




🚀 MySQL - 进阶篇 - 2.2 索引结构详解
在 MySQL 中,索引结构的选择直接关系到查询效率和存储性能。本节将深入解析 MySQL 中的常见索引结构及其适用场景。
🔍 2.2.1 索引结构概述
MySQL 的索引是在存储引擎层实现的,不同的引擎支持的索引类型如下:
| 索引类型 | 描述 |
|---|---|
| B+Tree索引 | 最常见,适用于绝大部分查询场景 |
| Hash索引 | 基于哈希表,仅适用于等值查询,不支持范围查询 |
| R-Tree(空间索引) | MyISAM引擎专用,处理地理空间数据 |
| Full-text全文索引 | 用于全文检索,适合文本关键词匹配 |
| 存储引擎 | B+Tree索引 | Hash索引 | R-Tree索引 | Full-text索引 |
|---|---|---|---|---|
| InnoDB | ✅ 支持 | ❌ | ❌ | ✅(5.6+) |
| MyISAM | ✅ 支持 | ❌ | ✅ 支持 | ✅ 支持 |
| Memory | ✅ 支持 | ✅ 支持 | ❌ | ❌ |
💡 注意:除非特别说明,MySQL 中所说的“索引”默认指的是 B+Tree。
✅ 理论理解
MySQL 的索引结构是在存储引擎层实现的,常见索引类型包括:
| 索引类型 | 特点 |
|---|---|
| B+Tree | 支持范围查询、排序、最常用 |
| Hash | 仅支持等值查询,查询极快但不支持范围 |
| R-Tree | 处理空间/地理位置类数据(GIS) |
| Full-text | 针对文本关键词搜索,基于倒排索引 |
不同引擎对索引类型的支持也不同:
| 存储引擎 | B+Tree | Hash | R-Tree | Full-text |
|---|---|---|---|---|
