








🌱《1.4 归纳偏好》:为什么“简单”的模型更值得信赖?
在我们学习机器学习时,总会遇到一个经典困惑:
“为什么同样的训练数据,不同算法学出的模型居然不一样?”
这就引出了本节的关键概念——归纳偏好(Inductive Bias)。它不仅关系到模型的选择和效果,更是我们深入理解学习算法“性格”的一把钥匙。
🍉 西瓜模型与归纳偏好初探
先从一个直观例子说起——西瓜分类。
训练集告诉我们哪些瓜是好瓜,但当遇到一个新样本(比如:色泽=青绿,根蒂=蜷缩,敲声=沉闷),就会出现分歧:
-
模型A说:只要“根蒂=蜷缩”就行,判断为好瓜;
-
模型B说:不仅“根蒂=蜷缩”,还得“敲声=沉闷”,才是好瓜;
-
模型C则更严格:还要求“敲声=浊响”才符合好瓜标准。
这三种模型在训练集上的表现完全一致,但对新样本的判断却天差地别。那么,哪一个模型才是“更优”的呢?
这时,我们就不能仅靠数据,还要依赖算法对假设的偏好——这就是归纳偏好。
🤖 什么是归纳偏好?
归纳偏好指的是:算法在面对多个与训练数据一致的模型时,它更偏向选择哪类模型的“倾向性”。
它是算法内在的一种“价值观”或“选择偏好”。
比如:
-
有的算法偏爱“特殊规则”(尽可能详细、具体);
-
有的算法偏爱“通用规则”(更具概括性);
-
有的算法偏爱“结构简单”的模型。
这就像人做决策时会凭经验、直觉、信念做判断一样,算法也需要“倾向”去打破等价模型的僵局。
没有归纳偏好的算法会怎样?它在训练集等价的多个模型之间犹豫不决,每次都随机选一个,那预测结果就毫无稳定性、也没有意义。
✂️ 奥卡姆剃刀:简单之美
在机器学习中,一个最常被采纳的偏好原则是:
奥卡姆剃刀原则(Occam's Razor):“在所有能解释数据的假设中,选择最简单的那个。”
比如回归问题中,假设我们要找到一条曲线拟合图中样本点:
-
曲线A平滑简洁;
-
曲线B虽然也拟合了样本点,但弯弯绕绕、复杂得多。
在图 1.3 中,这两个曲线都能通过训练数据,但我们通常更信任曲线A,因为它“更简单、更自然”。
这也是算法的一种归纳偏好:选择结构更简单、规则更清晰的模型,认为它更有泛化能力。
📉 但现实有“反例”:没有免费的午餐!
你可能会说,那我以后都选简单模型不就好了?但等等,这时候就要提到另一个著名定理:
没有免费的午餐定理(No Free Lunch Theorem, NFL)
它告诉我们:
在所有可能的问题中,任何两个学习算法的平均性能是一样的。
换句话说,如果你不知道你面临的是什么问题,那所有算法都差不多,甚至“随机猜”也不会比“高智商算法”差。
图 1.4(b) 就展示了这样一种情况:虽然曲线A在训练集上表现很好,但测试集上反而曲线B更准确。也就是说,你偏好的模型,并不一定总是对的。
⚖️ 决定性因素:归纳偏好是否与问题匹配
那是不是归纳偏好就没用了?不是!
NFL定理背后的前提是——所有问题都是“等概率”的,但现实并不是这样:
-
实际应用中,我们只关注一类问题;
-
比如西瓜分类问题中,某些属性(如“根蒂=蜷缩”)更常见;
-
而另一些情况(如“根蒂=硬挺 且 敲声=清脆”)几乎不会出现。
所以,如果你的算法偏好“根蒂=蜷缩”,它就比喜欢“根蒂=硬挺”的算法表现更好!
结论是:归纳偏好并不是错,而是“必须有”!但它能否奏效,取决于是否与你的问题匹配。
✅ 总结:归纳偏好就是算法的“性格”
我们可以这样理解归纳偏好:
| 类比对象 | 对应概念 |
|---|---|
| 人的信念/价值观 | 归纳偏好 |
| 不同性格的人 | 不同算法 |
| 相同的经历(训练数据) | 不同的选择(模型) |
归纳偏好告诉我们:
-
为什么学习算法必须做出选择;
-
为什么“简单”模型常被偏好;
-
为什么不能脱离具体任务谈算法优劣;
-
为什么 NFL 定理看似“打击人”,实则是“点醒人”——不要空谈模型优劣,而要看具体任务。
🤔 思考题
-
你在学习中遇到过“多个模型都看起来合理”的情况吗?你是怎么选择的?
-
你更偏好“复杂但细致”的模型,还是“简单但概括”的模型?为什么?
-
如果你是一种算法,你希望自己的归纳偏好是怎样的?
如果你觉得这篇文章对你有启发,欢迎点赞、收藏、关注我的博客专栏《机器学习导论》📘!
下一节,我们将从数学角度推导归纳偏好与期望误差之间的关系,敬请期待!
📘《1.4 归纳偏好(下)》:从数学公式理解“没有免费的午餐”
在上一篇中,我们了解了“归纳偏好”的直觉含义和它在模型选择中的关键作用。但如果你像我一样,想更深入地理解它在数学上是如何体现的,那就让我们从公式出发,看一看“归纳偏好”的数学根源,并最终导出著名的——
✅ 没有免费的午餐定理(No Free Lunch Theorem)
📌 1. 学习算法的误差分析框架
设我们有:
-
一个输入空间 $\mathcal{X}$(比如所有可能的瓜)
-
一个假设空间 $\mathcal{H}$(所有模型)
-
一个真实目标函数 $f$(我们想学的“真理”)
-
一个学习算法 $\mathcal{A}$(根据训练集 $X$ 得到假设 $h$)
那么,对于某个测试样本 $x$,如果学习算法在 $x$ 上预测错了,也就是 $h(x) \ne f(x)$,我们说它在该点上犯了错误。
对所有测试样本 $x \notin X$ 的总误差为:
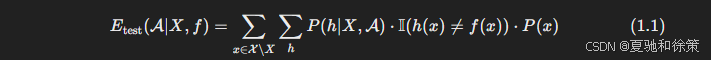
其中:
-
$P(h|X, \mathcal{A})$ 是算法 $\mathcal{A}$ 在训练集 $X$ 下产生假设 $h$ 的概率
-
$\mathbb{I}(\cdot)$ 是指示函数,条件为真时取 1,否则取 0
🧮 2. 推导:对所有目标函数 $f$ 的平均误差
我们考虑最极端的情况:目标函数 $f$ 可以是任何 $f: \mathcal{X} \to {0,1}$,也就是说我们不对“世界规律”做任何假设(这是 NFL 的前提)。
于是我们对所有可能的 $f$ 取均匀平均,即每个 $f$ 发生的概率相等。此时,对算法 $\mathcal{A}$ 在所有目标函数下的平均测试误差为:
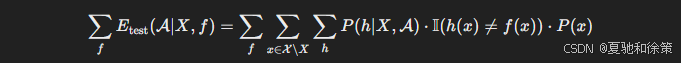
将求和顺序调换,可得:
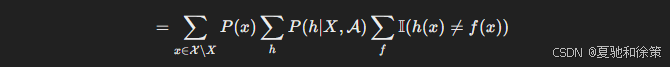
考虑分类问题,$f(x)$ 可以为 0 或 1,那么 $\sum_f \mathbb{I}(h(x) \ne f(x)) = 2^{|\mathcal{X}| - 1}$,因为一半的函数 $f$ 在 $x$ 上与 $h$ 不一致。
所以最终推导得到:

