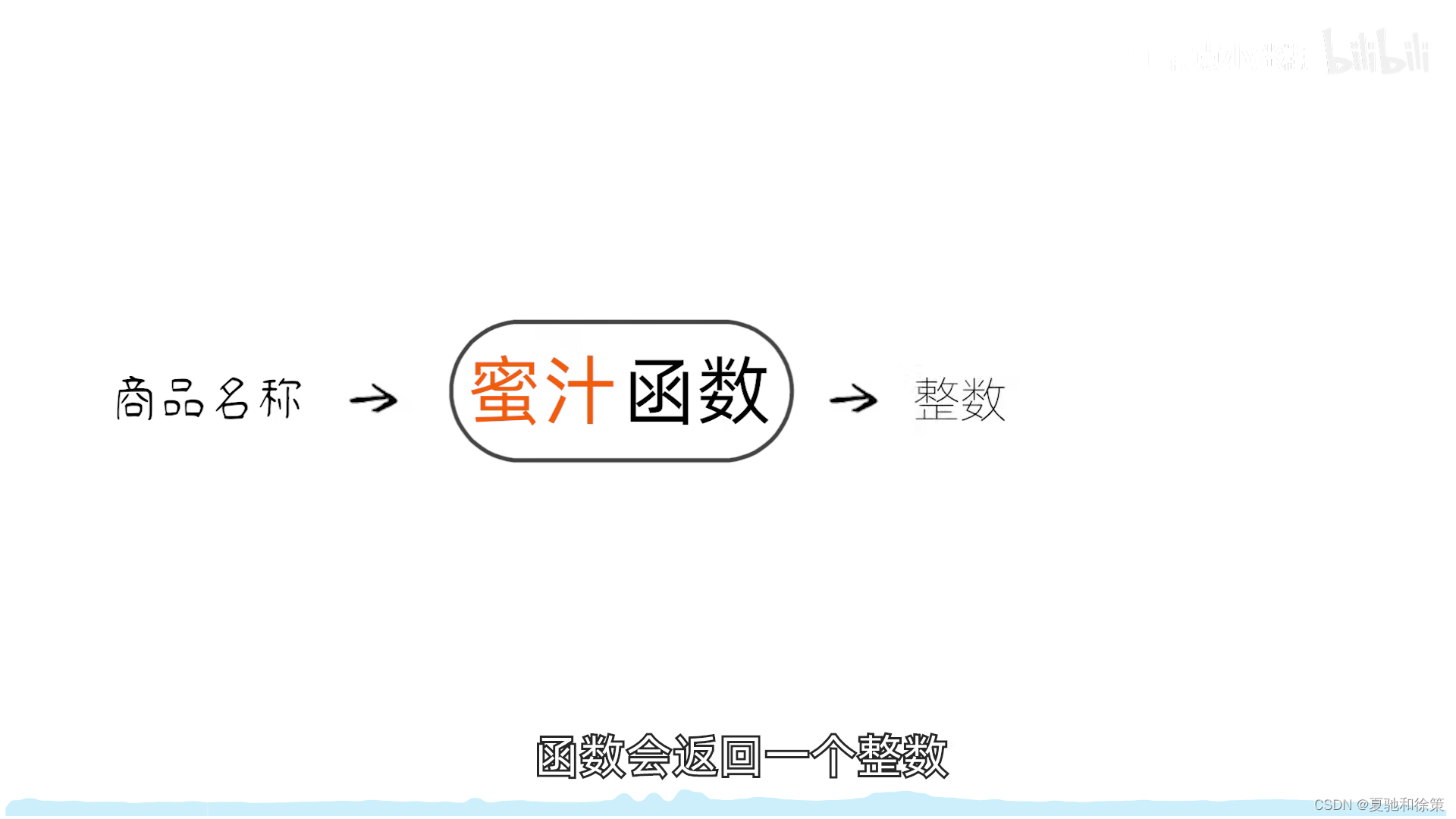
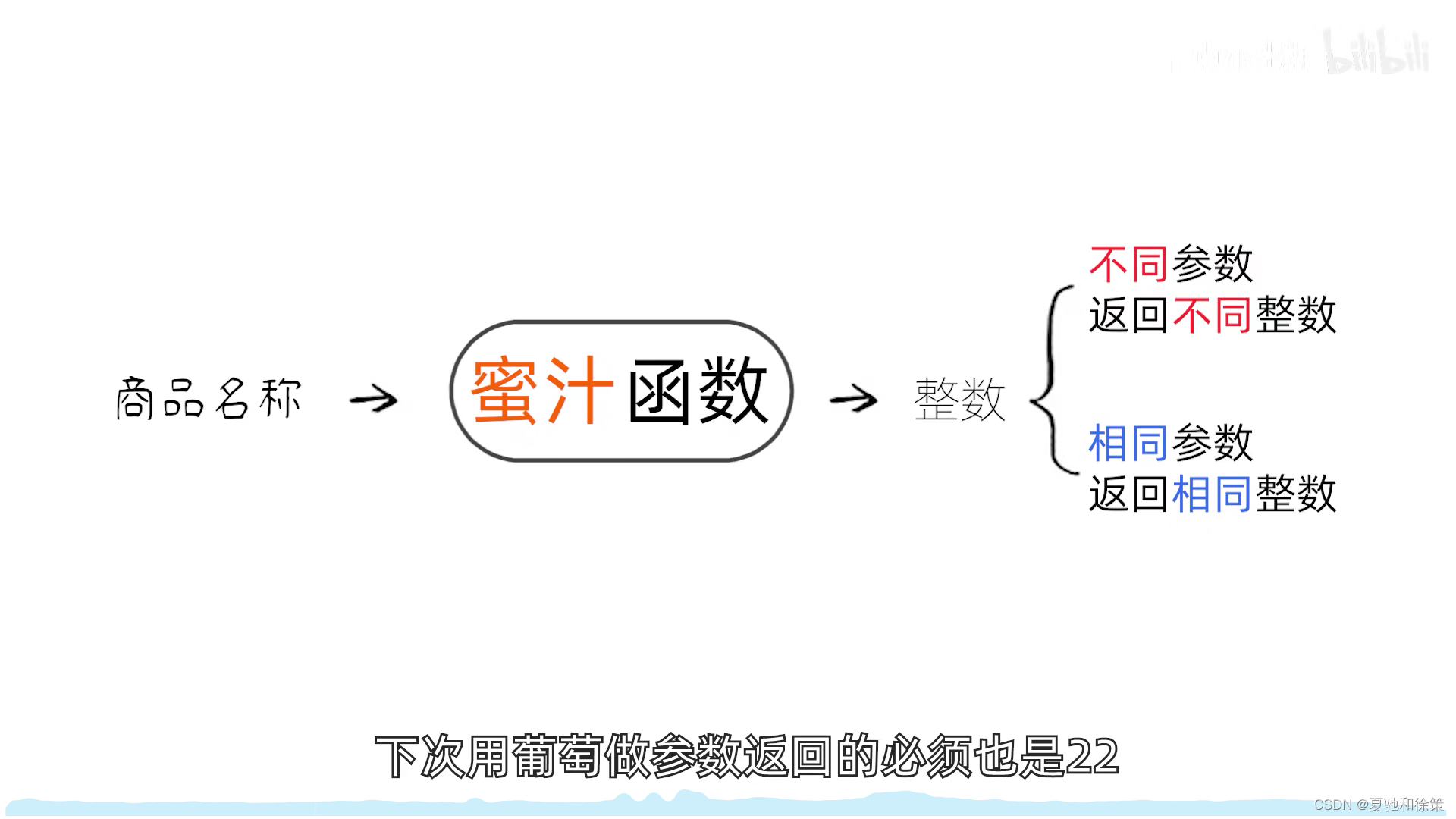
基本概念
1. 散列函数和散列地址
- 散列函数 (Hash Function): 一个将关键字与其存储位置直接关联的函数,标记为 H, 其中 p = H(key),p 是散列地址。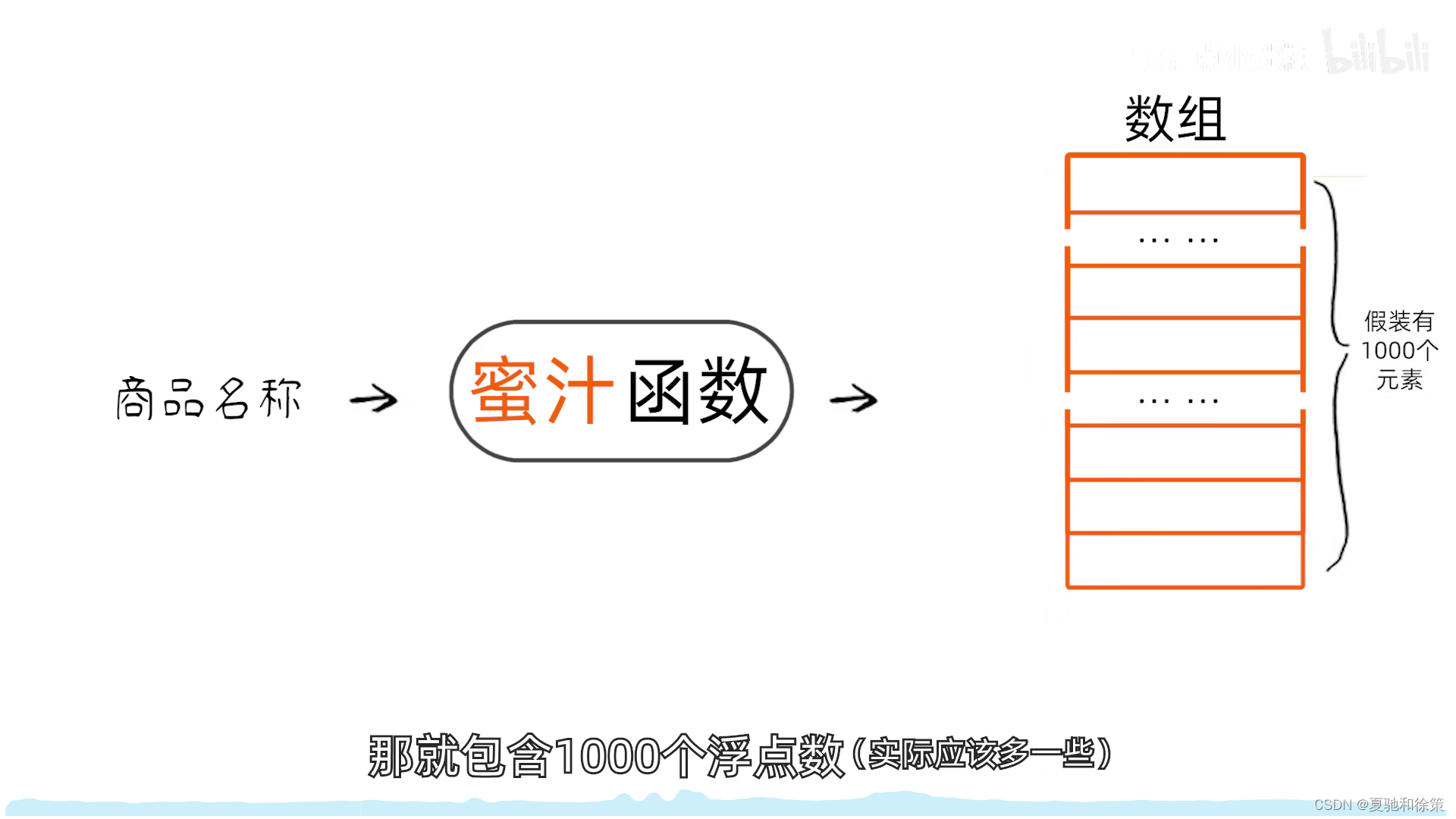
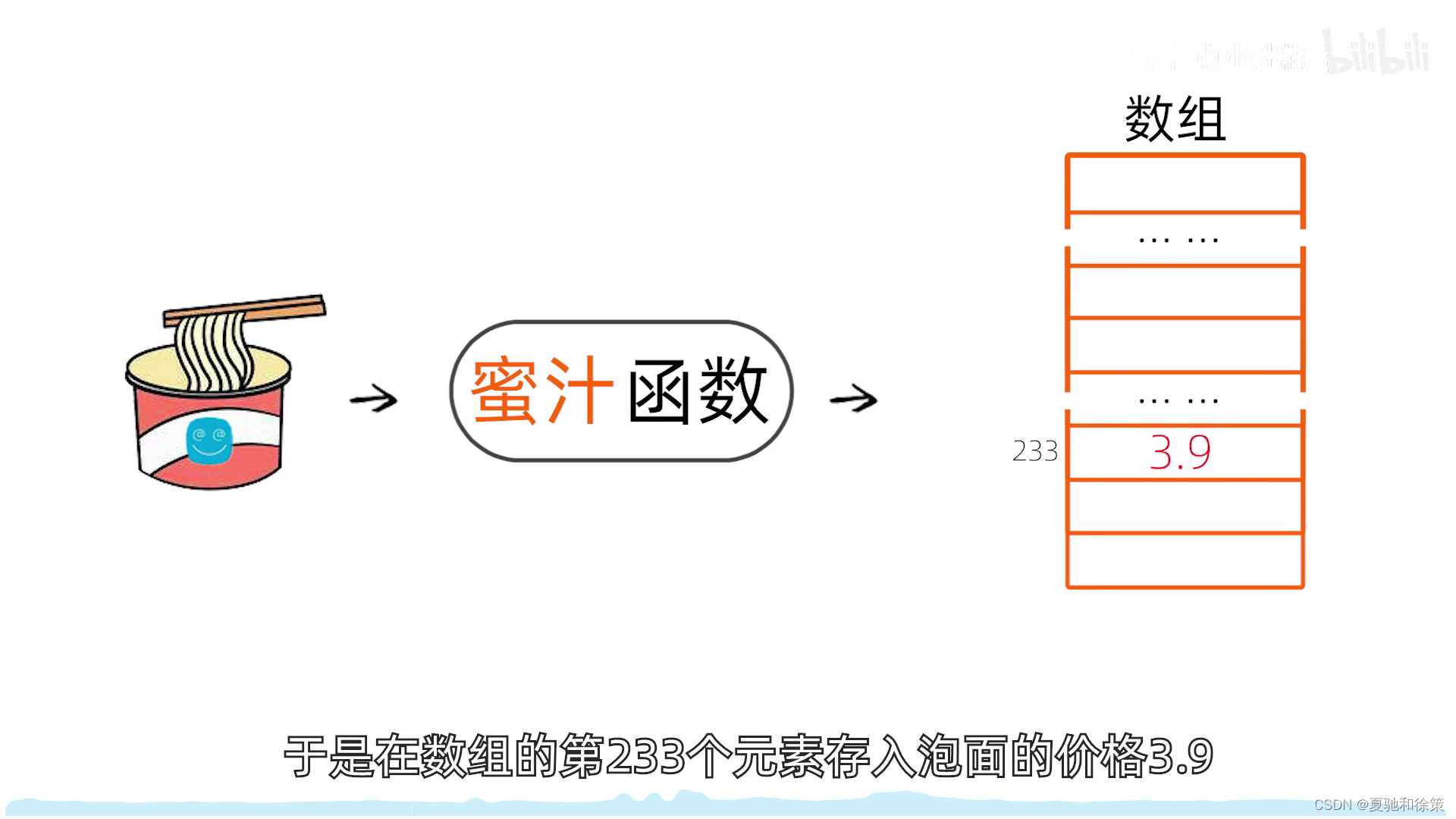
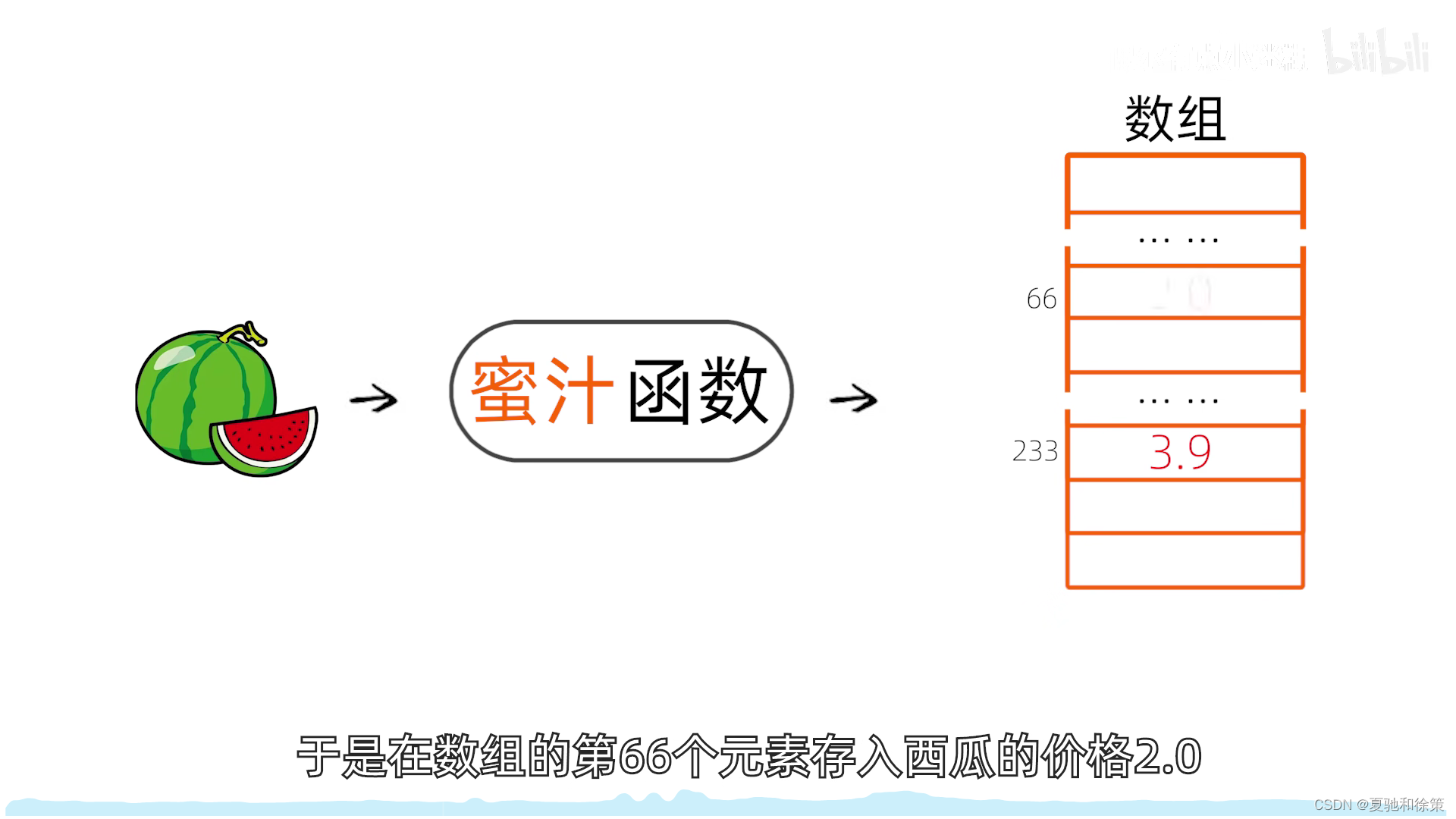
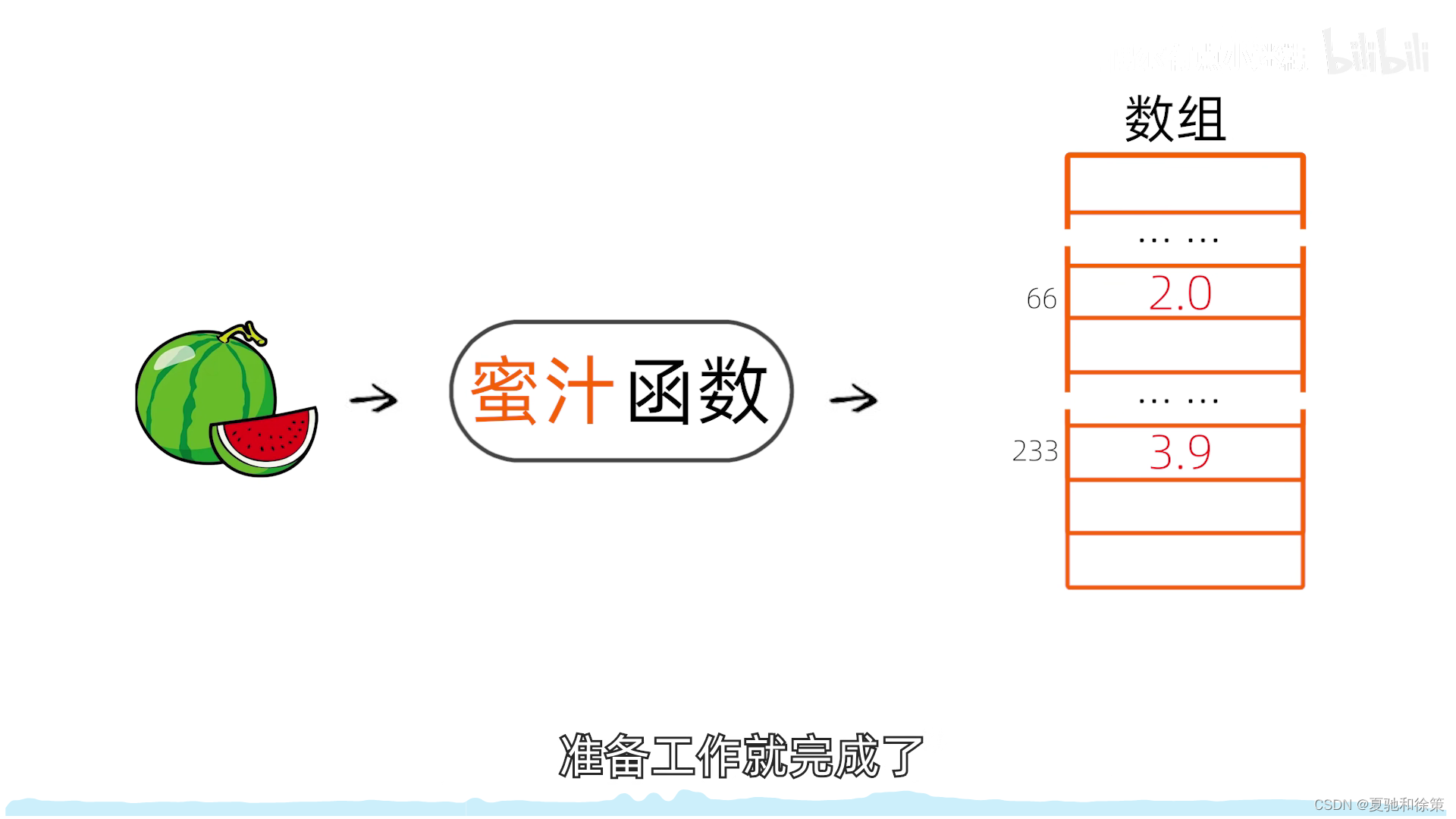
2. 散列表 (Hash Table)
- 一个有限的连续地址空间,用于存储按散列函数计算得到的散列地址的数据记录。通常是一个一维数组,数组的索引就是散列地址。


3. 冲突和同义词
- 冲突 (Collision): 两个不同的关键字通过散列函数得到相同的散列地址的现象。
- 同义词 (Synonyms): 产生冲突的这两个关键字称为同义词。





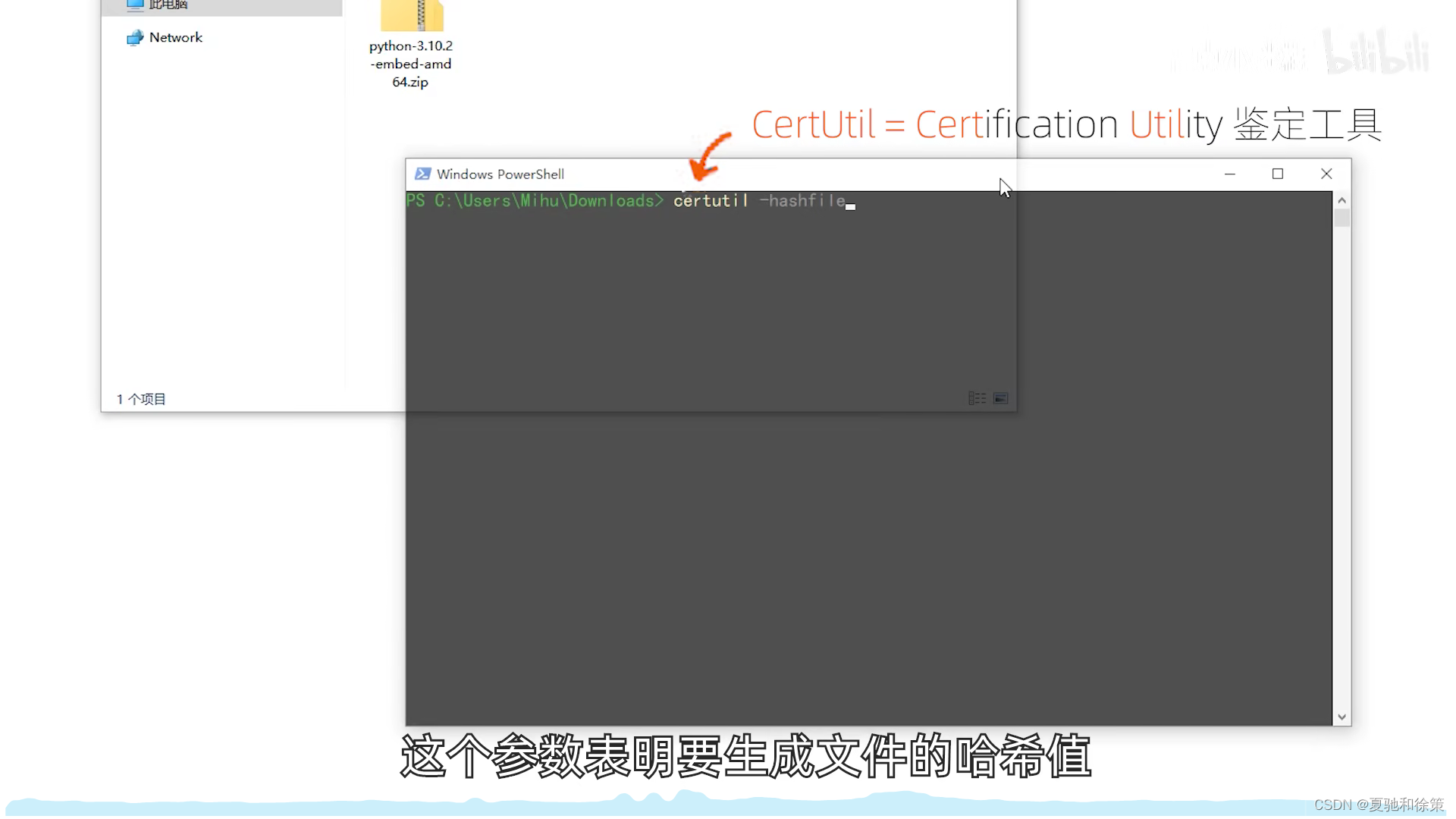
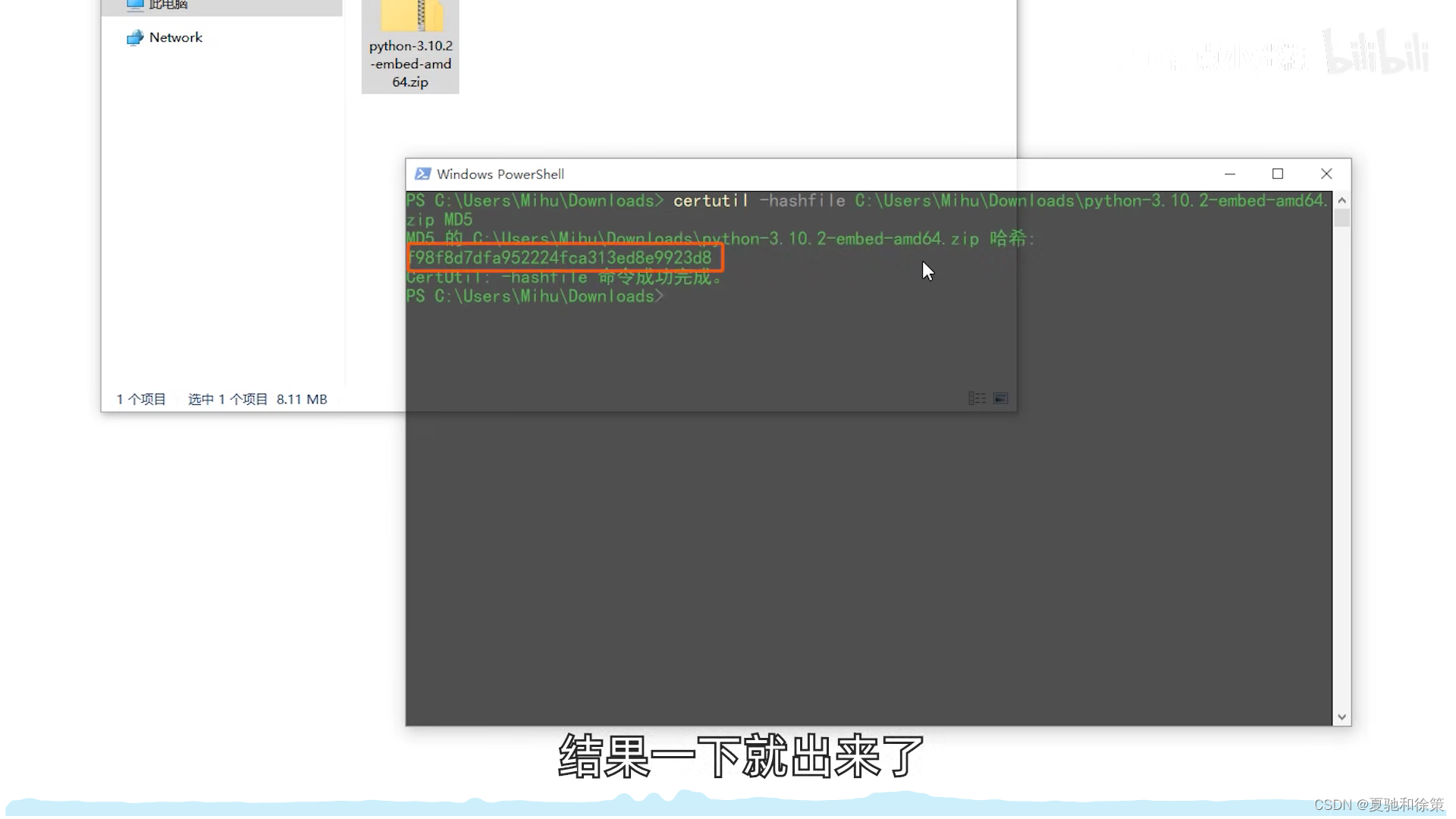
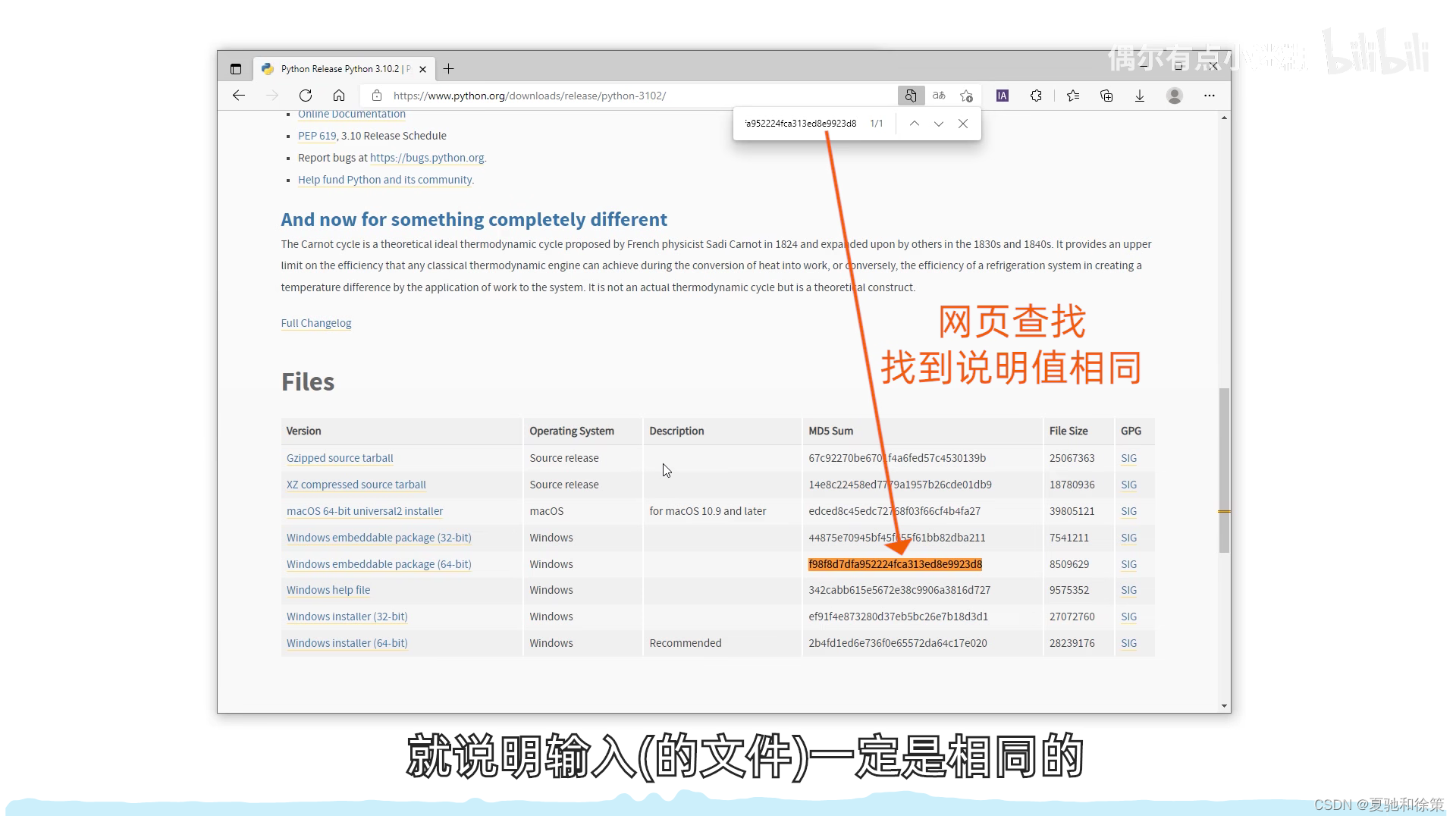
实例
假设我们有一个关键字集合包括 `main`, `int`, `float` 等词。我们可以创建一个包含26个元素的散列表来存储这些关键字。我们可以将关键字的第一个字母的字母表序号作为散列函数的输出。
但是,如果我们扩展关键字集合,添加更多的词,比如 `short`, `default`, `double` 等,我们会发现现有的散列函数将产生更多的冲突。这些冲突和同义词需要妥善处理。
冲突解决
在实际应用中,完全避免冲突几乎是不可能的,因为关键字的取值集合通常远大于表空间的地址集。因此,我们需要寻找“好”的散列函数来尽量减少冲突,并设计相应的措施来解决冲突。
散列查找法的核心问题
1. 构造高效的散列函数。
2. 设计合理的冲突处理策略。
我的理解:
让我们把哈希表比喻成一个巨大的储物柜系统。
1. 储物柜系统(哈希表)
想象一下有一排排的储物柜,每个柜子都有一个独特的编号。
2. 钥匙和锁匠(哈希函数)
我们有一个特殊的锁匠,他可以根据你给他的物品(键),快速为你打造一把可以打开某个储物柜的钥匙。这个锁匠就好比是哈希函数,他可以快速的把你的物品(键)转换成储物柜的编号(哈希值)。
3. 存取物品(插入与查找操作)
- 存物品:你带着一个物品来到这个储物柜系统,锁匠(哈希函数)会根据你的物品快速制作一把钥匙。你用这把钥匙打开相应编号的柜子,将物品存入。
- 取物品:当你想取回你的物品时,你只需要再次找到锁匠,他会为你制作一把同样的钥匙,你可以用它打开柜子并取回你的物品。
4. 碰撞(哈希冲突)
但是这个系统不是完美的,有时候两个完全不同的物品,锁匠会为它们制作出一样的钥匙,这就叫做“碰撞”。为了解决这个问题,每个储物柜可以存储一个箱子,箱子里可以放很多物品。
5. 调整柜子大小(动态调整)
如果某一天,储物柜太满了,我们会调用一队工人来扩建储物柜系统,增加更多的柜子,然后重新分配每个物品的位置,以保持操作的高效性。
通过这个比喻,我们可以理解哈希表的以下特点:
1. 快速存取: 哈希表(储物柜系统)允许我们快速存取物品。我们不需要检查每个柜子来找到我们的物品,只需要用锁匠(哈希函数)快速得到正确的柜子编号。
2. 哈希冲突和解决方案: 有时候,两个不同的物品可能会得到同样的柜子编号,这称为哈希冲突(碰撞)。为了解决这个问题,我们可以在一个柜子里放一个箱子,用来存储多个物品(这种方法叫链地址法)。