| InnoDB | ✅ | ❌ | ❌ | ✅(5.6+) |
| MyISAM | ✅ | ❌ | ✅ | ✅ |
| Memory | ✅ | ✅ | ❌ | ❌ |
注意:我们默认提到“索引”,多数指 B+Tree。
🧠 企业级实战理解
-
字节跳动/阿里:Feed流、商品列表、评论系统等大量用 InnoDB + B+Tree 实现分页与排序,支持大规模数据下的区间查询。
-
Google:内部的 Spanner/BigTable 使用变种树(B+Tree/Bε-Tree)结构管理分布式索引。
-
NVIDIA:在 AI 推理平台中构建元数据查询索引,也倾向于 B+Tree 结构,便于批量顺序读取。
-
OpenAI:API 请求日志、模型元数据分析中,同样采用顺序访问友好的索引方案(如 B+Tree 或 KV RocksDB 的跳表)。
🌲 2.2.2 二叉树与红黑树的局限性
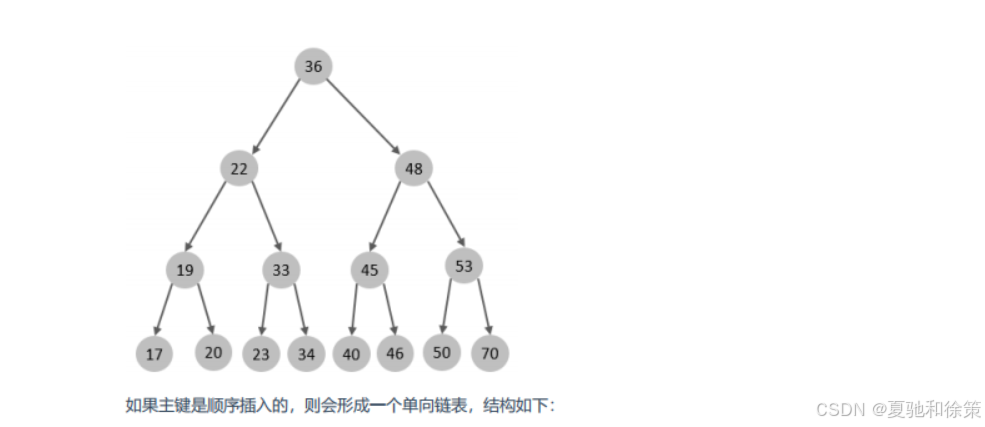
✅ 理想的二叉搜索树
如果索引使用普通二叉搜索树,它的结构在最理想情况下如下图所示:
❌ 顺序插入时的链表化问题
如果数据是顺序插入的,会退化为链表结构,查询效率大大下降:

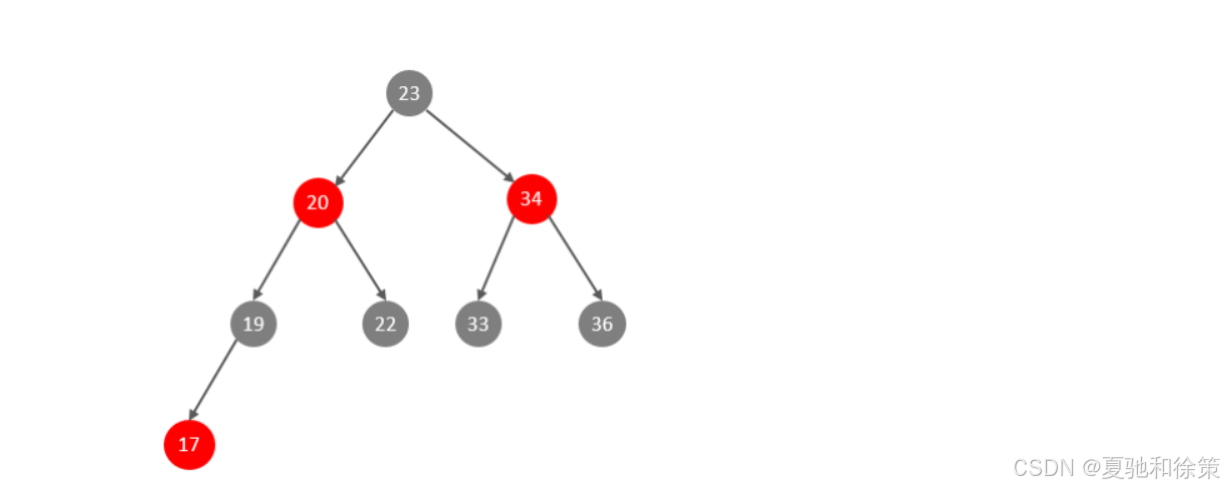
✅ 红黑树的自平衡优化
为了解决退化问题,可以采用红黑树进行平衡调整,但它仍是二叉结构,层级依旧较深:
❗总结:
-
二叉树和红黑树在大数据量下层级太深,访问速度慢
-
适用于内存场景,不适合磁盘 I/O 场景
✅ 理论理解
-
普通二叉树在顺序插入数据时容易退化成链表,导致查询性能变差。
-
红黑树虽然自平衡,但仍是二叉结构,大数据量下层级深,磁盘 I/O 次数多,不适合 MySQL 这种磁盘为主的数据库。
🧠 企业级实战理解
-
字节跳动(ByteDance):内部数据库组件早期曾用红黑树处理内存索引,但放弃用于磁盘级索引,因为树深不可控。
