









8.4 一个简单的代码生成器
代码生成是编译过程中的一个关键步骤,它将高级语言编写的程序转换为机器可以直接执行的指令集。在本节中,我们将探讨一个简单的代码生成器的设计和实现,这种代码生成器针对的是基本块内的代码生成,优化寄存器的使用以减少不必要的内存访问,从而提高程序的执行效率。
寄存器的优化使用
寄存器是CPU内部的小容量存储设备,访问速度远高于主存储器。因此,高效地使用寄存器对于提高程序运行速度至关重要。本节介绍的代码生成算法着重于如何在给定的基本块中最优化地使用寄存器,以避免不必要的内存访问。寄存器的主要用途可以分为以下几类:
- 运算对象存储:大多数机器架构要求某些或全部运算对象必须在寄存器中。
- 临时存储单元:在计算大型表达式或保存基本块内后续操作需要使用的值时使用。
- 全局值存储:用于保存基本块内计算的值,这些值在其他基本块中也需要使用。
- 运行时存储空间管理:例如,作为栈顶指针和活动记录基址指针等。
代码生成算法
本节的代码生成算法通过顺序考虑基本块中的每条语句,并根据当前寄存器的使用情况为每条语句生成目标代码。算法的关键在于维护寄存器的使用状态,以及根据这些状态决定如何为后续操作分配寄存器。算法主要遵循以下原则:
- 尽可能长时间地保留计算结果在寄存器中,只在以下两种情况下将值存回内存:
- 当寄存器需要被重新用于其他计算时。
- 在基本块的出口点,以便将这些值保存起来供后续使用。
寄存器描述和地址描述
为了有效地生成代码,算法需要跟踪每个寄存器当前存储的值(寄存器描述),以及每个变量当前值可以在哪里找到(地址描述)。这些信息对于决定如何为特定的三地址语句生成代码至关重要。例如,对于三地址语句 a = b + c:
- 如果寄存器
Ri包含b,寄存器Rj包含c,且b在此语句后不再活跃,则可以生成代价为1的代码ADD Rj, Ri,结果a在Ri中。 - 如果
Ri包含b,但c在内存中,且b仍然不再活跃,则可以生成代价为2的代码ADD c, Ri或代价为3的代码序列:MOV c, RjADD Rj, Ri
这个过程涉及对许多可能的情况的考虑,包括操作数的位置(寄存器还是内存)、操作数是否为常数,以及操作的交换性。有效的代码生成需要对这些情况进行细致的分析,以选择最优的代码序列。
