




 博客讨论了CF650F2 Flying Sort问题的两种优化解法,通过离散化和双关键字排序,寻找最少操作次数将数组排序。第一种方法采用动态规划在原数组上进行转移,复杂度为O(nlogn);第二种方法利用集合和栈维护最长连续子序列,同样为O(nlogn)复杂度。
博客讨论了CF650F2 Flying Sort问题的两种优化解法,通过离散化和双关键字排序,寻找最少操作次数将数组排序。第一种方法采用动态规划在原数组上进行转移,复杂度为O(nlogn);第二种方法利用集合和栈维护最长连续子序列,同样为O(nlogn)复杂度。
题意
有一个数组 {bi}\{b_i\}{bi},每次你可以选择一个元素放到最后面或者最前面,求将 {bi}\{b_i\}{bi} 排成不递减序列的最少次数。
{bi}\{b_i\}{bi} 可能有重复元素。 n≤2e5n\leq 2e5n≤2e5。
分析
由于这些数只和大小关系有关,我们先离散化一波,将值域变为 [1,n][1,n][1,n]。
观察发现,每个数如果要移动,最多只会移动一次。
那么,次数 = n - 不移动的数字个数。
我们考虑最大化不用移动的数字个数。
不用移动,意味着这些数在原数组中是有序的,而且值域上是连续的,而且每个数大于等于前一个数。
那我们把原数组按双关键字排序,先按值域,再按下标。
那么考虑我们选取的值域为 [x,y][x,y][x,y]。那么 [x+1,y−1][x+1,y-1][x+1,y−1] 中的所有数都是必选的。 xxx 和 yyy 中的数可以部分选,最优情况肯定是选 xxx 的前缀和 yyy 的后缀,如图。

其中,选的数必须满足下标单调增,因为这才能对应原数组中一个子序列。
接下来就是怎么使这个序列尽量长的问题了。
这个问题,八仙过海,各显神通,有各种做法。
下面我介绍一下我在 cfcfcf 上看到的简单奇妙写法。
第一种写法
直接在原数组上进行 dpdpdp。
令 fif_ifi 表示以 iii 为不移动序列的最后一个数的最大序列长度。
分别记 lasxlas_xlasx 和 firxfir_xfirx 为 xxx 上一次出现的位置和第一次出现的位置。
再记 cntxcnt_xcntx 和 totxtot_xtotx 为 xxx 总的出现次数和 xxx 当前的出现次数。
令 x=aix=a_ix=ai。
考虑转移,显然只能从 xxx 和 x−1x-1x−1 这些数进行转移:
- 如果 totx−1=cntx−1tot_{x-1}=cnt_{x-1}totx−1=cntx−1,说明 x−1x-1x−1 都出现完了, 那么一种选择是让 fi=ffirx−1+totx−1f_i=f_{fir_{x-1}}+tot_{x-1}fi=ffirx−1+totx−1,就是 iii 前面的数全是 x−1x-1x−1。
- 如果 lasx>0las_x>0lasx>0,那么一种转移是 fi=flasx+1f_i=f_{las_x}+1fi=flasx+1。也就是 xxx 接在上一个 xxx 后面(显然无论如何这是合法的)。
- 如果 lasx−1>0las_{x-1}>0lasx−1>0,这里考虑 x−1x-1x−1 还没满,那么 x−1x-1x−1 一定是作为不选择序列的最小的数,所以 fi=totx−1+1f_i=tot_{x-1}+1fi=totx−1+1。
这样就是全部的转移了。
复杂度是 O(nlogn)O(nlogn)O(nlogn) 的,因为要排序,dpdpdp 部分是 O(n)O(n)O(n) 的。
代码如下
#include <bits/stdc++.h>
using namespace std;
int read(){
int x, f = 1;
char ch;
while(ch = getchar(), ch < '0' || ch > '9') if(ch == '-') f = -1;
x = ch - '0';
while(ch = getchar(), ch >= '0' && ch <= '9') x = x * 10 + ch - 48;
return x * f;
}
const int N = 2e5 + 5;
int f[N], a[N], b[N], cnt[N], tot[N], fir[N], las[N];
int main(){
int i, j, x, n, m, T, ans;
T = read();
while(T--){
n = read(); ans = 0;
for(i = 1; i <= n; i++) a[i] = b[i] = read();
sort(b + 1, b + i);
m = unique(b + 1, b + n + 1) - b - 1;
for(i = 1; i <= n; i++) a[i] = lower_bound(b + 1, b + m + 1, a[i]) - b, cnt[a[i]]++;
for(i = 1; i <= n; i++){
x = a[i];
if(tot[x - 1] == cnt[x - 1]) f[i] = max(f[i], f[fir[x - 1]] + tot[x - 1]);
if(las[x]) f[i] = max(f[i], f[las[x]] + 1);
if(las[x - 1]) f[i] = max(f[i], tot[x - 1] + 1);
f[i] = max(f[i], 1);
ans = max(ans, f[i]);
las[x] = i;
if(!fir[x]) fir[x] = i;
tot[x]++;
}
printf("%d\n", n - ans);
for(i = 1; i <= n; i++) cnt[i] = tot[i] = f[i] = fir[i] = las[i] = 0;
}
return 0;
}
第二种写法
这个老哥按 {value,−index}\{value,-index\}{value,−index} 进行双关键字排序。
接下来,在排完序的数组中,我们要找的,就是一个最长的连续子序列,满足下图这种限制。(这个建议手完一发)