3. 动态调整: 当储物柜系统变得太满或太空时,我们可以增加或减少柜子的数量来保证系统的高效运行(这是动态调整哈希表的大小,以保持一个好的装载因子,即储存的物品数目与柜子数量的比例)。
4. **优缺点**: 哈希表提供了非常快的存取速度,但它也有一些缺点,如需要处理哈希冲突,和可能需要动态调整大小以保持高效。

7.4.2 散列函数的构造方法
我的理解:
1. 数字分析法
- 比喻:想象一下,每个人都有一把特定的钥匙,钥匙上的凹凸代表了这把钥匙的特性。数字分析法就像挑选那些凹凸最独特、最不同的部分来识别一把钥匙。
- **解释**:这种方法根据关键字的每一位的数字分布情况来选择合适的位数,构造散列地址,避免冲突。
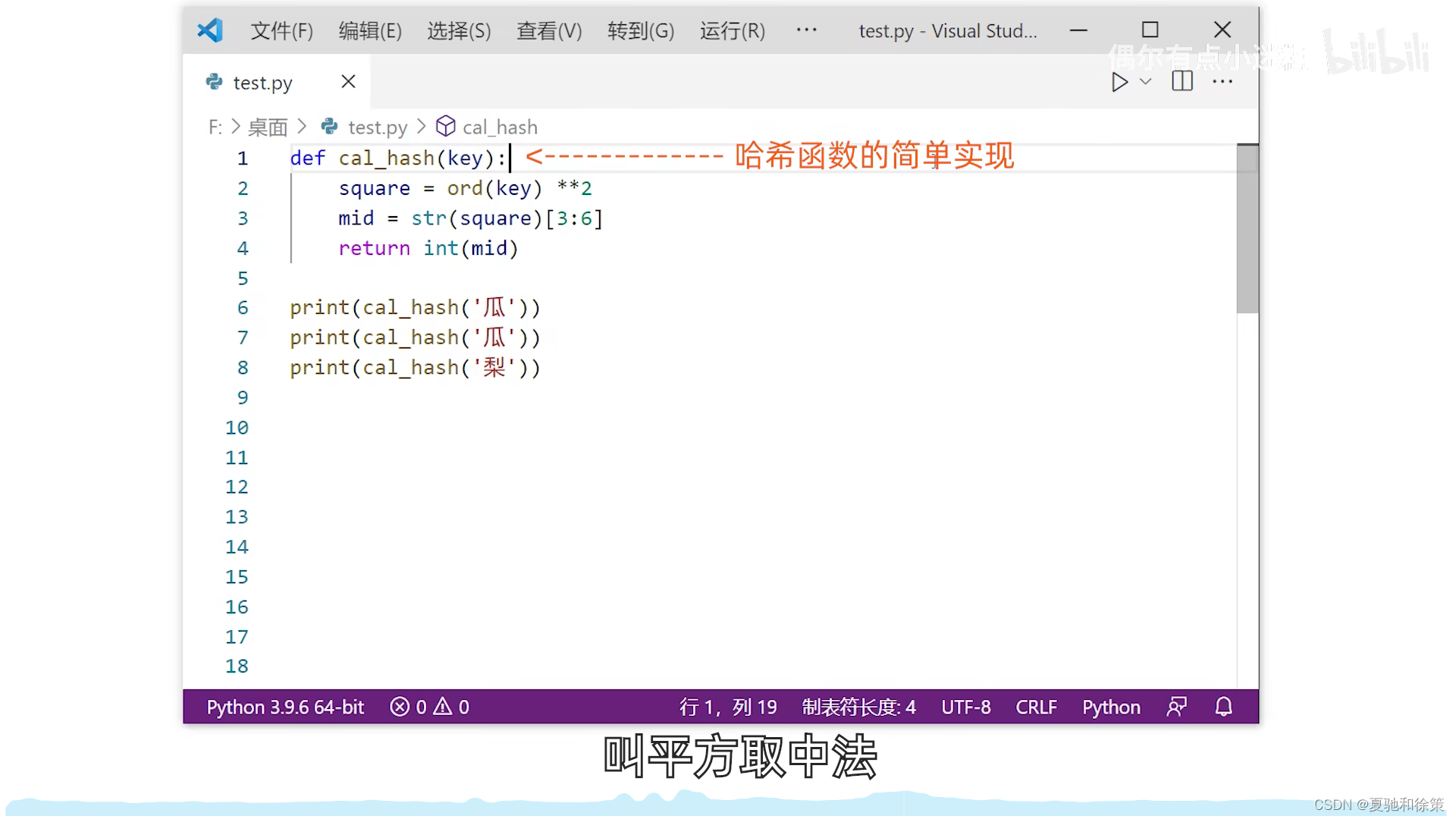
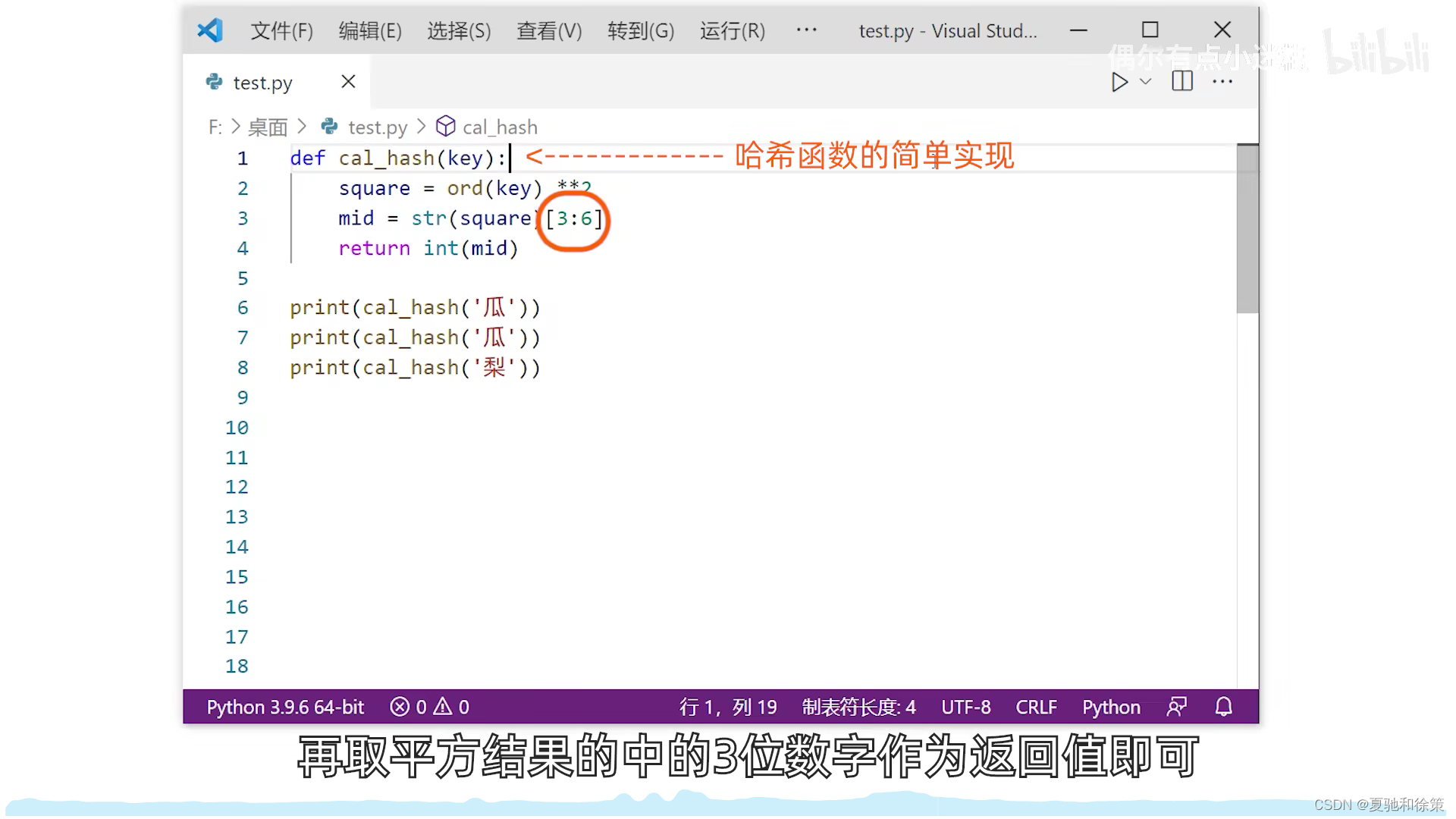
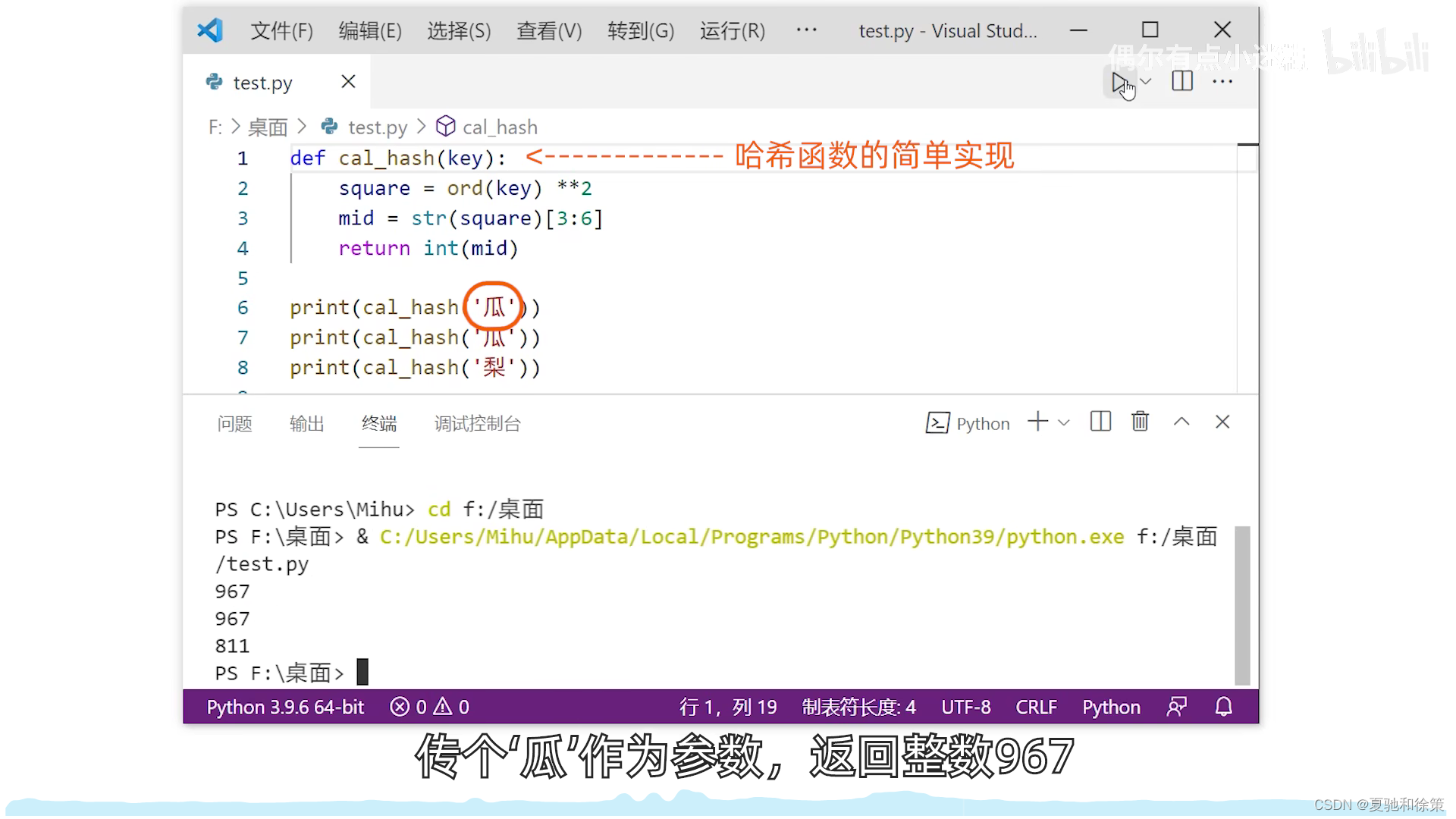
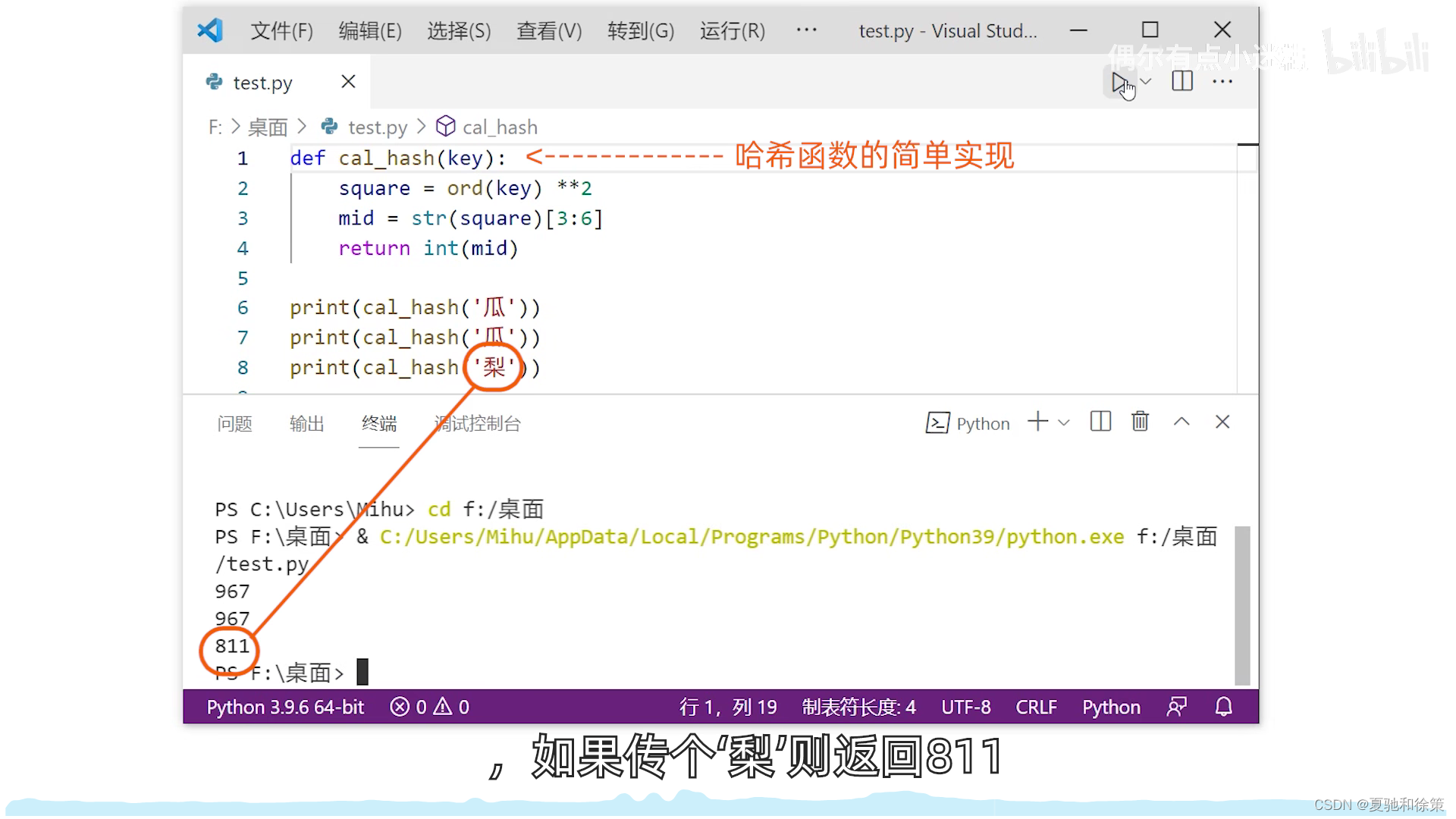
2. 平方取中法
- 比喻:这就像一颗种子,我们不知道它外表的每个部分具体是什么,但我们知道,当这颗种子成长时,它的“核心”或中间部分包含了它的基本特性。所以,我们观察这颗种子的中间部分来了解它。
- 解释:在这种方法中,关键字被平方,然后取中间的几位作为散列地址。即便我们无法知道所有关键字的具体情况,这种方法也能确保关键字的散列地址随机分布。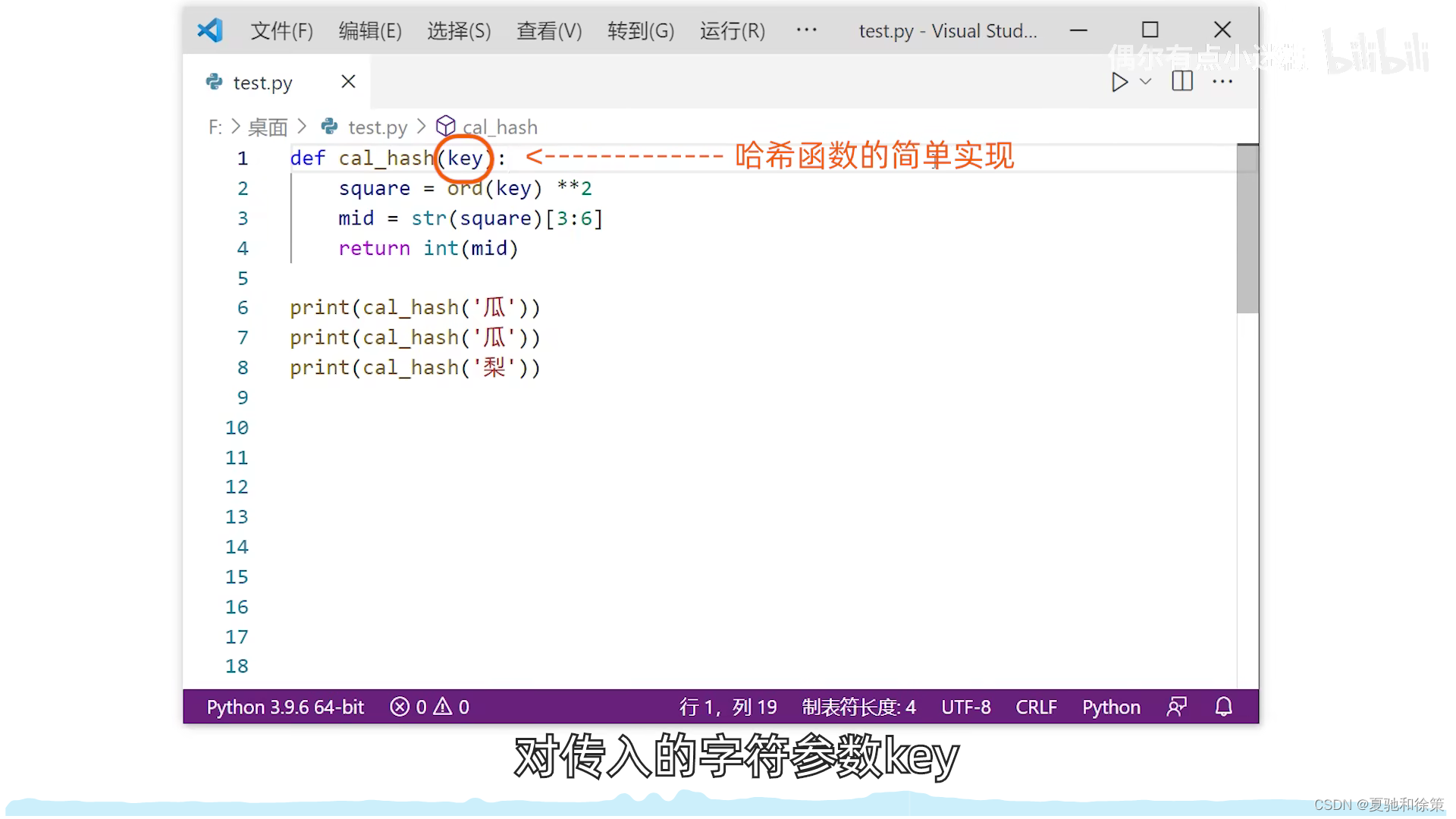
3. 折叠法
- 比喻:折叠法就像一张纸,我们将它折叠成几个部分,然后将这几部分叠加在一起,形成一个新的形状。这个新形状代表了原纸的某些特性。
- 解释:这种方法是将关键字分割成位数相同的几部分,然后取这几部分的叠加和作为散列地址。这适用于当关键字的位数较多,而散列地址的位数较少的情况。
4. 除留余数法
- 比喻:这就像一个水果篮子,我们有很多苹果要放进篮子里,但篮子的大小是有限的。所以,我们通过计算每个苹果放入后篮子里剩下的空间来标记这个苹果。即使有更多的苹果,我们依然可以用这种方法来区分它们。
- 解释:除留余数法是将关键字除以一个不大于表长的数,取得的余数作为散列地址。这个方法计算简单,适用范围广泛,是构造散列函数的常用方法。
在生活中的应用:
散列函数(Hash Function)的设计是一门科学,涉及多个方面的考量。对于这四种散列函数构造方法(数字分析法、平方取中法、折叠法、除留余数法),使用实际例子而不是仅仅比喻,可能会更加直观易懂。
1. 数字分析法(Digital Analysis Method)
解释:
数字分析法中,我们分析键值的各个数字,找出最具有随机性的数字组合作为散列地址。
例子:
比如说有ISBN号,如果我们发现前三位是出版社代码,经常是相同的,就不能用这几位。如果后几位是出版顺序,更有随机性,就可以用这几位。
2. 平方取中法(Mid-square Method)
解释:
我们先取一个数字(比如关键字的内部编码),将它平方,然后从中间提取几位数字作为散列地址。
例子:
假设有一个关键字`IDA1`,它的内部编码为`09040101`,我们先平方这个数字,然后从结果中取中间几位作为散列地址。
3. 折叠法(Folding Method)
解释:
折叠法是将关键字分成几部分,然后将这几部分加在一起(或者按照一定规则组合在一起)形成散列地址。
例子:
有一个数字`45387765213`,我们将它分成`453`、`877`、`652`和`13`四部分,然后将这四部分按照一定的方法相加,得到的结果就是我们的散列地址。
4. 除留余数法(Division-remainder Method)
