



 该博客介绍了如何在Linux命令行中使用wget工具下载Google云端硬盘上的文件,包括小文件和大文件的下载方法。详细步骤包括获取FILE_ID,以及使用下载大文件命令的示例。提供了一个具体文件下载的链接解析过程,帮助用户理解如何从URL中提取FILE_ID。
该博客介绍了如何在Linux命令行中使用wget工具下载Google云端硬盘上的文件,包括小文件和大文件的下载方法。详细步骤包括获取FILE_ID,以及使用下载大文件命令的示例。提供了一个具体文件下载的链接解析过程,帮助用户理解如何从URL中提取FILE_ID。
这个不宜多说,贴张图看看,用过的应该知道这个是哪个云端硬盘:
从这个云端硬盘上下载文件时,在要下载的文件上右键点击,在弹出菜单中点击下载然后由浏览器去下载它,但是在Linux命令行下想使用wget去下载它,怎么办呢?
使用wget下载小文件的命令:
wget --no-check-certificate "https://drive.google.com/uc?export=download&id=FILE_ID" -O FILE
使用wget下载大文件的命令:
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=FILE_ID' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=FILE_ID" -O FILE && rm -rf /tmp/cookies.txt
用下载大文件的命令下载小文件肯定是可以的,下载小文件的命令下载大一点的文件就不行。
FILE就是要下载的文件的名字,例如thumos14-data.tar.gz,那怎么获取上面的FILE_ID呢?
首先在要下载的文件上右键点击弹出菜单,选择"获取链接",在弹出的窗口点"复制链接":
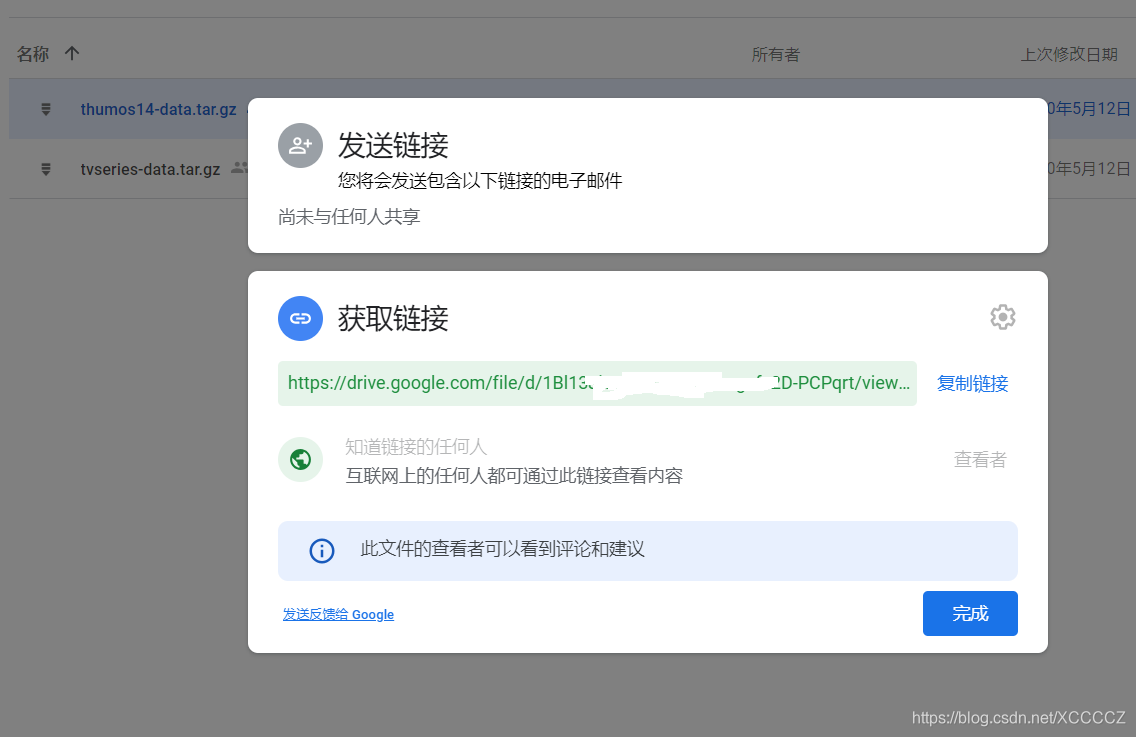
假设复制到的链接地址为:
https://drive.google.com/file/d/1Bl13iUKkaii-askopsJKL-ss2D-PCPqrt/view?usp=sharing
那么thumos14-data.tar.gz这个文件的FILE_ID为1Bl13iUKkaii-askopsJKL-ss2D-PCPqrt,那么使用下载大文件的命令下载它就是:
wget --load-cookies /tmp/cookies.txt "https://docs.google.com/uc?export=download&confirm=$(wget --quiet --save-cookies /tmp/cookies.txt --keep-session-cookies --no-check-certificate 'https://docs.google.com/uc?export=download&id=1Bl13iUKkaii-askopsJKL-ss2D-PCPqrt' -O- | sed -rn 's/.*confirm=([0-9A-Za-z_]+).*/\1\n/p')&id=1Bl13iUKkaii-askopsJKL-ss2D-PCPqrt" -O thumos14-models.tar.gz && rm -rf /tmp/cookies.txt


















 2369
2369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