-
Google/Spanner:设计上避免二叉树结构,倾向于高度平衡多叉树(如 B+Tree)来减少延迟。
-
国内大型项目如美团、腾讯广告系统:都采用多路平衡树(如 B+Tree)或跳表作为底层索引结构。
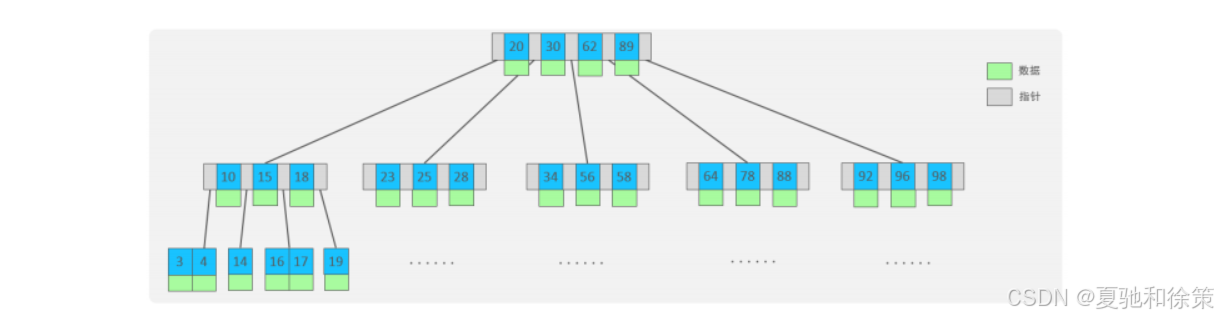
🌳 2.2.3 B-Tree(B树)
B树是一种多路平衡查找树,每个节点可以存放多个 key 和子指针,减少树的高度。
🔧 示例(5阶 B-Tree):
-
每个节点最多有 5 个子节点(4 个 key)
-
关键字超出上限时中间元素上升,发生分裂
-
所有节点(包括非叶节点)都存储数据
🧠 理论理解:
-
B-Tree 是多叉平衡查找树,每个节点可包含多个 key 和指针。
-
减少树的高度,提升整体查找效率。
-
所有节点(包括内部节点)都可存储数据。
🏢 企业实战:
-
阿里 PolarDB 在部分小表使用改进型 B-Tree 存储主键索引,结构扁平查找快。
-
腾讯云 TDSQL 也使用变种 B-Tree 结构作为引擎索引实现高并发数据访问。
-
Google Spanner(全球分布式数据库) 通过多路树结构管理跨区域数据分布。
🌲 2.2.4 B+Tree(MySQL主力索引结构)
B+Tree 是 B-Tree 的变种,MySQL 中的 InnoDB 存储引擎主要采用 B+Tree。
✅ 结构说明:
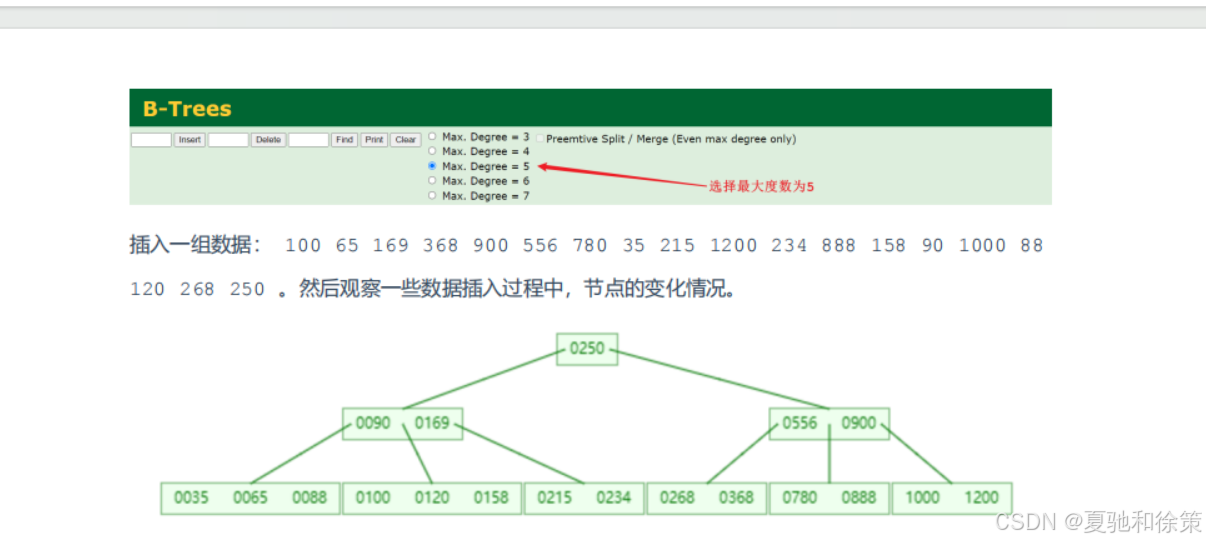
-
**绿色部分:**索引部分,只负责定位
-
**红色部分:**叶子节点,存储所有数据
-
所有数据只出现在叶子节点中
-
叶子节点形成有序链表
🔁 可视化网站:
🆚 B-Tree 对比:
| 对比点 | B-Tree | B+Tree |
|---|---|---|
