




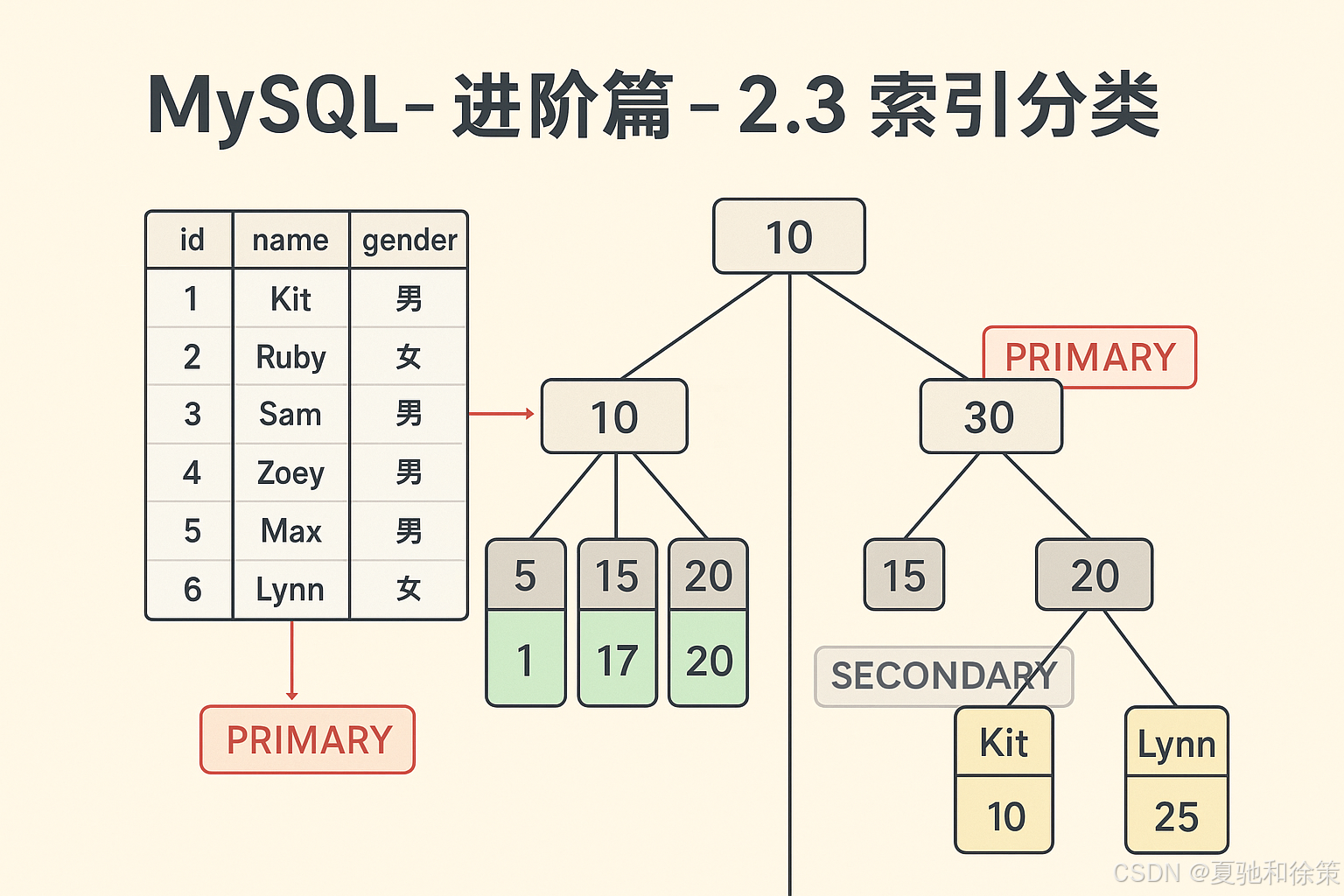
MySQL - 进阶篇 - 2.3 索引分类
在 MySQL 数据库中,索引是提升查询效率的核心机制。它不仅能加快数据检索速度,还能在约束数据唯一性和实现全文搜索等方面发挥作用。本节将深入介绍索引的分类、InnoDB 存储引擎中的聚集索引与二级索引,以及它们在查询中的具体应用。
2.3.1 索引分类
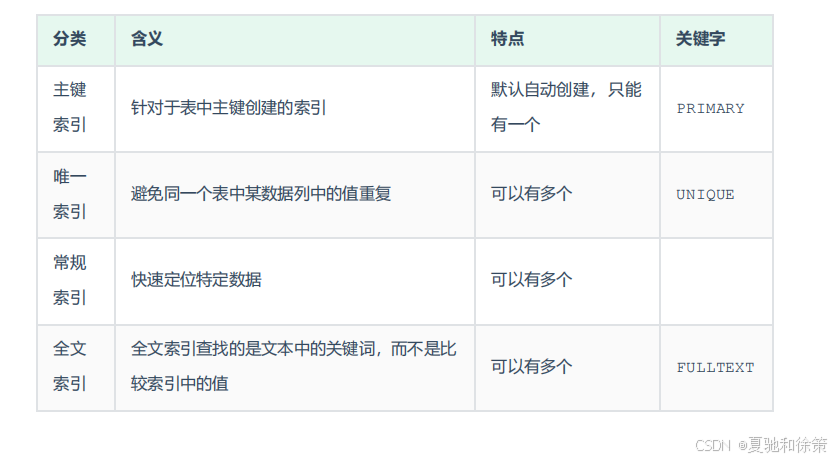
在 MySQL 数据库中,索引的具体类型主要分为以下几类:
-
主键索引(PRIMARY KEY)
-
含义:针对表中主键创建的索引。
-
特点:默认自动创建,每个表只能有一个主键索引。
-
关键字:
PRIMARY
-
-
唯一索引(UNIQUE)
-
含义:避免同一个表中某数据列的值重复。
-
特点:可以有多个唯一索引。
-
关键字:
UNIQUE
-
-
常规索引(INDEX)
-
含义:用于快速定位特定数据。
-
特点:可以有多个。
-
关键字:无
-
-
全文索引(FULLTEXT)
-
含义:全文索引查找的是文本中的关键字,而不是单纯的字段值。
-
特点:可以有多个,主要应用于
CHAR、VARCHAR、TEXT类型的列。 -
关键字:
FULLTEXT
-
2.3.2 聚集索引 & 二级索引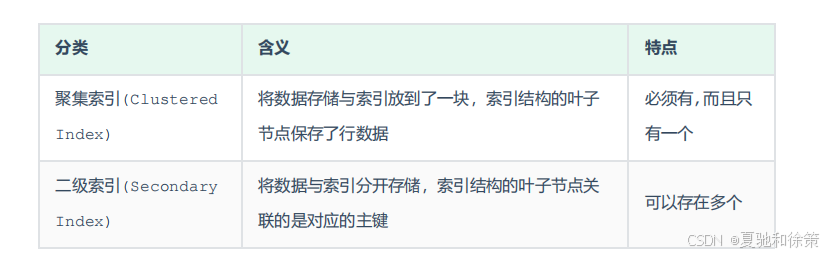
在 InnoDB 存储引擎中,根据索引的存储形式,又可以分为以下两类:
-
聚集索引(Clustered Index)
-
含义:将数据存储与索引放到了一块,索引结构的叶子节点直接保存了完整的行数据。
-
特点:每张表必须有且只有一个聚集索引。
-
-
二级索引(Secondary Index)
-
含义:数据和索引分开存储,索引结构的叶子节点保存的是该字段值对应的主键值。
-
特点:可以存在多个二级索引。
-
聚集索引的选取规则
-
如果存在主键,主键索引就是聚集索引。
-
如果不存在主键,将使用第一个唯一(
UNIQUE)索引作为聚集索引。 -
如果表没有主键,或没有合适的唯一索引,则 InnoDB 会自动生成一个
rowid作为隐藏的聚集索引。
聚集索引与二级索引的结构