解释:
我们取一个数p(通常为小于表长的最大质数)来除以关键字,得到的余数就作为散列地址。
例子:
如果表长为100,我们可以选择97作为p。对于任何给定的关键字key,我们计算`key % 97`,结果就是散列地址。
总结:
这四种方法各有特点,通常要根据关键字的特性和实际应用的需要来选择最合适的散列函数。无论采用哪种方法,目标都是尽量减少冲突,使得散列得到的地址能够均匀地分布在地址空间中。

7.4.3 处理冲突的方法
笔记:
7.4.3 处理冲突的方法
创建和查找散列表时,通常会遇到冲突。处理冲突的方法应该一致。按组织形式不同,处理冲突主要分为开放地址法和链地址法。
1. 开放地址法
开放地址法的核心思想是,所有记录都存储在散列表数组中。当发生冲突时,会计算得到另一个地址。这一过程持续直到找到一个无冲突的地址。寻找下一个空位的过程称为探测。
- 线性探测法
顺序寻找空单元。缺点是可能产生“二次聚集”现象。
- 二次探测法
通过平方的方法寻找空单元,可避免“二次聚集”。但不能保证一定找到无冲突的地址。
- 伪随机探测法
使用伪随机数序列,同样可以避免“二次聚集”,但也存在找不到无冲突地址的问题。
2. 链地址法
链地址法将具有相同散列地址的记录放在同一单链表中。有m个散列地址就有m个单链表。散列表数组存放着各个链表的头指针。依次计算各关键字的散列地址,然后将关键字插入相应的链表。
实例:
- 开放地址法
例如,散列表长度为11,散列函数为H(key)=key%11,用不同的开放地址法处理冲突时,关键字38会被插入到不同的位置。
- 链地址法
例如,散列函数H(key)=key%13,关键字如(19,14,23,1,68,20,84,27,55,11,10,79),用链地址法处理冲突时,同一散列地址的关键字会被插入到同一链表中。
总结:
处理冲突的方法根据实际应用的需求选择。开放地址法适用于记录较少,链地址法适用于冲突较多的场合。无论选择哪一种方法,都要尽可能地减少冲突,实现高效的查找。
这个总结涵盖了处理冲突的基本方法,包括了开放地址法和链地址法的多种具体实现方式,并通过实例进行了直观的解释,为理解和选择合适的处理冲突方法提供了基础。
我的理解:
我们可以将散列表比作一个停车场,而每一个关键字就像是一辆车,每个停车位都有一个唯一的编号,即散列地址。
### 开放地址法
1. **线性探测法**
- **比喻**:如果你的车位(散列地址)已经被占据了,你会一直往前开,找到第一个空的车位停车。
- **解读**:如果目标地址已被占用,将顺序检查下一地址,直到找到空位。
2. **二次探测法**
- **比喻**:如果你的车位被占了,你可能会跳过一个车位再看,如果还满,就跳过两个,以此类推,直到找到空车位。
- **解读**:如果目标地址已被占用,会按照二次方的顺序跳过地址寻找空位。
3. **伪随机探测法**
- **比喻**:如果你的车位被占了,你会按照一个似乎毫无规律的方式在停车场里找空车位。
- **解读**:使用一个伪随机序列来决定下一个要探测的地址。
### 链地址法
- **比喻**:这个停车场有多层,每个车位都是一个电梯入口。当你的车位被占了,你可以把车停到这个车位对应的电梯的下一层,那里还有更多的车位。每层车位都链接在一起,形成一个链表。
- **解读**:每个散列地址指向一个链表,所有散列到同一地址的元素都存储在这个链表中。
### 总结
- **开放地址法**:类似于在停车场里,沿着某种规律寻找空车位。
- **链地址法**:类似于利用多层停车场,在垂直方向上寻找空车位。

7.4.4 散列表的查找
主要内容:
散列表查找
- 目标:
- 在散列表中快速找到给定关键字的元素。
- 过程:
- 根据给定的关键字和散列函数计算散列地址。
- 检查计算出的散列地址是否包含匹配的关键字。