| 数据存储位置 | 所有节点 | 仅叶子节点 |
| 范围查询支持 | 一般 | ✅ 链表结构更高效 |
| 内部节点是否存数据 | ✅ | ❌ 仅作为索引存在 |
🧠 理论理解:
-
所有数据仅出现在叶子节点
-
非叶子节点仅做索引指引,查找路径稳定
-
所有叶子节点形成一个有序链表,支持区间、范围、排序查询
🏢 企业实战:
-
InnoDB 存储引擎就是用 B+Tree 做主键索引 + 二级索引;
-
字节跳动 Feishu(飞书)文档系统: 用 B+Tree 索引对文档内容分片管理,结合倒排索引提升全文检索效率。
-
谷歌 Firestore / Spanner: 使用 B+Tree-like 结构快速定位大规模键值。
-
OpenAI ChatGPT 系统: embedding 向量 ID 索引采用带链表的 B+Tree 管理,提升批量检索性能。
🚀 2.2.4.1 MySQL 优化版 B+Tree
为了提升区间访问和排序性能,MySQL 对经典 B+Tree 进行了优化:
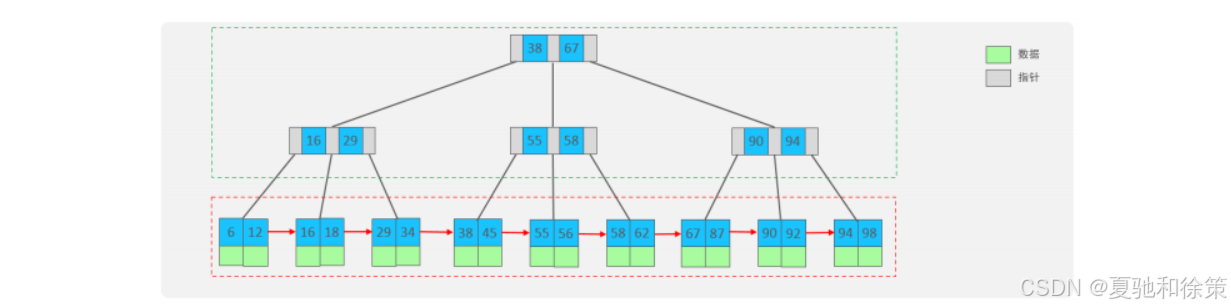
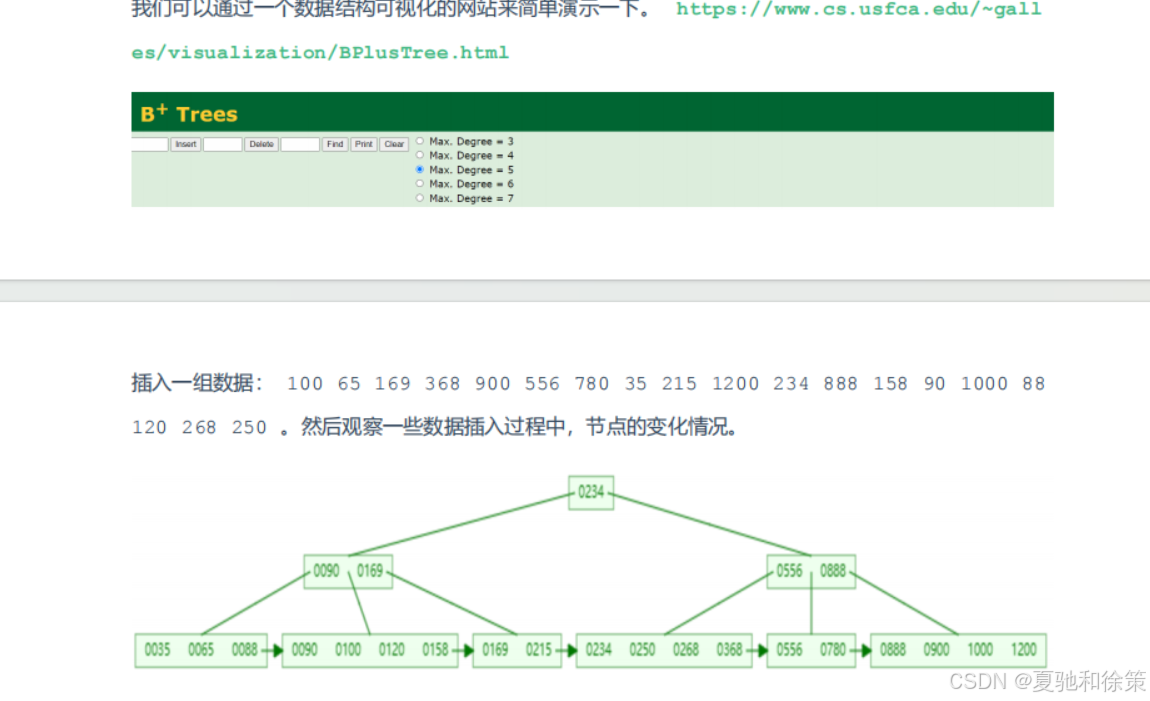
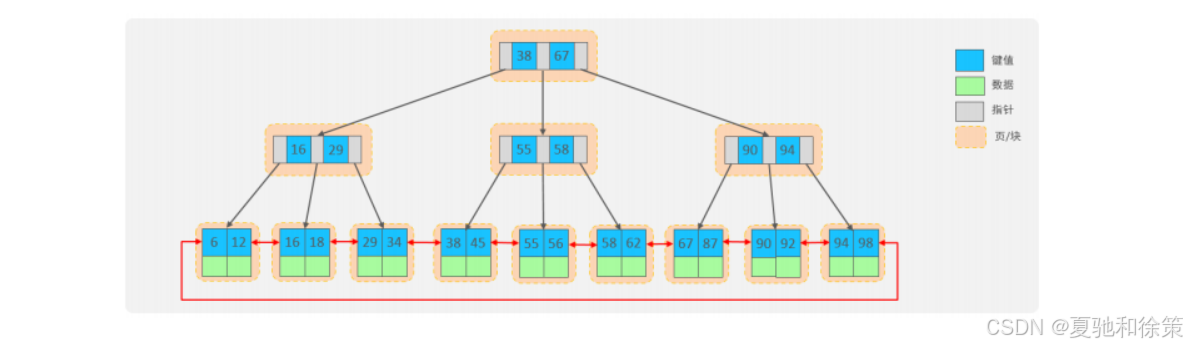
-
在叶子节点之间加入顺序指针
-
提高了区间访问性能,便于排序操作
🧠 理论理解:
MySQL 进一步优化了经典 B+Tree,引入顺序指针,在叶子节点之间建立链表连接。
优点:
-
支持范围查询、快速分页
-
提高排序查询性能(如 ORDER BY)
🏢 企业实战:
-
阿里搜索系统: 搜索结果分页依赖顺序链表 B+Tree,高性能返回区间段。
-
腾讯社交圈推荐系统: 使用优化版 B+Tree 查找好友关系链,避免范围扫表。
-
百度贴吧: 评论系统通过顺序指针优化评论分页和楼中楼回帖查找。