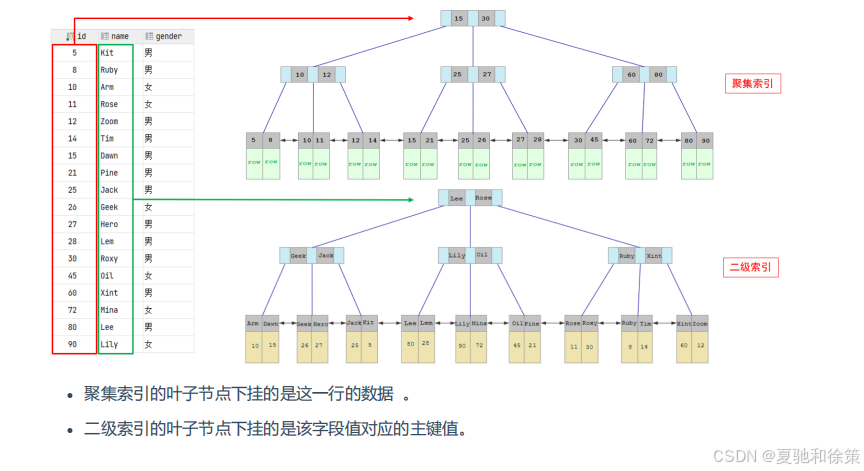
-
聚集索引的叶子节点下挂的是这一行的数据。
-
二级索引的叶子节点下挂的是该字段值对应的主键值。
例如,id 字段是主键索引,而 name 字段有一个二级索引: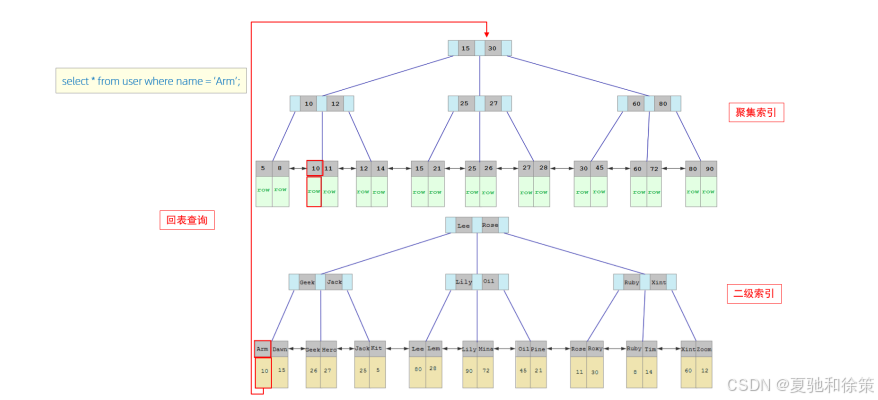
-
当根据
id查询时,会直接通过聚集索引获取整行数据。 -
当根据
name查询时,会先通过二级索引找到对应的主键值,再去聚集索引中根据主键值获取整行数据。
这种“先走二级索引,再回到聚集索引查数据”的过程称为 回表查询。
回表查询过程示例
执行如下 SQL:
select * from user where name = 'Arm';
查询过程如下:
-
由于是根据
name字段进行查询,所以先到name字段的二级索引中匹配Arm。
在二级索引中只能查到Arm对应的主键值10。 -
因为
select *需要返回整行数据,所以此时需要再根据主键值10,到聚集索引中查找10对应的完整行记录。 -
最终获取到主键为
10的完整行数据,并返回。
这就是 回表查询 的典型过程。
思考题 1
以下两条 SQL 语句,哪条执行效率更高?为什么?
A. select * from user where id = 10; B. select * from user where name = 'Arm';
-
答案:
-
A 的执行性能更高。
-
原因是:
-
A 语句直接走聚集索引,能一步返回完整数据;
-
B 语句则需要先通过二级索引查找,再根据主键回到聚集索引进行查找,多了一次回表过程。
-
-
思考题 2
InnoDB 主键索引的 B+Tree 高度能有多高?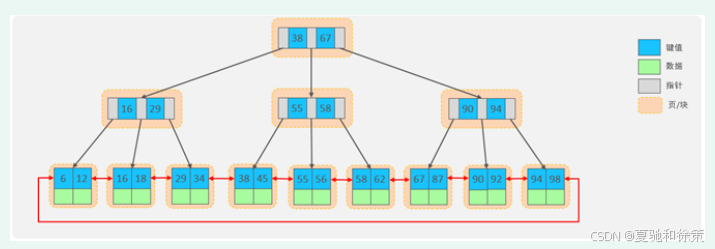
假设:
-
一行数据大小为 1KB;
-
一页可以存储 16 行数据;
-
InnoDB 的指针占 6 字节;
-
主键为
bigint,占 8 字节。
高度为 2 的情况
-
公式:
n * 8 + (n + 1) * 6 = 16 * 1024 -
算出
n ≈ 1170 -
总存储:
1171 * 16 = 18736 -
即高度为 2 时,可以存储约 1.8 万条记录。
