



基于改进鹈鹕算法优化支持向量机的数据分类预测(IPOA-SVM) 改进鹈鹕算法IPOA改进点为加入混沌映射、反向差分进化和萤火虫扰动,加快鹈鹕算法的收敛速度,避免鹈鹕算法陷入局部最优 改进鹈鹕算法IPOA优化支持向量机的超参数cg 鹈鹕算法POA在知网检索结果较少,改进鹈鹕算法IPOA更是少之又少,适合PAPER
在数据分类预测的领域里,支持向量机(SVM)一直是个非常实用的工具。不过呢,SVM 的超参数选择可是个让人头疼的事儿,选得不好,模型的性能就大打折扣。最近我发现了一种结合改进鹈鹕算法(IPOA)来优化支持向量机的方法,感觉还挺有意思的,今天就来和大家唠唠。
鹈鹕算法(POA)
鹈鹕算法是一种新型的智能优化算法,灵感来源于鹈鹕群体的捕食行为。但是,在知网检索的时候会发现关于它的研究结果比较少。这也说明它还有很大的探索空间。POA 算法和其他智能算法一样,是通过模拟鹈鹕捕食的过程来寻找最优解。不过,它也有自己的小毛病,比如收敛速度可能会比较慢,还容易陷入局部最优。
改进鹈鹕算法(IPOA)
为了解决 POA 的这些问题,研究人员对它进行了改进,提出了 IPOA。IPOA 主要有三个改进点,分别是加入混沌映射、反向差分进化和萤火虫扰动。
混沌映射
混沌映射可以让算法在搜索空间里更均匀地分布初始点,避免一开始就陷入局部最优的陷阱。下面是一个简单的 Logistic 混沌映射的 Python 代码:
import numpy as np