结论
本节介绍的简单代码生成器强调了寄存器优化使用的重要性。通过精心设计代码生成算法,可以显著提高程序执行的效率,减少不必要的内存访问。寄存器描述和地址描述的维护是实现这一目标的关键步骤,它们提供了必要的信息来指导寄存器的高效使用和代码的生成。

8.4.2 代码生成算法
本节详细介绍了一种用于基本块的代码生成算法。该算法以三地址语句序列作为输入,并通过一系列步骤为每条语句生成目标代码。这一过程关键地依赖于寄存器和内存的有效使用,以及对操作数位置的精确跟踪。
算法步骤概述
步骤1: 确定计算结果的存储位置
- 使用
getReg函数确定计算结果y op z的存储位置L,L通常是寄存器,但也可能是内存单元。后续部分将简要描述getReg的算法。
步骤2: 确定操作数 y 的位置
- 查看
y的地址描述,找到存放y当前值的位置y'。如果y的值同时存在于寄存器和内存中,优先选择寄存器作为y',尤其是当y的值已经在L中时。如果y的值还不在L中,则生成MOV y', L指令,将y的值复制到L。
步骤3: 生成操作指令
- 生成指令
op z', L,其中z'是存放z当前值的位置之一。如之前所述,如果z的值同时存在于寄存器和内存中,优先选择寄存器。然后,更新x的地址描述,表明x的值现在在L中。如果L是寄存器,更新其描述以反映它现在包含x的值。
步骤4: 更新寄存器描述
- 如果
y和/或z在当前基本块内不再被引用,并且在块的出口点也不活跃,且它们的值还在寄存器中,则更新寄存器描述,表示执行了x = y op z之后,这些寄存器不再包含y和/或z的值。
对于一元操作符的三地址语句和复制语句 x = y,处理方法类似,但更为简单。特别地,如果 y 的值仅在内存中,通常使用 getReg 来为 y 寻找一个寄存器,并更新寄存器和地址描述,记住 x 的值现在也在该寄存器中。
基本块出口的处理
处理完一个基本块的所有三地址语句后,在基本块的出口处,需要将那些值尚不在它们对应内存单元中的活跃变量的值,通过 MOV 指令存入它们的内存单元。这需要利用寄存器描述来决定哪些变量的值仍在寄存器中,并通过地址描述和活跃变量信息来确定哪些需要存储。
结论