高度为 3 的情况
-
总存储:
1171 * 1171 * 16 ≈ 21939856 -
即高度为 3 时,可以存储约 2200 万条记录。
换句话说,InnoDB 的 B+Tree 高度通常不会太高,哪怕数据量在千万级别,树的高度也往往只在 2~3 层之间,因此查询效率极高。
总结
-
索引分类分为主键索引、唯一索引、常规索引、全文索引。
-
InnoDB 存储引擎中的索引分为聚集索引和二级索引。
-
回表查询是二级索引查找后必须回到聚集索引获取完整数据的过程。
-
B+Tree 的层级极低,即便数据量达到千万级别,查找路径也非常短,因此 MySQL 在大规模数据下依旧能保持高效查询。
理解
1. 理论理解
索引本质上是数据库为了减少磁盘 I/O、提升数据检索速度而构建的辅助数据结构,它的原理与我们熟知的书籍目录类似。MySQL 常用的 B+Tree 索引具有以下几个关键点:
-
主键索引:每张表只能有一个,叶子节点直接存放整行数据,因此主键索引同时就是聚集索引。
-
二级索引:叶子节点存储的不是完整行,而是主键值,需要通过“回表”才能获取到完整数据。
-
回表查询:是二级索引查找的必然过程,当查询字段不是覆盖索引时,必然要回到聚集索引再次检索。
-
B+Tree 的高度:由于扇出极大,通常即便数据量达到千万级别,B+Tree 的高度依然维持在 2~3 层,保证了查询性能的稳定。
因此,索引优化的核心逻辑就是减少回表次数、控制树高度、提升命中率。
2. 大厂实战理解
在大规模业务场景下,索引不仅是“加速工具”,更是系统可扩展性与稳定性的保障。以下是一些大厂(BAT、字节、Google、NVIDIA、OpenAI 等)的实战经验:
-
覆盖索引(Covering Index)
-
为避免回表,很多公司会在高频查询的 SQL 上建立联合索引,让索引本身覆盖查询所需的字段。
-
例如:
select id, name from user where name = 'Arm',如果(name, id)建立了联合索引,则可直接返回结果,无需回表。 -
这种方式广泛应用于电商类订单系统和推荐系统的检索层。
-
-
索引下推(Index Condition Pushdown, ICP)
-
在 MySQL 5.6 引入后,索引下推能将过滤条件提前下放到存储引擎层,减少无效回表操作。