- 如果该地址是空的,或者包含匹配的关键字,则查找结束。
- 如果出现冲突,继续按照一定的规则(例如线性探测)寻找下一个可能的地址,重复上述过程。
算法描述
- 根据散列函数�(���)H(key)计算初始散列地址�0H0。
- 如果�0H0为空,元素不存在,返回-1。
- 如果�0H0中的关键字匹配,查找成功。
- 如果�0H0中的关键字不匹配,按照冲突解决策略(如线性探测)计算下一个地址,重复上述过程。
算法分析
特点
开放地址法(以线性探测法为例)
最终思考
- 散列表查找的效率是通过平均查找长度来衡量的,该长度取决于散列函数的好坏、冲突解决策略和装填因子�α。
- 装填因子�α定义为散列表中已填入的记录数除以散列表的长度,影响冲突的可能性。
- 一个好的散列函数应该均匀分布关键字,减少冲突的可能性。
-
笔记
散列表查找
- 目标:高效地找到给定关键字的元素。
- 算法步骤:
- 计算散列地址。
- 检查地址是否匹配。
- 若不匹配,按冲突解决策略找到下一个地址。
- 效率:平均查找长度,受散列函数、冲突解决策略、装填因子影响。
- 装填因子�α:已填记录数与表长的比例。影响冲突的可能性。
- 散列函数:应均匀分布关键字,减少冲突。
- 平均查找长度是装填因子�α的函数,而非记录个数�n的函数。
- 合适的�α可以将平均查找长度保持在一个可接受的范围。
- 散列表的设计和实现需要综合考虑散列函数的选择、冲突解决策略和装填因子。
- 查找成功时的平均查找长度:受装填因子影响。
- 查找失败时的平均查找长度:受装填因子和散列函数的均匀性影响。
- 选择合适的冲突解决策略和散列函数,以及合理控制装填因子,是实现高效散列表查找的关键。
我的理解:
散列表查找可以通过以下的比喻来理解:
想象一下,你是一个邮递员,你的任务是把邮件送到正确的邮箱。每个邮箱都有一个独特的编号,这个编号是通过某种计算得来的,就像散列函数计算得到散列地址。城市(散列表)中有很多这样的邮箱(存储单元),而每个人的住址(关键字)都映射到一个邮箱编号(散列地址)。
#### 算法步骤比喻:
1. **计算散列地址**:
- 你查看每封邮件的地址(关键字),通过一张特殊的地图(散列函数)找到相应的邮箱编号(散列地址)。
2. **检查地址是否匹配**:
- 你走到对应的邮箱,检查上面的名字和你手上邮件上的名字是否一致。
3. **冲突解决**:
- 如果你发现该邮箱已经被别人的邮件占用了(冲突),你就会按照一定的路线(冲突解决策略,例如线性探测法)去找下一个可用的邮箱。
#### 算法分析比喻:
- **平均查找长度**:
- 这就像你送每封邮件所需的平均时间。如果邮件地址(关键字)和邮箱编号(散列地址)的匹配度很高,你就能很快送到;如果经常发生冲突,你就需要更多时间去找空邮箱。
- **装填因子**:
- 这就像城市中的邮箱被占用的程度。如果几乎每个邮箱都有邮件,那么找到空邮箱的概率就会变小,导致送邮件的时间增加。
#### 特点比喻:
- 如果城市里的邮箱足够多,即使有很多邮件要送,邮递员也能迅速找到空邮箱,保持高效的送信速度。
- 散列表的大小(邮箱的数量)、如何分配这些邮箱(散列函数的选择)、当发生冲突时如何寻找下一个邮箱(冲突解决策略)都会影响邮递员送信的效率。
通过这个比喻,可以更形象地理解散列表查找的过程和其中的各种概念。

例三:
我的理解:
这个问题是关于构建和分析哈希表(散列表)的,使用了线性探测法处理哈希冲突,并讨论了查找成功和失败的平均查找长度。
### 步骤1:理解问题
首先,你要处理的问题是将一组关键字插入到一个哈希表中,哈希表的长度为16,哈希函数为 \( H(key) = key \% 13 \),处理冲突的方法是线性探测法。
