




 该数据库提供首个带有语义类别像素级标签的驾驶场景视频集合,包含超过700张手动标注的图像及对应的元数据,适用于评估新兴算法。视频源自行车视角,覆盖丰富多样的目标类别。
该数据库提供首个带有语义类别像素级标签的驾驶场景视频集合,包含超过700张手动标注的图像及对应的元数据,适用于评估新兴算法。视频源自行车视角,覆盖丰富多样的目标类别。
Motion-based Segmentation and RecognitionDataset
(this is a draft versionof this page)
(this is a draft versionof this page)
| Please cite: | |||||||
| (1) | Segmentation and RecognitionUsing Structure from Motion Point Clouds, ECCV 2008 (pdf) Brostow, Shotton, Fauqueur, Cipolla (bibtex) | ||||||
| (2) | Semantic Object Classes inVideo: A High-Definition Ground Truth Database (pdf) Pattern Recognition Letters (to appear) Brostow, Fauqueur, Cipolla (bibtex) | ||||||
| Description: | The Cambridge-driving LabeledVideo Database (CamVid) is the first collection of videos with objectclass semantic labels, complete with metadata. The database providesground truth labels that associate each pixel with one of 32 semantic classes. The database addresses the need for experimental data to quantitativelyevaluate emerging algorithms. While most videos are filmed withfixed-position CCTV-style cameras, our data was captured from theperspective of a driving automobile. The driving scenario increases thenumber and heterogeneity of the observed object classes. Over ten minutes of high quality 30Hz footage is being provided, withcorresponding semantically labeled images at 1Hz and in part, 15Hz. TheCamVid Database offers four contributions that are relevant to objectanalysis researchers. First, the per-pixel semantic segmentation ofover 700 images was specified manually, and was then inspected andconfirmed by a second person for accuracy. Second, the high-quality andlarge resolution color video images in the database represent valuableextended duration digitized footage to those interested in drivingscenarios or ego-motion. Third, we filmed calibration sequences for thecamera color response and intrinsics, and computed a 3D camera pose foreach frame in the sequences. Finally, in support of expanding this orother databases, we offer custom-made labeling software for assistingusers who wish to paint precise class-labels for other images andvideos. We evaluated the relevance of the database by measuring theperformance of an algorithm from each of three distinct domains:multi-class object recognition, pedestrian detection, and labelpropagation. | ||||||
| Overview Video: |  Avi, 30 Mb, xVid compressed.(playbacktips or get the free Mac/Windows player. or Mpg, 11 Mb, mpeg-1 compressed(more compatible, but lower quality) | ||||||
|
| |||||||

CamVid Database (just samples shown. For all thevideos, see below) | |||||||
| Original Video Sequences: | Link to FTP server withvideo files (very big!) Linkto codecs + utility for extracting frames from those big files (read the inventory.txt) | ||||||
|
Labeled Images (701 so far) | Linkto zip file with painted class labels for stills from the videosequences. Txtfile listing classes and label colors as RGB triples (sorted). (Note: the corresponding raw input images only - at 1Hz, already extracted from the respective videos areheretemporarily(556Mb).) | ||||||
|
Camera extrinsics | Linkto files and code (if link breaks someday, go here) The relevant line that you care about to get the projection matrix of 1camera is in MotBoostEvalOneFrame.m (see howLoadBoujou_2Dtrax_3dBans_Misc.m calls it): curC = Cs( frameNum-offsetForFrameNums, 1:3); | ||||||
| Examplecamera posetrajectory, stored in Boujou Animation Format: each line containing "AddDecompCameraKey" has a K and R matrix and tvector, so that P = K * R * [I -t] | |||||||
|
|
|
| |||||
| seq06R0 | |||||||
|
seq16E5
 Description: 6120 frames at 30Hz == 3:24 min Sample Frame VideoFiles 1 and 2 inMXF format* (note: these are 2halves of 1 zip file) seq16E5_15Hz (see also CamSeq01) 
Description: 202 frames at 30Hz == 0:06 min Sample Frame VideoFiles 1 and 2 inMXF format * (note: same files asabove, but use a different script) | |||||||
|
seq05VD
 Description: 5130 frames at 30Hz == 2:51 min Sample Frame VideoFileinMXF format* | |||||||
| seq01TP | |||||||
 | |||||||
| Listingof (RGB)-Classassignments (alphabetical) Listingin color-order used by MSRC(with "XX") | |||||||
| |||||||