此代码生成算法强调了在基本块级别对寄存器和内存的有效管理,以及对操作数位置的精确控制。通过减少不必要的内存访问和优化寄存器使用,该算法旨在提高生成代码的效率和性能。这种方法的成功依赖于准确的寄存器和地址描述,以及对基本块内外活跃变量的详细分析。

8.4.3 寄存器选择函数 getReg
寄存器选择对于优化代码生成过程至关重要。本节讨论了函数 getReg 的实现,它是代码生成算法中的核心部分,负责选择存放计算结果 x 的最佳场所 L。这里介绍一个基于下次引用信息的简单而有效的寄存器分配策略。
寄存器分配策略
步骤1: 利用现有寄存器
- 如果变量
y已在某寄存器中,并且该寄存器不包含其他变量的值(特别是在x = y op z形式的复制语句中),且y在执行操作后不再被当前块引用,则将此寄存器作为L返回。
步骤2: 寻找空闲寄存器
- 如果步骤1失败,即没有现有寄存器直接可用,则查找一个空闲寄存器并返回作为
L。
步骤3: 重用占用的寄存器
- 当没有空闲寄存器可用时,选择一个已被占用的寄存器
R。如果R中的值尚未保存至其对应的内存单元,则先生成MOV R, w指令,将R的值存入w的内存单元,并更新w的地址描述。选择哪个寄存器作为R应优先考虑其数据最晚被再次使用的寄存器,或者其数据已存在于内存中的寄存器。
步骤4: 使用内存单元
- 如果
x在当前块内不再被引用,或找不到适合重用的寄存器,则将x的内存单元作为L。
实例应用
考虑赋值语句 d = (a - b) + (a - c) + (a - c),转换成三地址语句序列后,我们有:
t1 = a - b
t2 = a - c
t3 = t1 + t2
d = t3 + t2
假设只有 d 在基本块出口活跃,根据本节的代码生成算法,getReg 的调用将优化寄存器使用,最小化内存访问,提高代码执行效率。
例如,getReg 在处理 t1 = a - b 时,可能选择寄存器 R0 来存放 t1 的值,因为 a 不在 R0 中,会生成 MOV a, R0 和 SUB b, R0 的指令,之后寄存器描述更新为 R0 包含 t1 的值。
结论