### 步骤2:插入关键字
接下来,你需要依次插入关键字。每个关键字首先通过哈希函数找到应该插入的位置,如果该位置没有被占用,直接插入;如果被占用,就向后查找,直到找到空位。重复此过程,直到所有关键字都被插入。
### 步骤3:分析查找成功的平均查找长度
查找成功的平均查找长度(ASL)是查找所有元素时进行关键字比较的平均次数。通过分析插入过程中每个关键字的比较次数,并将它们平均,就可以得到查找成功时的平均查找长度。
例如:
\[ ASL_{suc} = \frac{1 \times 6 + 2 + 3 \times 3 + 4 + 9}{12} = 2.5 \]
### 步骤4:分析查找失败的平均查找长度
查找失败的平均查找长度是在假设关键字不在哈希表中时进行的平均比较次数。为此,你需要分析每个可能的哈希值对应的查找失败时的比较次数,然后将它们平均。
例如:
\[ ASL_{un} = \frac{3 + 13 + 12 + 11 + 10 + 9 + 8 + 7 + 6 + 5 + 4 + 3 + 2}{13} \approx 7 \]
### 步骤5:比较不同冲突处理策略
最后,你需要对比线性探测法和链地址法。通过分析,你会发现,链地址法处理冲突时不会发生二次聚集,因此在平均查找长度上具有优势,特别是当表长不确定时,链地址法通过动态分配节点空间更为灵活和高效。
### 详细分析:
1. **关键字插入和冲突解决:**
- 按照给定的哈希函数和线性探测法,逐一计算每个关键字的哈希地址,并解决可能出现的冲突,直到所有关键字都插入到哈希表中。
2. **查找成功的平均查找长度:**
- 每个关键字的查找成功时的比较次数是插入该关键字时的比较次数。将所有关键字的查找成功时的比较次数相加然后除以关键字的数量就得到了查找成功的平均查找长度。
3. **查找失败的平均查找长度:**
- 为了得到查找失败的平均查找长度,需要对每个可能的哈希值进行分析,计算出从每个位置开始直到查找失败时所需的比较次数,然后将这些次数求平均。
4. **策略比较:**
- 最后,这个例子通过具体的计算展示了在相同的条件下,链地址法在平均查找长度和空间使用灵活性上都优于线性探测法。
通过这种方式,可以对给定的哈希函数和冲突解决策略进行详细的分析和比较,进一步理解它们的性质和适用性。




哈希表的概念:
哈希表是一种常用的数据结构,它可以在 O(1) 的时间复杂度内执行插入、查找和删除操作。哈希表的核心思想是使用哈希函数将键值对映射到数组中的一个位置上,从而实现快速的访问和修改。
哈希表由两个主要部分组成:哈希函数和数组。哈希函数将键映射到数组的下标,而数组则用来存储键值对。当需要访问或修改某个键值对时,只需要使用哈希函数将键转换为数组下标,然后访问或修改对应的位置即可。
使用哈希表的关键在于设计一个好的哈希函数,它应该满足以下几个要求:
- 一致性:同一个键总是映射到相同的数组下标。
- 均匀性:尽可能地使键被映射到不同的数组下标上,从而减少哈希冲突的概率。
- 高效性:计算哈希值的时间应该尽量短,以保证操作的高效性。
解决哈希冲突的方法有多种,常用的有链表法和开放地址法。链表法是在每个数组元素上维护一个链表,当哈希冲突发生时,将新的键值对插入到链表中。开放地址法则是尝试在其他空闲的位置上插入键值对,比如线性探测、二次探测和双重哈希等。
需要注意的是,哈希表的性能取决于哈希函数的设计和数组的大小。如果哈希函数不好,或者数组太小,就会导致哈希冲突增多,从而降低哈希表的效率。因此,在实际应用中,需要根据具体的场景来设计合适的哈希函数和数组大小,以达到最优的性能。
我的理解:
哈希表是一种用于快速查找和插入的数据结构,其核心思想是通过哈希函数将键映射到数组中的一个位置上。哈希函数将键映射到数组中的位置时,需要满足一致性、均匀性和高效性等要求。具体地说,一致性要求相同的键总是映射到相同的位置上,均匀性要求哈希函数能够尽可能地将键均匀地映射到数组中的位置上,高效性要求计算哈希值的时间尽量短。
