






今天在工作中遇到了一个挑战,在这里和大家分享一下我的解决过程。突然接到一个紧急需求,需要在服务器上部署一个模型文件,而这个文件存储在谷歌云盘里。摆在面前有两个选择:
- 方案一:先在本地下载,然后再上传到服务器。
- 方案二:直接在服务器上下载。
这个模型文件足足有 5 个 G,通过本地下载再上传到服务器,不仅要耗费大量的时间,还可能因为网络不稳定导致传输失败。所以,我果断选择了第二种方案。那么,我是如何成功在服务器上完成下载的呢?接下来就详细为大家介绍一下整个过程。
如果你也遇到过类似的问题,或者对从服务器直接下载谷歌云盘文件的方法感兴趣,就请继续关注我的后续内容吧!
这里以https://drive.google.com/drive/folders/1jI32B-2JX17seSGG0-MnZgUhCMHCEZlx内容为例进行演示:
要通过 wget 下载谷歌云盘中的大文件,你需要一些额外的步骤,因为 Google Drive 并不直接允许通过 wget 下载文件。通常,你需要使用 Google Drive 的共享链接,并处理一些重定向问题。以下是如何用 wget 下载 Google Drive 上的大文件的步骤:
-
获取文件的共享链接:首先,你需要确保文件在 Google Drive 中是共享的,并获取共享链接。链接通常看起来像这样:
1https://drive.google.com/file/d/FILE_ID/view?usp=sharing在这个链接中,
FILE_ID是文件的唯一标识符。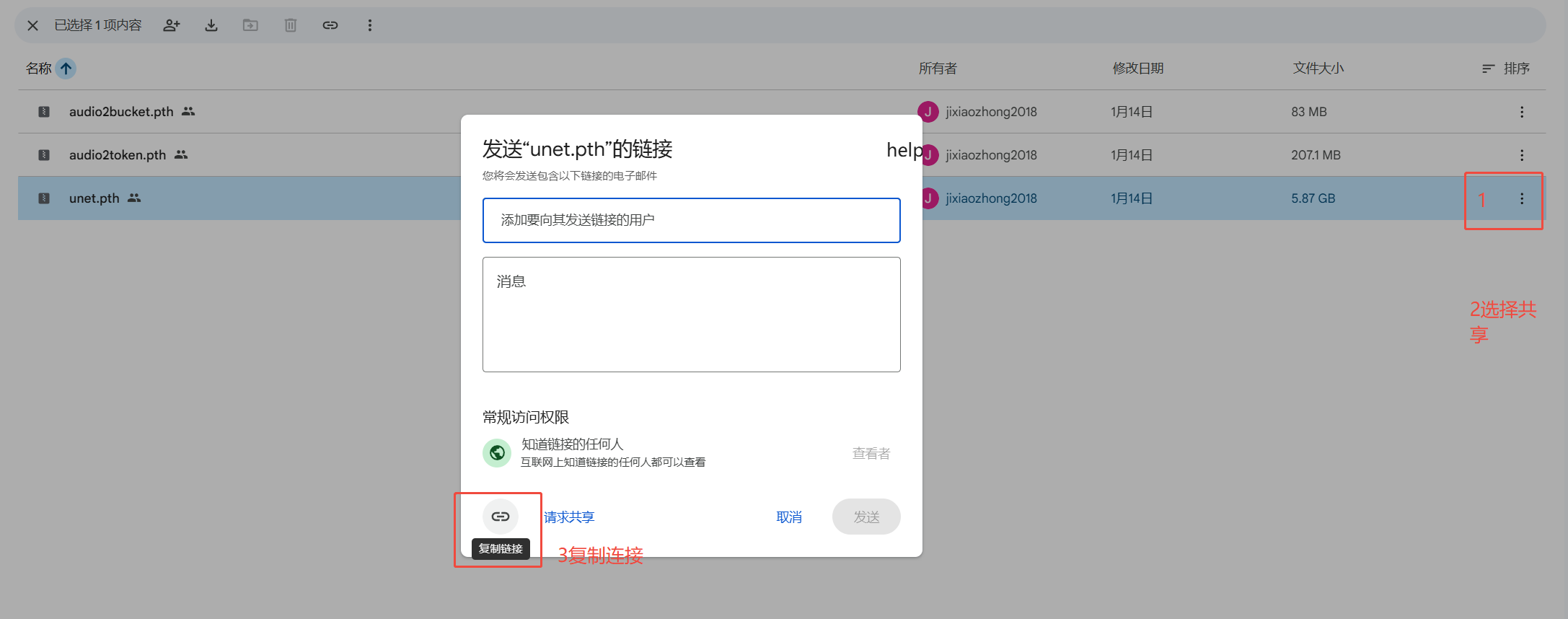
这里获取到https://drive.google.com/file/d/1mjIqU-c5q3qMI74XZd3UrkZek0IDTUUh/view?usp=sharing,所以它的file_id=1mjIqU-c5q3qMI74XZd3UrkZek0IDTUUh
-
使用 wget 下载文件:你可以使用以下的命令来下载文件
-
处理重定向问题:由于 Google Drive 的大文件下载会遇到额外的确认步骤(例如安全扫描),你可能需要绕过这一过程。如果文件较大(超过100MB),你可能需要通过
wget先获取一个确认文件(通常是confirm),然后才会继续下载。你可以使用下面的脚本来解决这一问题:
1234567891011121314151617181920212223242526272829303132333435363738394041424344454647484950515253545556#!