-
在大厂高并发系统中,尤其是用户画像检索和日志分析中,ICP 能显著降低磁盘 I/O。
-
-
冷热数据分层 + 索引精简
-
在字节、Google 等公司的海量数据系统中,表往往会被拆分为冷热数据两部分。
-
热数据表索引更激进,以支撑高频查询;冷数据表则索引更保守,以节省存储和写入开销。
-
索引数量过多会拖慢写操作,因此索引设计常常是读写权衡的产物。
-
-
分布式索引与倒排索引结合
-
对于搜索、推荐和日志场景,单纯依赖 B+Tree 已不足够。大厂会结合 倒排索引(Inverted Index) 与 分布式存储(如 ElasticSearch、ClickHouse、甚至内部定制存储)。
-
MySQL 的全文索引(FULLTEXT)只是基础版本,而大厂通常会使用 ES 等专业引擎替代。
-
-
索引与分区/分表结合
-
当单表数据量突破亿级时,索引扇出虽能维持 B+Tree 的低高度,但单机 IO 压力巨大。
-
BAT 等公司会采取分库分表 + 全局路由索引的方式,将局部索引与全局检索系统结合,避免单点瓶颈。
-
总结
-
从理论角度,索引是控制磁盘 I/O 的核心工具,关键在于理解 聚集索引与二级索引的关系,以及 回表查询 的代价。
-
从大厂实战角度,索引设计是性能、成本、可扩展性的三重博弈:
-
在高并发系统中用 覆盖索引 + 索引下推 优化单次查询;
-
在大数据场景下用 冷热分层 + 分布式倒排索引 保证系统的整体可用性。
-
大厂面试题
面试题 1
什么是聚集索引和二级索引?它们在 InnoDB 中有什么区别?
参考答案:
聚集索引(Clustered Index)的叶子节点存放的是整行数据,因此它和数据行紧密绑定,每张表只能有一个聚集索引,一般就是主键索引。
二级索引(Secondary Index)的叶子节点存放的是对应的主键值,而不是完整行,因此通过二级索引查数据时,往往需要根据主键值回到聚集索引再查一次,这就是“回表查询”。
区别在于:聚集索引查找一步到位,而二级索引查找可能需要两步。
面试题 2
为什么 select * from user where id = 10 会比 select * from user where name = 'Arm' 更快?