哈希表的优点在于其插入、查找和删除的时间复杂度都为 O(1),即常数级别的时间复杂度,因此在需要快速进行这些操作的场合下,哈希表是一种非常有用的数据结构。常用的哈希表实现方式有链表法和开放地址法,其中链表法在哈希冲突时使用链表来存储冲突的键值对,而开放地址法则是尝试在其他空闲的位置上插入键值对。
总的来说,理解哈希表的概念需要掌握哈希函数的设计原理、数组的存储方式和解决哈希冲突的方法等基础知识,以及如何在实际应用中根据具体的场景来选择适合的哈希表实现方式。
例子:
假设我们有一个存储学生信息的数据集合,其中每个学生的信息包括学号、姓名、年龄等。我们需要能够快速地根据学号查找到对应的学生信息。这时,我们可以使用哈希表来实现这个功能。
首先,我们需要设计一个哈希函数,将学号映射到一个数组中的位置上。一种简单的哈希函数可以是取学号的最后几位作为数组下标,比如我们可以取学号的后两位作为下标,那么学号为"20230001"的学生会被映射到数组的第1个位置上,学号为"20230002"的学生会被映射到数组的第2个位置上,以此类推。
接下来,我们可以将每个学生的信息存储到对应的数组位置中。当需要查找某个学生信息时,只需要通过哈希函数计算出该学生信息所在的数组位置,然后访问该位置上的元素即可。
例如,如果我们需要查找学号为"20230001"的学生信息,就可以通过哈希函数将其映射到数组的第1个位置上,然后访问该位置上的元素,即可得到该学生的姓名、年龄等信息。由于哈希表的时间复杂度为 O(1),因此可以在常数级别的时间内完成这个操作,非常高效。
哈希表的实现:
C语言:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define TABLE_SIZE 100
// 定义哈希表节点的结构体
typedef struct node {
char *key; // 节点的键
int value; // 节点的值
struct node *next; // 指向下一个节点的指针
} Node;
// 定义哈希表的结构体
typedef struct {
Node *buckets[TABLE_SIZE]; // 存放哈希桶的数组
} HashTable;
// 哈希函数,使用简单的取模法
int hash(char *key) {
int hash = 0;
for (int i = 0; i < strlen(key); i++) {
hash += key[i];
}
return hash % TABLE_SIZE;
}
// 创建一个新节点
Node *create_node(char *key, int value) {
Node *node = (Node *) malloc(sizeof(Node));
if (node == NULL) {
fprintf(stderr, "Error: out of memory\n");
exit(1);
}
node->key = strdup(key); // 使用strdup函数分配内存并复制字符串
node->value = value;
node->next = NULL;
return node;
}
// 向哈希表中插入一个节点
void hash_table_insert(HashTable *ht, char *key, int value) {
int index = hash(key);
Node *node = create_node(key, value);
node->next = ht->buckets[index];
ht->buckets[index] = node;
}
// 在哈希表中查找一个节点