这个结果不依赖于具体的算法 $\mathcal{A}$,说明了一个令人惊讶的事实:
所有算法的平均误差相同!
🧊 3. 没有免费的午餐定理(NFL)的结论
公式 (1.3) 概括为:
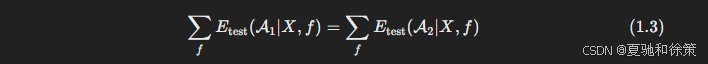
无论你的算法多聪明(如深度学习、迁移学习),或者多笨拙(比如随机猜测),在所有可能的问题平均下来,它们的期望误差是一样的。
这就是:
⚠️ 没有免费的午餐定理:No Free Lunch Theorem
— 若对所有可能问题一视同仁,则没有哪种学习算法是“更好”的。
🧠 那我们为什么还在研究学习算法?
因为,现实世界远非“所有问题等可能”!
我们只关注自己面临的具体问题,比如:
-
西瓜熟不熟
-
图像中是否有人
-
用户喜不喜欢这部电影
这些问题在现实中有明确结构、规律,世界不是“混乱的”。所以:
✅ 如果你的归纳偏好与问题匹配,那么你可以比别人做得更好。
比如西瓜问题:
-
如果我们知道“根蒂=蜷缩”的瓜通常是好瓜,那偏好这类特征的算法显然更有效;
-
而偏好“根蒂=硬挺”且“敲声=清脆”的假设可能根本就找不到合适样本。
✅ 总结:有偏才有优势
-
没有“万能算法”,但在特定任务中,合适的归纳偏好可以脱颖而出;
-
NFL 告诉我们别追求“通用最优”,而要关注特定问题下的“局部最优”;
-
所以,研究算法的意义在于:找到最适合特定问题的那一个偏好与结构。
正如一句话所说:“并不是世界没有模式,而是你选错了模型。”
如果你看懂了这一节,恭喜你!你不仅理解了机器学习的数学基础,还获得了判断“什么算法更适合什么任务”的能力!
下一节,我们将进入“经验误差与结构风险最小化”,也就是理解为什么深度学习这么强大的理论基础——敬请期待!




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