def logistic_chaos(x0, n):
x = np.zeros(n)
x[0] = x0
for i in range(1, n):
x[i] = 4 * x[i-1] * (1 - x[i-1])
return x
# 示例
x0 = 0.5
n = 100
chaos_sequence = logistic_chaos(x0, n)
print(chaos_sequence)代码分析:这个函数接受初始值 x0 和序列长度 n 作为输入。在函数内部,通过 Logistic 映射的公式 x[i] = 4 x[i-1] (1 - x[i-1]) 生成混沌序列。这样生成的序列具有随机性和遍历性,可以帮助算法更好地探索搜索空间。
反向差分进化
反向差分进化可以增强算法的全局搜索能力。简单来说,它会根据当前种群的信息生成反向种群,然后在这两个种群中选择更优的个体,这样可以让算法更快地收敛到全局最优解。
萤火虫扰动
萤火虫扰动就像是给算法加了点“兴奋剂”,让它在搜索过程中更有活力。它模拟了萤火虫的发光行为,通过扰动当前最优解,避免算法陷入局部最优。
IPOA 优化支持向量机的超参数
支持向量机有两个重要的超参数 c 和 g,它们对模型的性能影响很大。IPOA 就是用来优化这两个超参数的。下面是一个简单的使用 IPOA 优化 SVM 超参数的伪代码:
初始化 IPOA 种群
while 未达到终止条件 do
计算每个个体的适应度值(使用 SVM 模型的准确率作为适应度)