int hash_table_find(HashTable *ht, char *key) {
int index = hash(key);
Node *node = ht->buckets[index];
while (node != NULL) {
if (strcmp(node->key, key) == 0) {
return node->value;
}
node = node->next;
}
return -1; // 表示未找到节点
}
// 主函数,测试代码
int main() {
HashTable ht;
for (int i = 0; i < TABLE_SIZE; i++) {
ht.buckets[i] = NULL;
}
hash_table_insert(&ht, "apple", 1);
hash_table_insert(&ht, "banana", 2);
hash_table_insert(&ht, "cherry", 3);
printf("%d\n", hash_table_find(&ht, "apple")); // 输出 1
printf("%d\n", hash_table_find(&ht, "banana")); // 输出 2
printf("%d\n", hash_table_find(&ht, "cherry")); // 输出 3
printf("%d\n", hash_table_find(&ht, "orange")); // 输出 -1,表示未找到
return 0;
}
解释:
这个哈希表使用简单的取模法来计算键的哈希值,将节点插入到对应的哈希桶中,并使用链表解决冲突。在插入和查找节点时,分别使用哈希函数计算出键的哈希值,然后访问对应的哈希桶,遍历链表查找对应的节点。如果找到节点,则返回其值,否则返回-1。
C++实现:
#include <iostream>
#include <string>
using namespace std;
const int TABLE_SIZE = 100;
class HashNode {
public:
int key;
string value;
HashNode* next;
HashNode(int key, string value) {
this->key = key;
this->value = value;
this->next = nullptr;
}
};
class HashMap {
private:
HashNode** table;
public:
HashMap() {
table = new HashNode*[TABLE_SIZE];
for (int i = 0; i < TABLE_SIZE; i++) {
table[i] = nullptr;
}
}
~HashMap() {
for (int i = 0; i < TABLE_SIZE; i++) {
HashNode* entry = table[i];
while (entry != nullptr) {
HashNode* prev = entry;
entry = entry->next;
delete prev;
}
table[i] = nullptr;
}
delete[] table;
}
int getHashCode(int key) {
return key % TABLE_SIZE;
}
void insert(int key, string value) {
int hash = getHashCode(key);
HashNode* entry = table[hash];
if (entry == nullptr) {
table[hash] = new HashNode(key, value);