getReg 函数的设计体现了对寄存器使用的深思熟虑,旨在通过最佳寄存器选择减少内存访问,优化代码执行效率。这种基于引用信息的简单寄存器分配策略,在很多情况下可以有效减少指令的总代价,如通过减少不必要的 MOV 指令。更复杂的 getReg 实现可能会进一步考虑变量的后续使用情况和操作符的交换性,以实现更高级的优化。
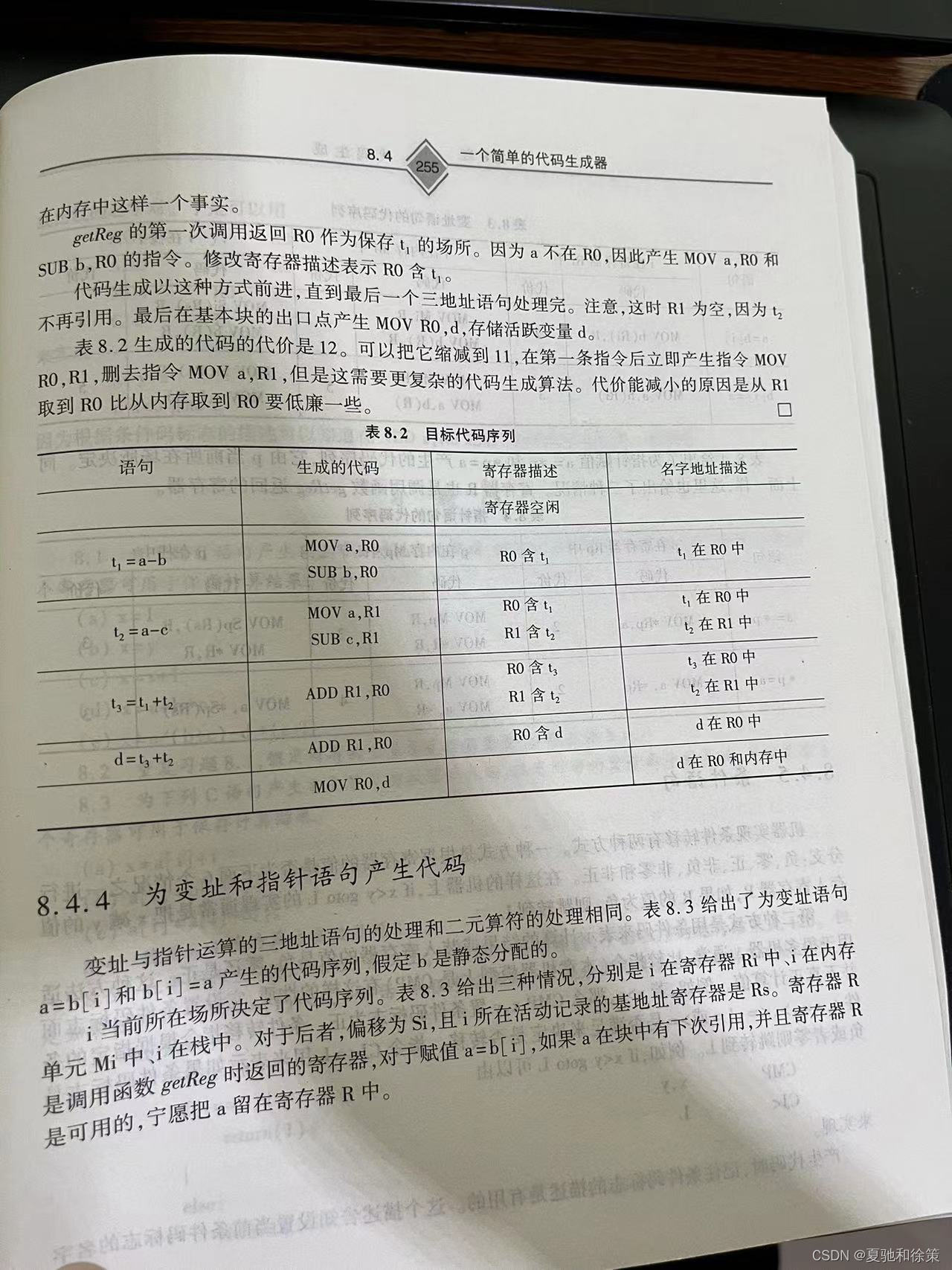
8.4.4 为变址和指针语句产生代码
变址和指针运算是程序设计中常见的操作,它们在数组和动态数据结构的处理中尤为重要。本节详细介绍了如何为变址语句 a = b[i] 和 b[i] = a,以及指针语句 a = *p 和 *p = a 生成目标代码。代码生成考虑了操作数 i 或 p 的不同存储位置,包括寄存器、内存单元和栈。
变址语句的代码生成
变址语句涉及到数组的索引操作。根据索引 i 的位置,生成代码的策略会有所不同。以下是不同情况下的代码序列及其代价:
i 在寄存器 Ri 中
- 对于
a = b[i]:直接使用寄存器Ri来访问数组b,代价较低。 - 对于
b[i] = a:同样利用Ri,生成相应的存储指令。
i 在内存 Mi 中
- 需要先将
i的值移入寄存器,然后再进行变址操作,导致较高的指令代价。
i 在栈中
- 需要通过栈顶指针
Rs和偏移Si来获取i的值,再进行变址操作,代价介于前两者之间。
指针语句的代码生成
指针语句涉及到间接寻址,同样根据指针 p 的位置采取不同的代码生成策略:
p 在寄存器 Rp 中
- 对于
a = *p或*p = a:直接通过寄存器Rp进行间接寻址,代价最低。
p 在内存 Mp 中
- 需要先将
p的值移入寄存器,然后执行间接寻址操作,指令代价增加。
p 在栈中
- 通过栈顶指针
Rs和偏移Sp来访问p,然后进行间接寻址,代价与内存情况相似。
在所有这些情况中,选择合适的寄存器(如果可能)对于减少指令代价至关重要。函数 getReg 的作用在这里再次被强调,它负责为存储计算结果的 a 或临时存储 p 的值选择最佳的寄存器。
结论
为变址和指针语句生成代码的过程体现了对寄存器和内存访问优化的需要。通过考虑变量所在的位置(寄存器、内存或栈),以及合理地利用寄存器,可以显著减少指令的执行代价,从而优化程序的执行效率。这一过程不仅需要对目标机器的指令集有深入理解,还需要对程序中变量的使用模式和存储位置有全面的考量。