更新 IPOA 种群(加入混沌映射、反向差分进化和萤火虫扰动)
选择最优个体
end while
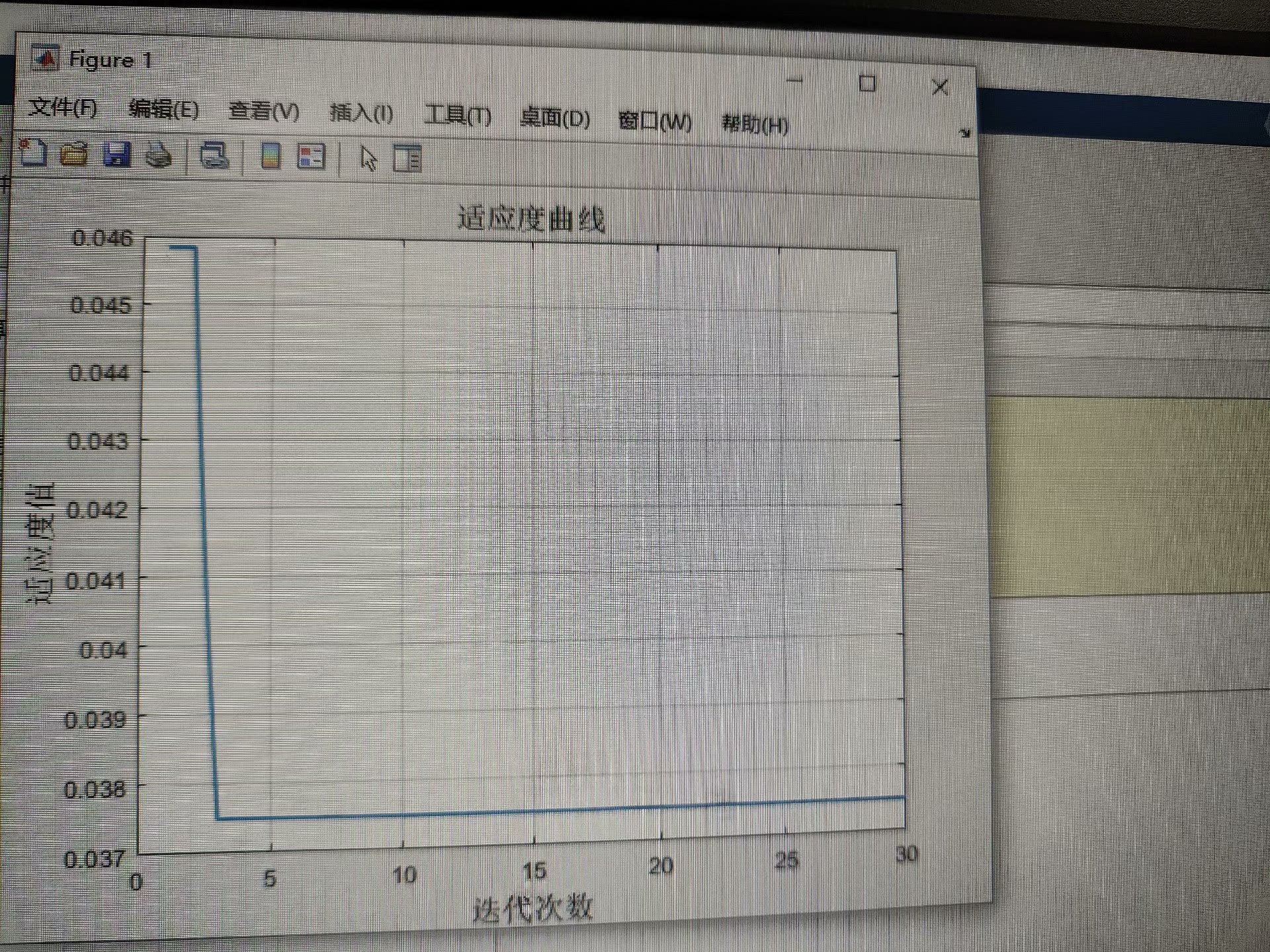
使用最优个体对应的超参数 `c` 和 `g` 训练 SVM 模型代码分析:在这个伪代码中,首先初始化 IPOA 种群,然后在每一轮迭代中计算每个个体的适应度值,这里用 SVM 模型的准确率来衡量。接着更新种群,通过加入前面提到的三个改进点,让种群不断进化。最后选择最优个体,用它对应的超参数来训练 SVM 模型。
总结
基于改进鹈鹕算法优化支持向量机的数据分类预测是一种很有潜力的方法。IPOA 通过加入混沌映射、反向差分进化和萤火虫扰动,加快了鹈鹕算法的收敛速度,避免了陷入局部最优。