} else {
while (entry->next != nullptr) {
entry = entry->next;
}
entry->next = new HashNode(key, value);
}
}
string search(int key) {
int hash = getHashCode(key);
HashNode* entry = table[hash];
while (entry != nullptr) {
if (entry->key == key) {
return entry->value;
}
entry = entry->next;
}
return "";
}
void remove(int key) {
int hash = getHashCode(key);
HashNode* entry = table[hash];
HashNode* prev = nullptr;
while (entry != nullptr && entry->key != key) {
prev = entry;
entry = entry->next;
}
if (entry == nullptr) {
return;
}
if (prev == nullptr) {
table[hash] = entry->next;
} else {
prev->next = entry->next;
}
delete entry;
}
};
int main() {
HashMap map;
map.insert(1, "apple");
map.insert(2, "banana");
map.insert(3, "cherry");
map.insert(4, "date");
cout << map.search(2) << endl; // output: banana
map.remove(3);
cout << map.search(3) << endl; // output: (empty string)
return 0;
}
解释:
这个示例中,我们定义了一个HashNode类来表示哈希表的节点,它包含了一个键值对和指向下一个节点的指针。我们还定义了一个HashMap类来实现哈希表,它包含了一个指向指针数组的指针,数组的长度为TABLE_SIZE。我们还实现了一些基本操作,如哈希函数的计算、插入、搜索和删除等。
总结:
哈希表的重点:
-
哈希函数的设计:哈希函数需要将键映射到哈希表中的一个位置,使得每个位置都有均匀的分布,并且不同的键能够映射到不同的位置。
-
哈希冲突的处理:哈希冲突是指不同的键映射到了同一个位置,通常有两种处理方式:开放地址法和链表法。开放地址法会寻找哈希表中下一个空闲位置来存储键值对,而链表法会将冲突的键值对组织成一个链表,存储在同一个桶中。
哈希表的难点和易错点:
-
哈希函数的设计需要考虑多种因素,包括键的分布、哈希表的大小和性能等,因此需要具备较强的数学能力和经验。
-
哈希表的性能受到哈希冲突的影响,因此需要合理选择哈希函数和解决冲突的方法,避免出现过多的冲突,降低查询效率。
-
哈希表的空间占用和性能之间存在一定的权衡关系,需要根据具体应用场景和要求进行选择和优化。
-
哈希表的实现需要注意边界条件和特殊情况,比如哈希表为空、键不存在等情况的处理。此外,需要注意哈希函数的输出值需要在哈希表大小范围内。
-
在使用哈希表进行并发操作时,需要考虑线程安全的问题,避免出现竞争条件和数据损坏等情况。
截图来自B站up:偶尔有点小迷糊



















 1299
1299

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