那么当插入一个数,我们要将所有不合法的数删除,如下图所示。
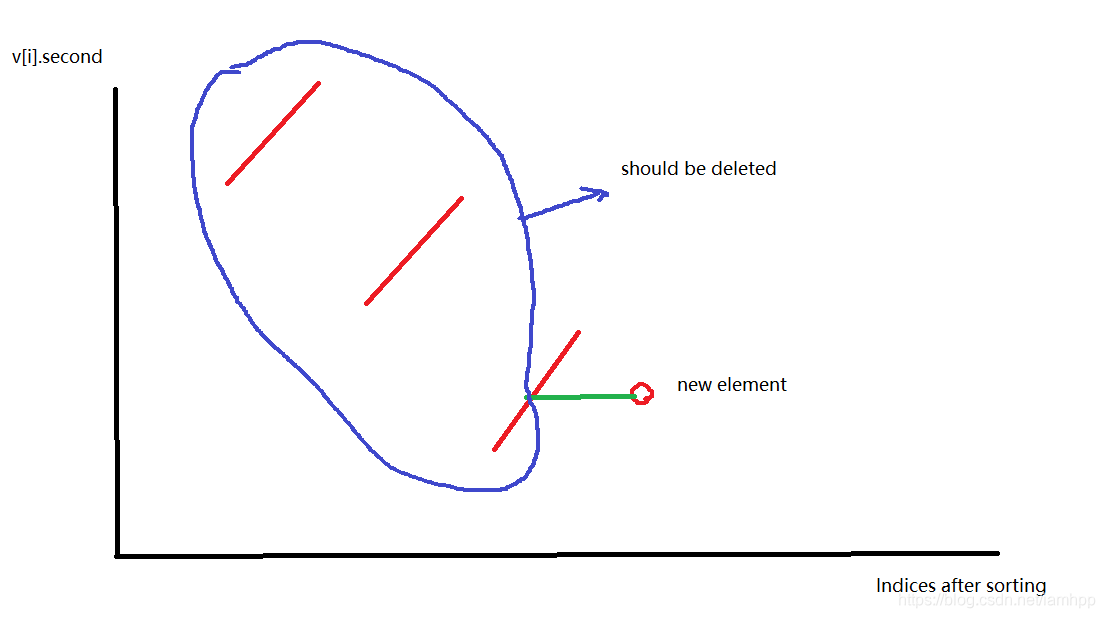
这个过程可以用一个 setsetset 和一个栈进行维护。
栈存的是当前值为 xxx 已经加入的数。
setsetset 存的是小于等于 x−1x-1x−1 的值中已经加入的数。
我们当前考虑的序列是 [j,i][j,i][j,i]。
那么当加入一个新的数时,我们要从 jjj 开始删掉数,直到 setsetset 中所有数大于 v[i].secondv[i].secondv[i].second。
具体还是看代码吧。
最后的复杂度是 O(nlogn)O(nlogn)O(nlogn) 的。
代码如下
#include <bits/stdc++.h>
using namespace std;
int read(){
int x, f = 1;
char ch;
while(ch = getchar(), ch < '0' || ch > '9') if(ch == '-') f = -1;
x = ch - '0';
while(ch = getchar(), ch >= '0' && ch <= '9') x = (x << 3) + (x << 1) + ch - 48;
return x * f;
}
const int N = 200005;
pair<int, int> a[N];
set<int> s;
int sta[N], top;
int main(){
int i, j, n, m, T, ans;
T = read();
while(T--){
s.clear();
n = read(); ans = 0;
for(i = 1; i <= n; i++) a[i] = {read(), -i};
sort(a + 1, a + i);
j = 1; top = 0;
for(i = 1; i <= n; i++){
if(a[i].first != a[i - top].first){
while(top) s.insert(sta[top--]);
top = 0;
}
while(s.size() && *s.begin() < a[i].second){
s.erase(a[j].second);
j++;
}
sta[++top] = a[i].second;
ans = max(ans, top + int(s.size()));
}
printf("%d\n", n - ans);
}
return 0;
}

















 11万+
11万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