而且目前关于鹈鹕算法和改进鹈鹕算法的研究比较少,所以这个方向很适合写论文。如果你也对数据分类预测感兴趣,不妨试试这个方法。
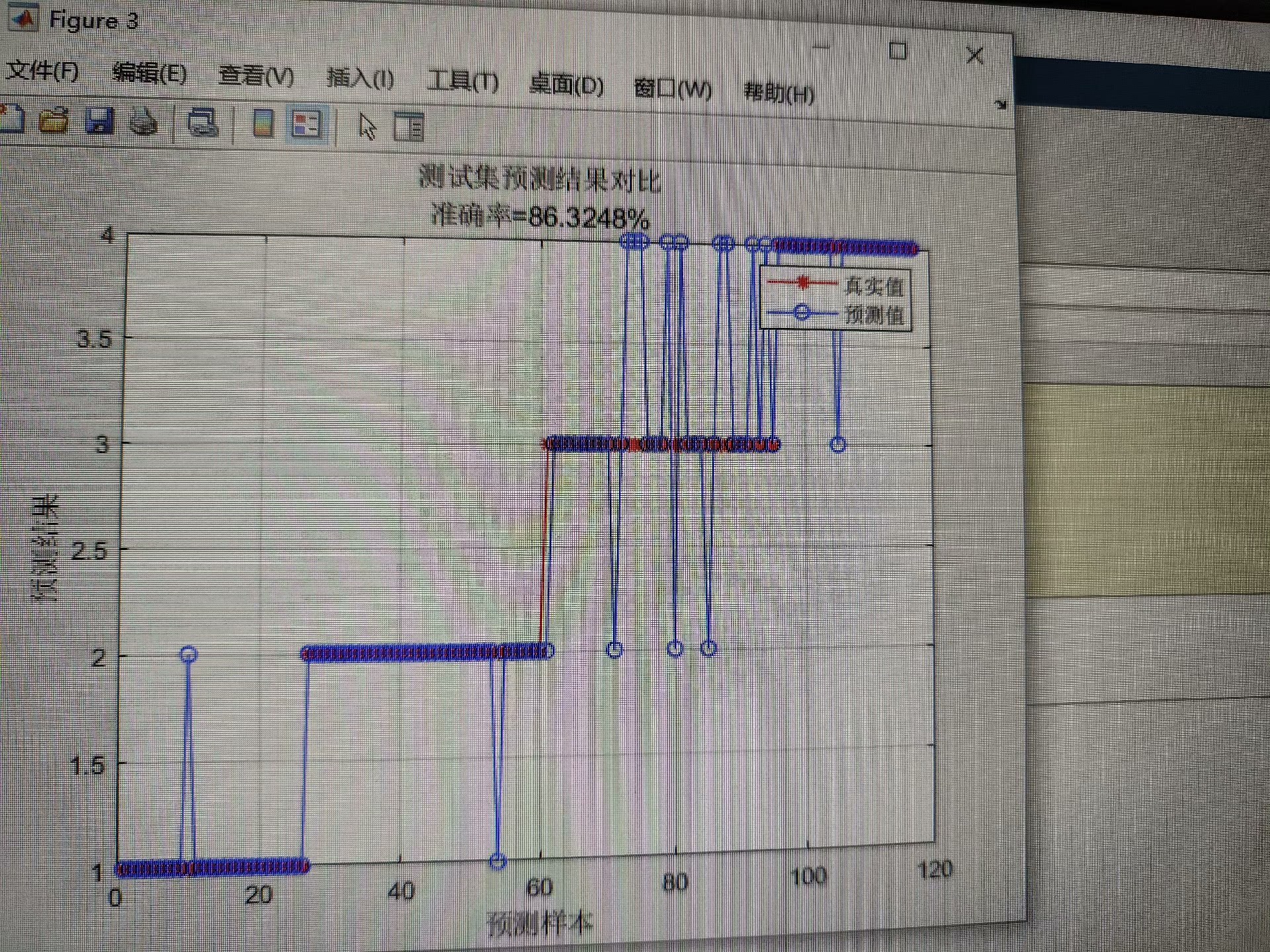
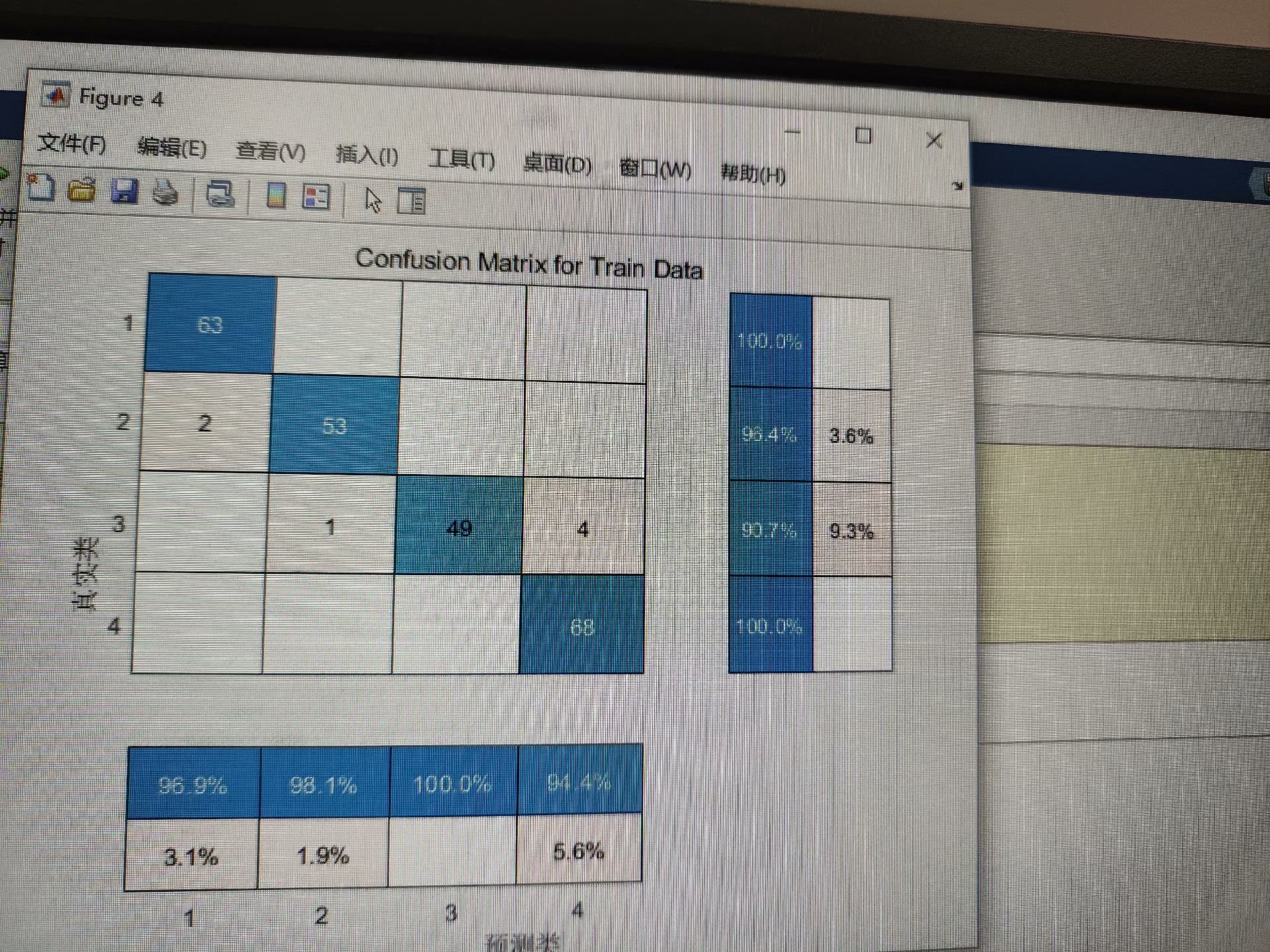
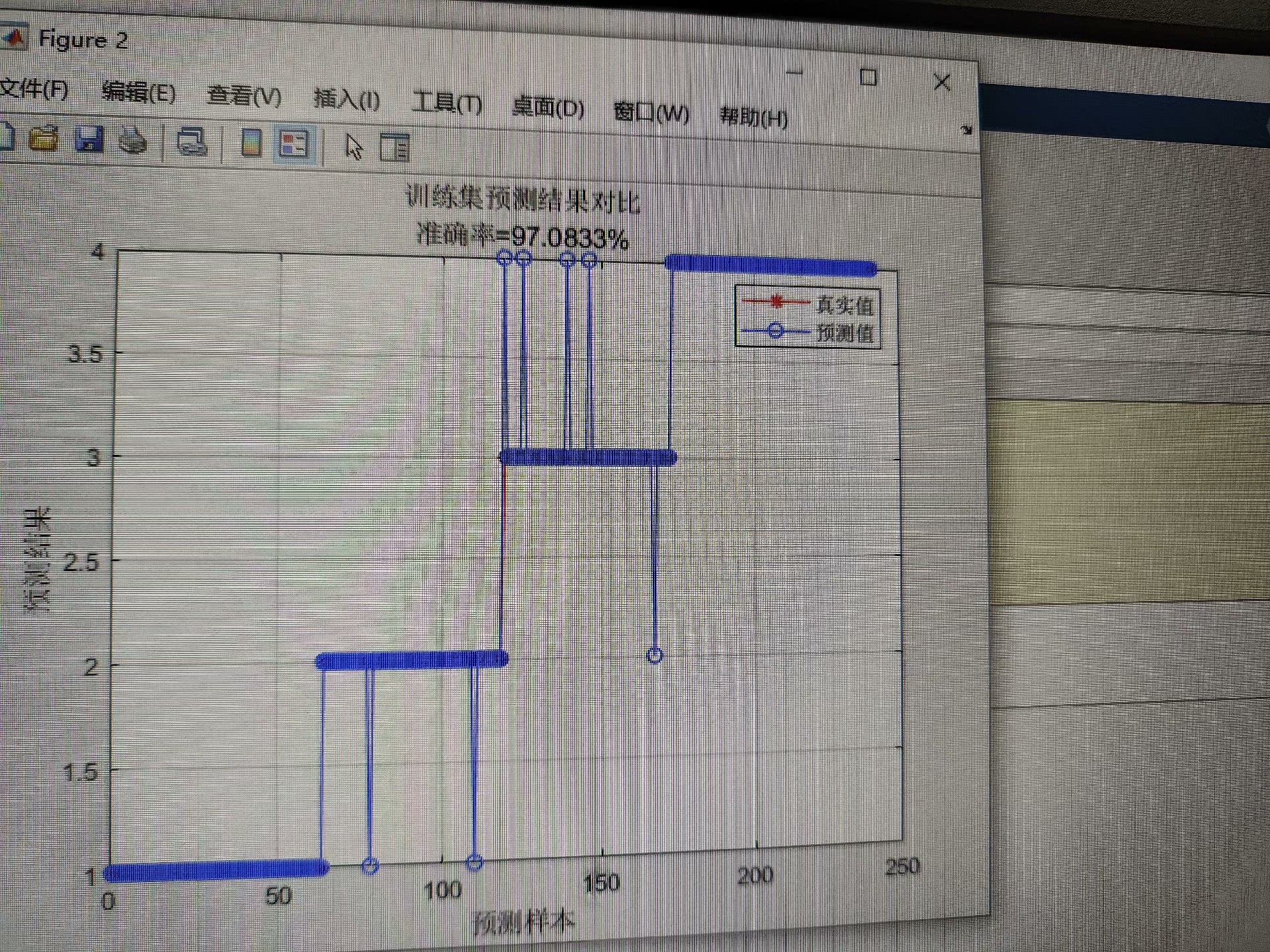

















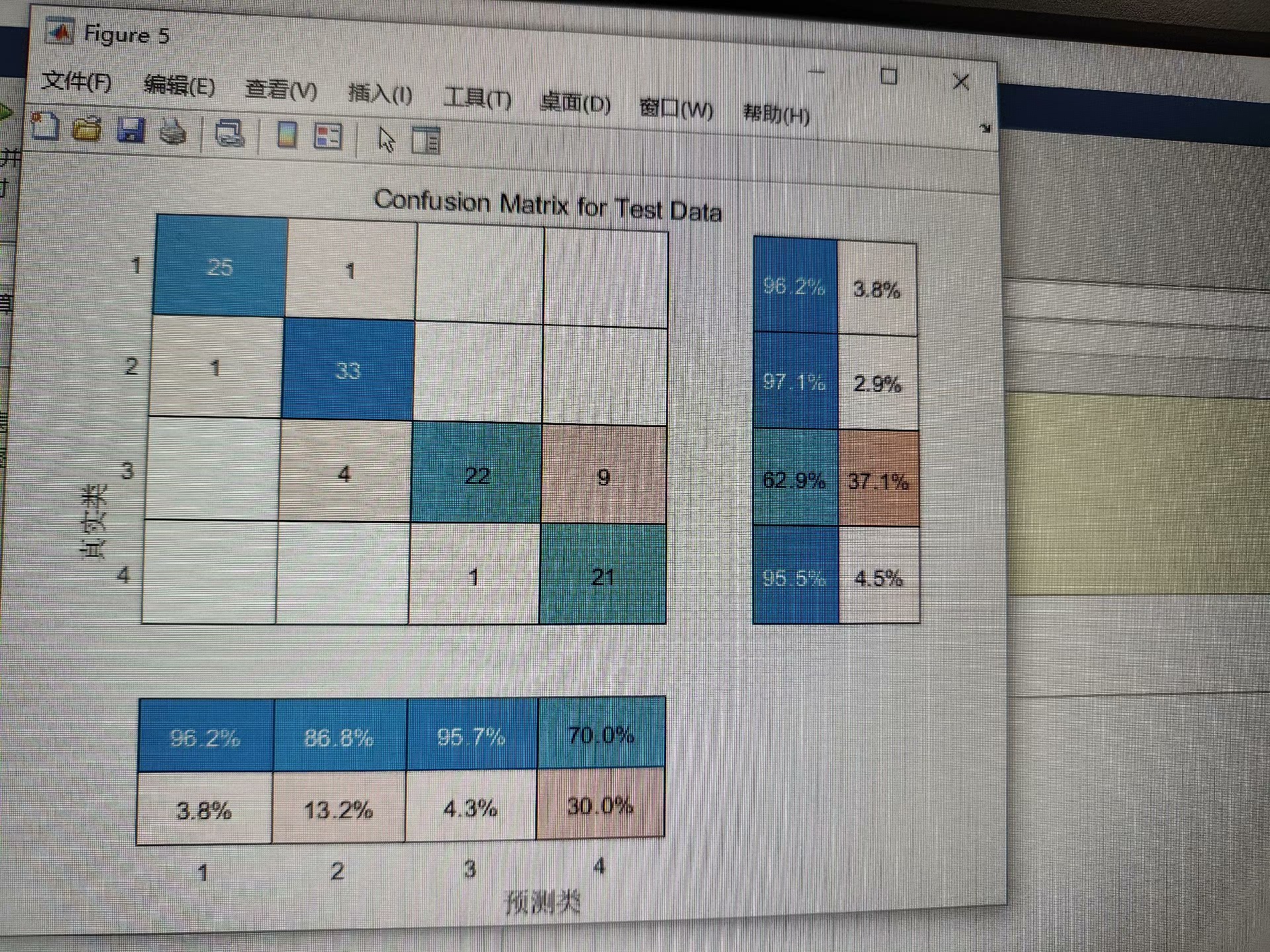
 402
402

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