🔐 2.2.5 Hash 索引
🏗️ 结构
Hash 索引使用哈希函数将 key 转为 hash 值,映射到固定槽位:
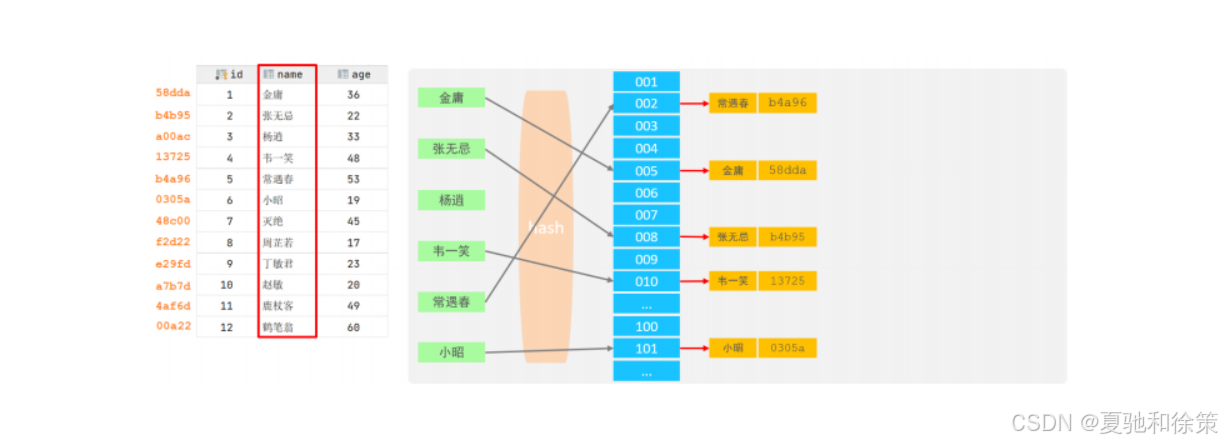
-
相同 hash 值产生冲突,用链表解决
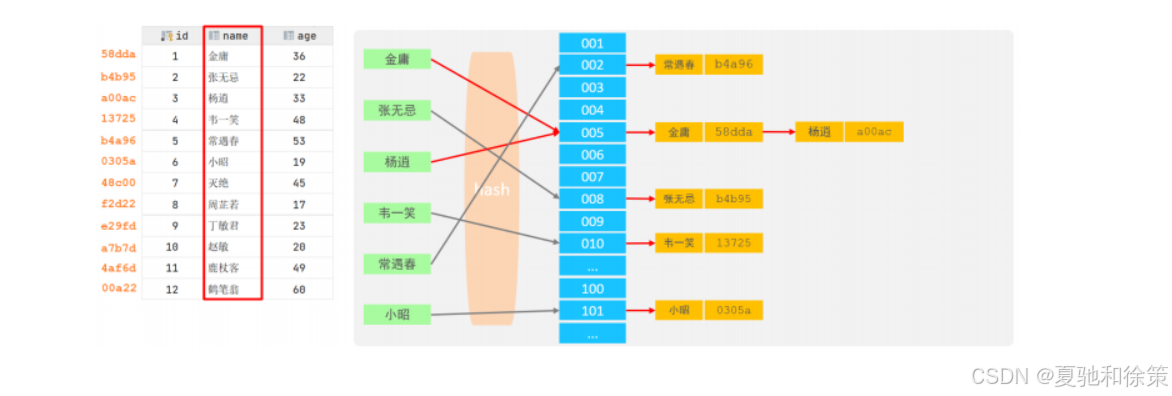
🌟 特点
-
✅ 查询效率高:通常只需一次定位
-
❌ 仅支持等值查询:
=,IN -
❌ 不支持范围查询:
<,>,BETWEEN -
❌ 不支持排序
💾 存储引擎支持
| 存储引擎 | 是否支持 Hash 索引 |
|---|---|
| InnoDB | ✅(自适应 hash) |
| Memory | ✅ 支持 |
| MyISAM | ❌ 不支持 |
🧠 理论理解:
-
采用哈希函数将 key 转换成 hash 值,映射到 hash 表槽位
-
仅支持等值查询,不支持范围
-
遇到 hash 冲突使用链表解决
特点总结:
| 特性 | 说明 |
|---|---|
| 查询范围 | ❌ 不支持范围(BETWEEN、>、<) |
| 查询效率 | ✅ 等值查询性能极高 |
| 排序/索引排序 | ❌ 不支持 |
🏢 企业实战:
-
Memory 存储引擎使用 hash 索引: 用于短生命周期数据,如实时排行榜、临时统计缓存。
-
字节跳动广告引擎: 热 key 广告位匹配采用自适应 hash 表提升广告投放速度。
-
Google Dremel / BigQuery: 查询优化使用 hash map 对 query plan 节点做索引映射。
-
OpenAI 调用链优化器: 在服务间建立调用 ID → handler 的 hash 快速定位表。
💡 思考题
为什么 InnoDB 存储引擎使用 B+Tree 而不是 Hash?
答:
-
B+Tree 层级低,磁盘访问次数少,适合范围查询