参考答案:
因为 id 是主键,查询会直接走聚集索引,一次索引查找就能拿到整行数据;而 name 字段是二级索引,查询时需要先匹配二级索引拿到主键值,再回表到聚集索引去查完整数据,因此多了一次 I/O。
面试题 3
什么是回表查询?如何优化?
参考答案:
回表查询指的是通过二级索引查找到主键值后,还需要回到聚集索引中再查一次数据的过程。
优化方式主要有:
-
使用 覆盖索引(Covering Index),让查询字段包含在索引中,避免回表;
-
使用 联合索引(如
(name, age)),满足查询条件直接命中索引; -
在查询频率极高的情况下,也可以考虑冗余存储,将查询需要的字段建立在同一个索引上。
面试题 4
MySQL InnoDB 的 B+Tree 高度一般有多高?为什么它能保证高性能?
参考答案:
B+Tree 高度通常不超过 3 层。即便是千万级数据,B+Tree 高度也只在 2~3 层之间。
这是因为:
-
B+Tree 的分支因子很大(扇出高),每一层能容纳成千上万条数据指针;
-
因此数据查找时磁盘 I/O 次数非常少,最多 2~3 次就能定位到目标数据,保证了高性能。
面试题 5
你如何在实际业务中使用索引来优化 SQL 查询性能?
参考答案:
-
针对高频查询的字段建立索引,尤其是 where 条件、join 条件、group by、order by 中的字段。
-
使用 覆盖索引,减少回表次数。
-
使用 索引下推(ICP),让过滤条件尽可能在存储引擎层完成,降低无效回表。
-
对于大数据表,采用 冷热分表,热表索引设计更激进,冷表索引设计更保守。
-
在搜索和推荐场景下,引入 倒排索引(如 ES)替代 MySQL 的全文索引,提高性能。
好,我来为你写这一节的 大厂场景题,结合电商和推荐系统的真实业务场景,既体现索引原理,又考察工程化优化思路。
大厂场景题
场景题 1:电商订单查询优化
背景:
在电商系统中,order 表结构如下:
CREATE TABLE orders (
id BIGINT PRIMARY KEY,
user_id BIGINT NOT NULL,
product_id BIGINT NOT NULL,
order_status TINYINT NOT NULL,
create_time DATETIME NOT NULL,
update_time DATETIME NOT NULL,
INDEX idx_user_status (user_id, order_status),
INDEX idx_time (create_time)
);
业务中存在以下高频查询:
select * from orders where user_id = 10001 and order_status = 1 order by create_time desc limit 10;
问题:
-
你认为当前索引是否合理?如何进一步优化?
参考答案:
当前查询条件涉及 user_id、order_status,并按 create_time 排序,虽然已经有 (user_id, order_status) 索引,但 order by create_time desc 没有被利用,会触发文件排序。
优化方式是建立 联合索引 (user_id, order_status, create_time),这样既能过滤条件,又能利用索引顺序完成排序,避免额外排序开销。
在大厂电商业务里,这种优化能显著减少慢查询和排序压力。
场景题 2:推荐系统用户画像检索
背景:
在推荐系统中,有一张 user_profile 表:
CREATE TABLE user_profile (
user_id BIGINT PRIMARY KEY,
gender TINYINT,
age INT,
tags VARCHAR(255),
last_active DATETIME,
INDEX idx_gender_age (gender, age),
FULLTEXT INDEX idx_tags (tags)
);
现在有一个需求:快速查找“女性、25 岁以下、兴趣包含 sports 的用户”,SQL 如下:
select user_id from user_profile
where gender = 0 and age < 25 and match(tags) against('sports');
问题:
-
你认为该查询是否高效?如何优化?
参考答案:
该查询走了 组合条件 + 全文索引,但由于 match ... against 只针对 tags 字段生效,MySQL 会先利用全文索引筛选兴趣包含 sports 的用户,再在结果集上过滤 gender 和 age,存在额外开销。
优化方式:
-
如果标签查询频繁,应该将
gender、age字段也纳入 倒排索引系统(如 ElasticSearch); -
如果必须在 MySQL 内解决,可以考虑将高频的
(gender, age)条件与tags分层存储,减少无效匹配; -
业务层可增加缓存(Redis),存储热门标签用户集合。
这种 混合索引 + 专用引擎分流 的方式是大厂在搜索推荐中常见的解决方案。
场景题 3:日志系统的高并发查询
背景:
在一个分布式日志采集系统中,日志表 logs 结构如下:
CREATE TABLE logs (
id BIGINT PRIMARY KEY,
app_id INT NOT NULL,
log_level TINYINT NOT NULL,
log_time DATETIME NOT NULL,
message TEXT,
INDEX idx_app_time (app_id, log_time),
INDEX idx_level_time (log_level, log_time)
);
常见查询:
select * from logs where app_id = 200 and log_time between '2025-09-01' and '2025-09-10';
问题:
-
为什么有时查询很快,有时很慢?如何解决?