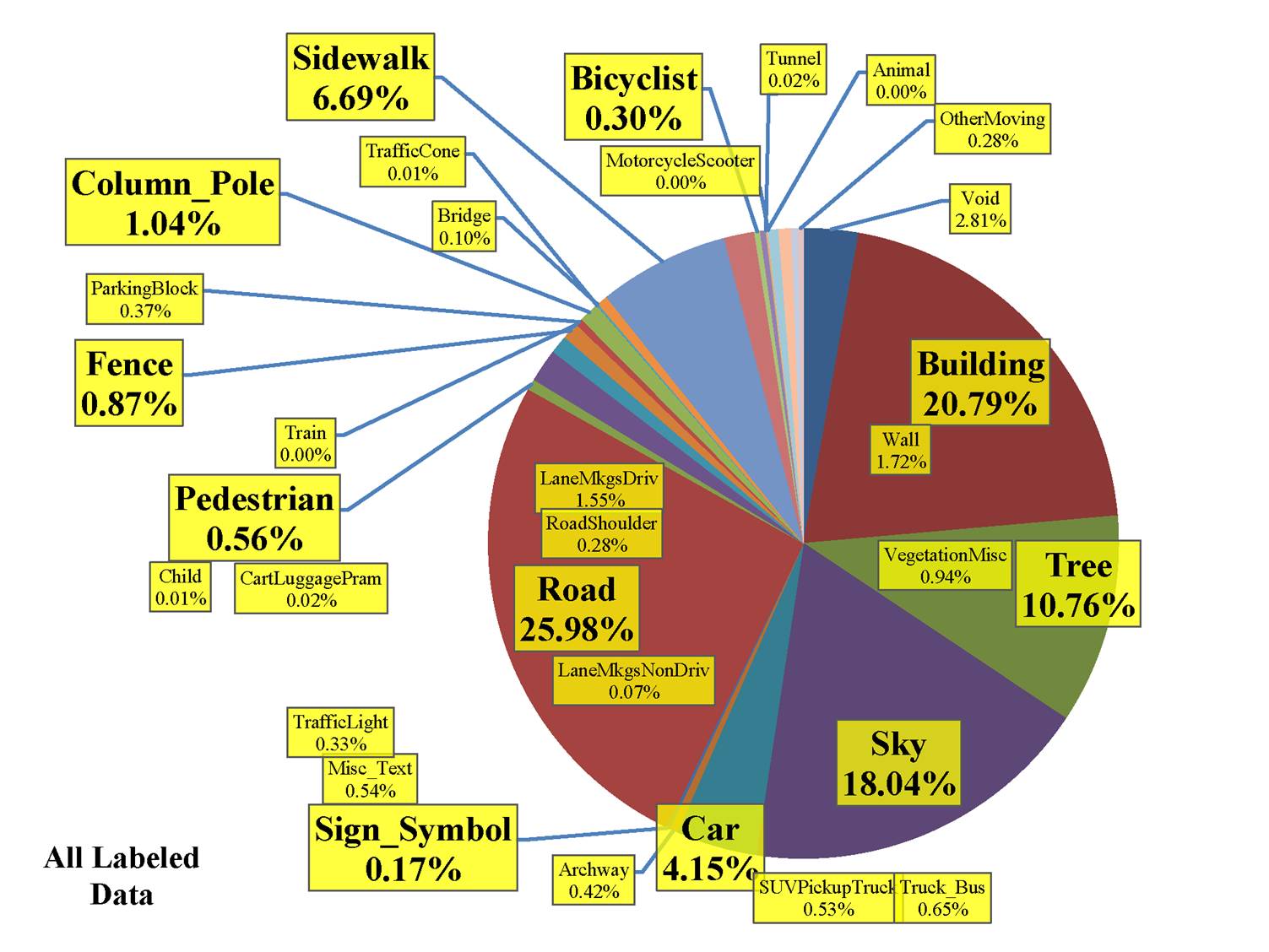
Hand-Labeled Frames:
seq06R0

seq16E5


seq05VD

Description: 101 frames at 1Hz == 1:41 min
Sample Frame PreviewVideo
seq01TP

Description: 124 frames at 1Hz == 2:04 min
Sample Frame PreviewVideo
Paint-Stroke Logs of ManualLabeling:
Example log file, whereeachof the user's mouse-strokes was recorded to include:
the class label being applied, size and type of brush orpre-segmentation used, location of each click point and drag-path, andduration for each stroke.
InteractLabeler Software:
InteractLabeler.zipforWindows (3.4Mb)
InteractLabelerDocumentation
InteractLabelerinstructions, as given to volunteers
*MXF format:
This format is like Avi orQuicktime in that it is a wrapper for multimedia files. In our case,just the video channel has data, and is HD format. To decode, use thisutility ( link)along with the scripts provided.

















 4614
4614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