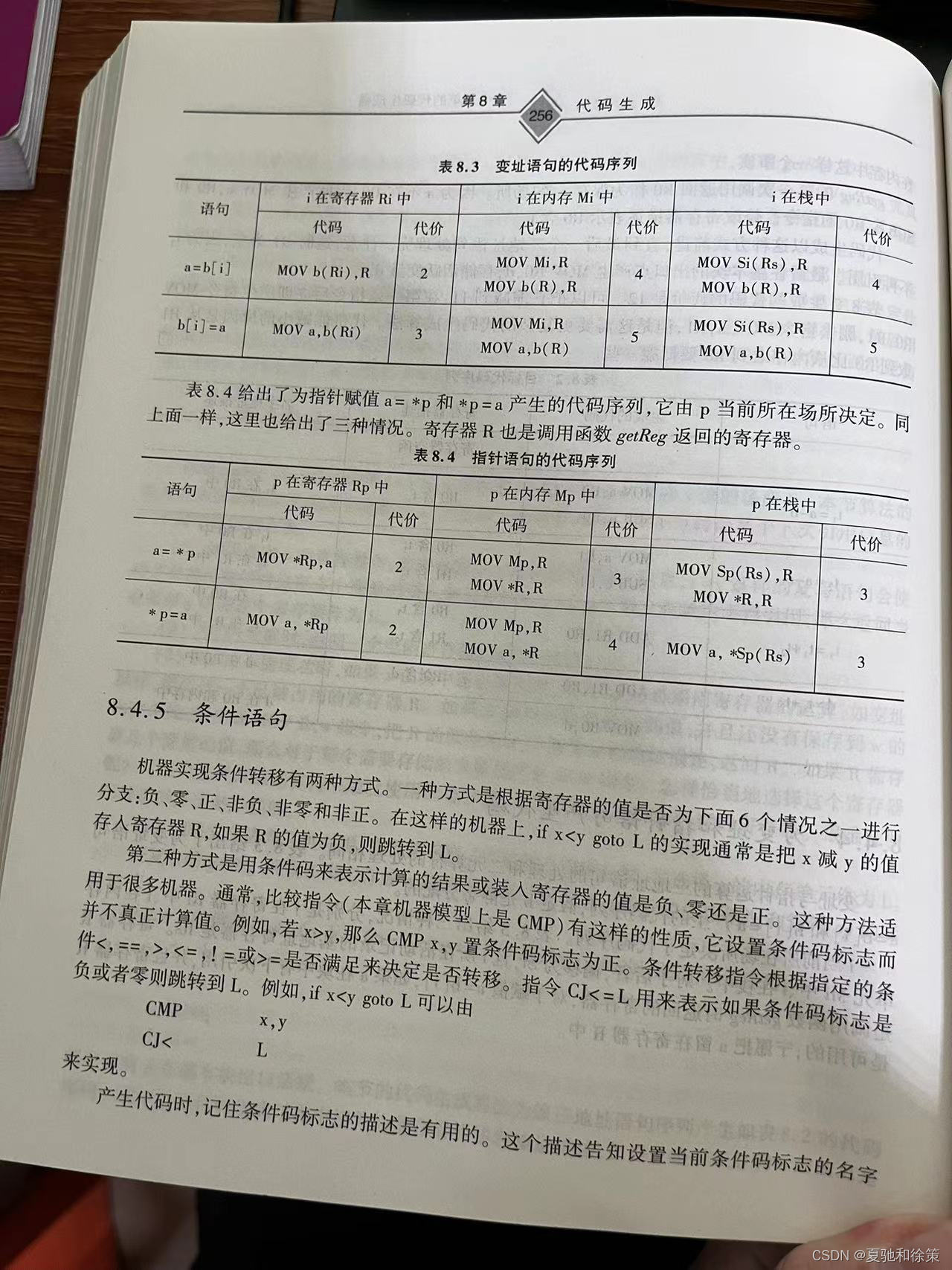
8.4.5 条件语句
条件语句是程序设计中常用的结构,用于根据特定条件控制程序的执行流程。在底层,条件转移的实现依赖于机器指令的特性。根据机器的不同,实现条件转移的方式主要分为两种:
1. 基于寄存器值的分支
在这种方式中,根据寄存器的值是否为特定情况(负、零、正、非负、非零、非正)之一来进行分支。例如,实现 if x < y goto L 的典型方法是将 x - y 的结果存入寄存器 R,如果 R 的值为负,则跳转到标签 L。这种方法直接依赖于算术运算的结果来决定跳转逻辑。
2. 基于条件码的分支
另一种方式是使用条件码(也称为状态标志)来表示最近的计算结果或装入寄存器的值是负、零还是正。很多机器采用这种方法,其中比较指令(如本章所讨论的机器模型上的 CMP 指令)设置条件码标志,但不实际计算值。例如,如果 x > y,则 CMP x, y 会设置条件码标志为正。
条件转移指令根据是否满足特定条件(如 <、==、>、<=、!=、>=)来决定是否进行跳转。例如,指令 CJ< L 表示如果条件码标志为负,则跳转到标签 L。因此,if x < y goto L 可以通过以下指令实现:
CMP x, y
CJ< L
在生成代码时,跟踪条件码标志的设置很重要。这种跟踪可以通过维护一个描述,记录了哪些操作设置了当前的条件码标志。这样,代码生成器可以有效地决定何时可以直接使用已设置的条件码,何时需要通过额外的比较指令来更新条件码。
总结
条件语句的底层实现展示了机器级指令如何用于实现高级编程语言中的控制流结构。通过精心设计的条件码或寄存器值分支逻辑,编译器能够将高级条件表达式转换为有效的机器代码,优化程序的执行路径。理解这一过程对于编译器设计者来说是至关重要的,它涉及到如何将程序的逻辑结构映射到特定硬件架构上,以实现高效的程序执行。





















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