参考答案:
因为日志量巨大,log_time 范围查询可能落到大量数据页,若数据冷热混合在一起,I/O 压力会非常大。
大厂常见优化手段:
-
分区表:按
log_time进行分区,只扫描对应分区,避免全表扫描; -
冷热分层:热日志放在单独表或 Redis 中,冷日志归档到 HDFS/ClickHouse;
-
覆盖索引:若只查
app_id和log_time,则设计(app_id, log_time)覆盖索引避免回表。
这样可以显著提升查询的稳定性和可预期性。
总结
-
电商订单场景:联合索引解决排序和过滤。
-
推荐系统场景:倒排索引 + 分布式搜索引擎是必然趋势。
-
日志系统场景:分区与冷热分层是高并发下的常见手段。
好,那我来写这一节的 面试官追问,延伸出一些大厂面试中常见的深挖问题,以及回答思路。
面试官追问
追问 1
问题: 既然 MySQL 的全文索引性能有限,为什么不直接用 ElasticSearch,而要在 MySQL 里加索引?
参考答案:
选择 MySQL 或 ES 是一种架构权衡:
-
MySQL 优势在于 强事务性(ACID)、数据一致性和维护成本低,适合结构化数据查询。
-
ES 优势在于 倒排索引 + 分布式检索,适合全文搜索与复杂的模糊查询。
-
在实际业务中,冷热分层是常见做法:热数据走 MySQL 索引保证事务一致性,冷数据走 ES 做搜索和分析。这样既能保证交易类系统的数据一致性,又能满足推荐、搜索场景下的灵活检索。
追问 2
问题: 你提到“覆盖索引”可以避免回表查询,能举一个具体的 SQL 场景吗?
参考答案:
例如查询用户的下单次数:
select user_id, count(*)
from orders
where order_status = 1
group by user_id;
如果对 (order_status, user_id) 建立联合索引,那么所有需要的数据都能从索引中获取,不必回表查询整行记录。这就是覆盖索引的典型场景。
在大厂订单系统中,类似的统计类查询非常常见,覆盖索引能显著提升性能。
追问 3
问题: 如果表数据达到数十亿级别,单靠索引还能解决性能问题吗?
参考答案:
单表数十亿级别时,索引本身仍能维持 B+Tree 的低高度,但瓶颈在于 存储与 I/O。此时大厂会采用:
-
分库分表:通过 Sharding 将数据水平拆分,局部索引维持较小规模;
-
全局路由索引:引入中间件(如 Mycat、ShardingSphere)管理全局索引与路由;
-
冷热分层存储:热数据保留在 MySQL,冷数据迁移到分布式引擎(ClickHouse/Hive)。
换句话说,索引不是无敌的,需要与架构设计结合。
追问 4
问题: InnoDB 为什么选择 B+Tree 作为索引结构,而不是 B 树或 Hash?
参考答案:
-
B 树:非叶子节点可以存储数据,范围查询效率较低,磁盘 I/O 开销大。
-
B+Tree:所有数据存在叶子节点,叶子节点通过链表连接,范围查询和顺序扫描性能极佳。
-
Hash 索引:适合精确匹配,但不支持范围查询,不稳定在高并发下。
因此 InnoDB 选择 B+Tree,是在范围查询和高并发场景下的最佳平衡。
追问 5
问题: 如果一个字段既有唯一索引,又被设为主键,会发生什么?
参考答案:
-
主键索引是聚集索引,每表只能有一个;
-
唯一索引是二级索引,可以有多个。
如果某字段被设为主键,那么它的唯一索引会被 MySQL 自动合并为主键索引,不会重复创建。
在大厂数据库表设计中,通常不会显式给主键再建唯一索引,因为那是冗余的。
✅ 总结:
面试官的追问,核心考察的是索引的边界和架构上的取舍,而不仅仅是死记硬背概念。回答时要注意:
-
小场景 → 讲索引的优化技巧(覆盖索引、联合索引、索引下推);
-
大场景 → 上升到架构层面(分库分表、冷热分层、引入搜索引擎)。



















 1033
1033

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