/bin/bash# 设置文件ID和输出文件名FILE_ID="1mjIqU-c5q3qMI74XZd3UrkZek0IDTUUh"# 替换成实际文件IDOUTPUT="unet.pth"# 替换成你想保存的文件名# 获取下载页面并保存响应RESPONSE=$(wget --quiet --save-cookies cookies.txt \--keep-session-cookies --no-check-certificate \"https://drive.google.com/uc?export=download&id=${FILE_ID}"\-O -)# 保存响应以供调试echo"$RESPONSE"> response.html# 提取完整的下载参数DOWNLOAD_URL="https://drive.usercontent.google.com/download"ID=$(echo"$RESPONSE"|grep-o'name="id" value="[^"]*"'|cut-d'"'-f4)EXPORT=$(echo"$RESPONSE"|grep-o'name="export" value="[^"]*"'|cut-d'"'-f4)CONFIRM=$(echo"$RESPONSE"|grep-o'name="confirm" value="[^"]*"'|cut-d'"'-f4)UUID=$(echo"$RESPONSE"|grep-o'name="uuid" value="[^"]*"'|cut-d'"'-f4)# 检查是否所有参数都已获取if[ -z"$ID"] || [ -z"$EXPORT"] || [ -z"$CONFIRM"] || [ -z"$UUID"];thenecho"无法提取所有必要的下载参数"echo"ID: $ID"echo"EXPORT: $EXPORT"echo"CONFIRM: $CONFIRM"echo"UUID: $UUID"exit1fi# 构建完整的下载URLFULL_URL="${DOWNLOAD_URL}?id=${ID}&export=${EXPORT}&confirm=${CONFIRM}&uuid=${UUID}"echo"开始下载文件..."echo"使用URL: $FULL_URL"# 执行下载wget --load-cookies cookies.txt \--no-check-certificate \"$FULL_URL"\-O"$OUTPUT"# 检查下载是否成功if[ $? -eq0 ];thenecho"文件下载成功:$OUTPUT"elseecho"下载失败"exit1fi# 清理临时文件rm-f cookies.txtexit0这个脚本应该能够正确处理Google Drive的病毒扫描警告页面,并成功下载文件。
-
.使用方法:
- 将脚本保存为文件(例如:download_gdrive.sh)
- 修改FILE_ID为你要下载的文件ID
- 修改OUTPUT为你想保存的文件名
- 给脚本添加执行权限:
chmod +x download_gdrive.sh - 运行脚本:
./download_gdrive.sh
-
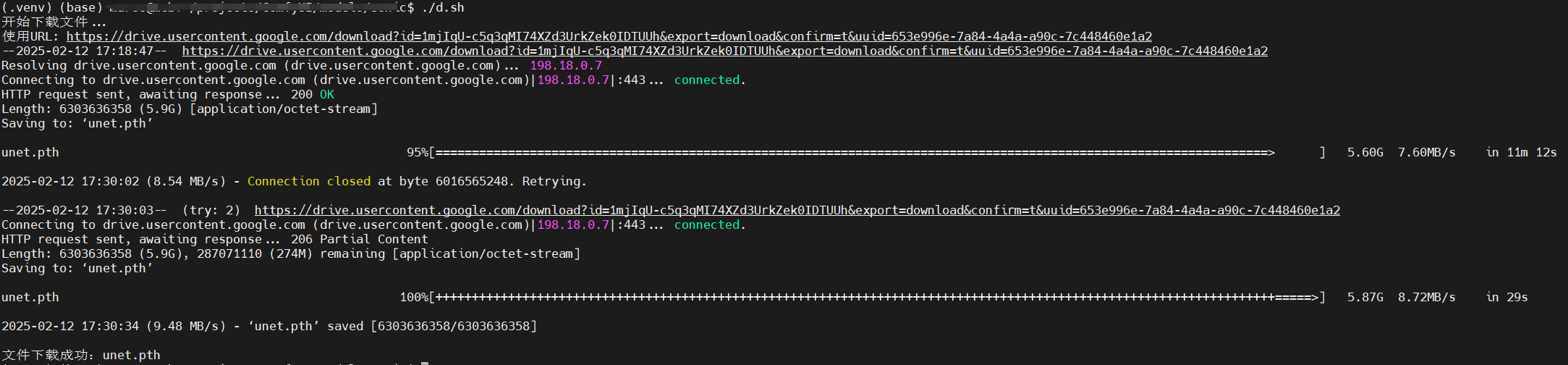
我在服务器顺利下载大文件,如图所示:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