-
B+Tree 支持顺序遍历,适用于
ORDER BY -
B+Tree 的索引结构适合构建二级索引(Secondary Index)
🎯 思考题:为什么 InnoDB 不选 Hash 而选 B+Tree?
答:
-
支持范围查询: B+Tree 可有序遍历,不受 hash 冲突限制
-
支持排序: hash 无序,无法满足
ORDER BY -
空间利用率高: hash 表槽位存在大量冲突或空闲,B+Tree 利用率更高
-
事务一致性: B+Tree 更适合 InnoDB 的事务回滚与恢复机制
📚 总结:
-
🚫 二叉树、红黑树层级深,IO频繁,不适合磁盘索引
-
✅ B+Tree 是 MySQL 索引的首选:高效、支持排序、区间查询
-
⚠️ Hash 索引仅适用于特定场景(Memory表 / 等值查询)
💡 总结 + 企业实践建议:
| 数据结构 | 理论优点 | 适用场景(企业实践) |
|---|---|---|
| 二叉树 | 实现简单,查询快(小数据量) | JVM、缓存淘汰策略(如 LinkedHashMap) |
| 红黑树 | 自平衡,稳定性好 | HashMap 冲突处理、Java TreeSet/TreeMap 底层 |
| B-Tree | 多路分支,层级低 | 小型数据库或嵌入式系统如 SQLite |
| B+Tree | 查询稳定,支持范围、排序 | ✅ MySQL InnoDB、Google Spanner、字节文档系统、飞书文档 |
| Hash | 精确定位快 | 🔥 缓存命中、热点数据访问、内存临时索引如排行榜、分布式缓存系统 |
如需学习可视化,推荐:



















 2622
2622

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











