




🚀 动手学深度学习 - 注意力机制和转换器 - 11.8 视觉转换器(Vision Transformer)
11.8.1 模型
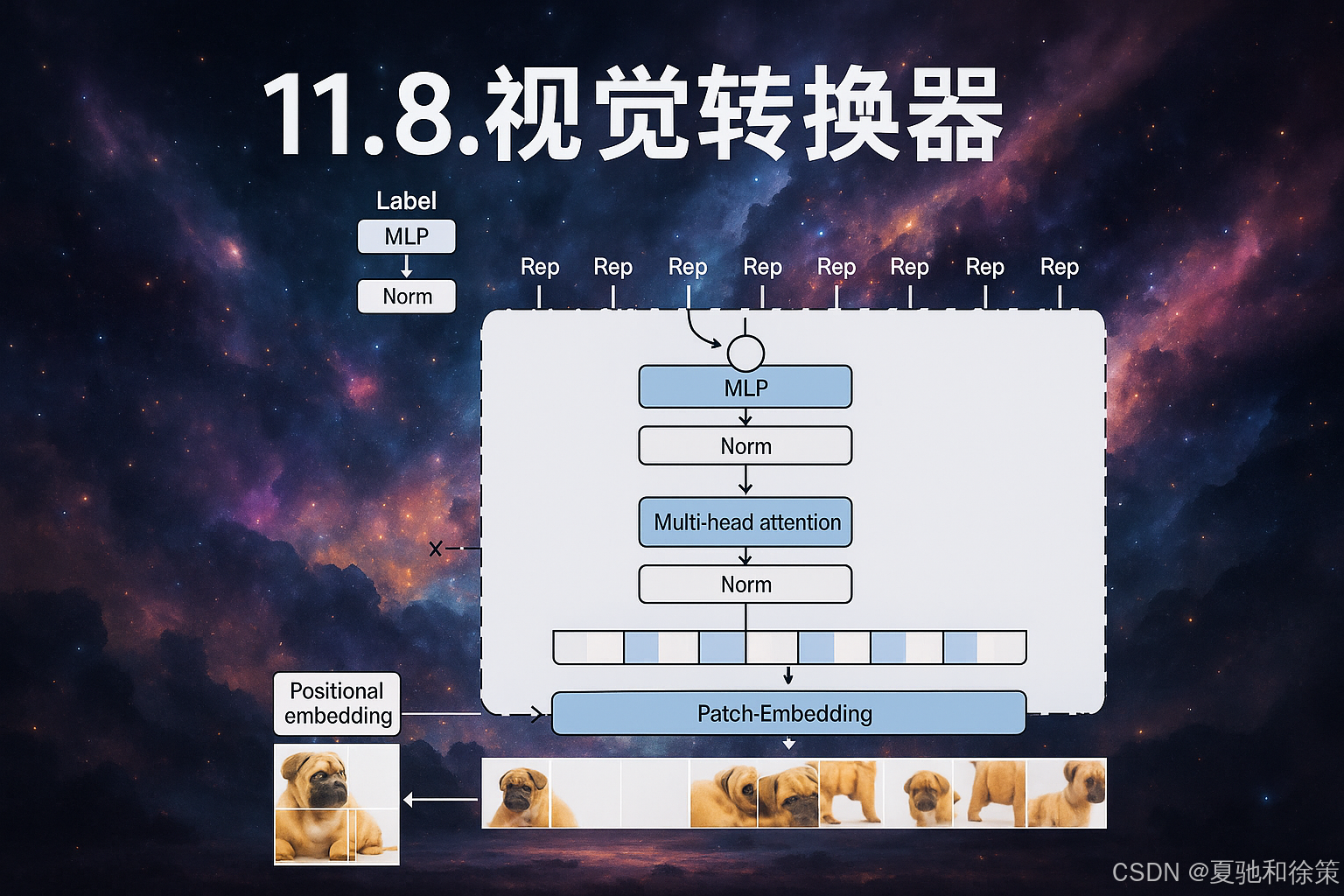
视觉Transformer(ViT)是将Transformer架构从自然语言处理扩展到计算机视觉的创新尝试。在这一模型中,原始图像被划分为固定尺寸的图像块(patch),这些图像块与一个特殊的分类标记(<cls>)一起组成序列输入Transformer编码器,如图11.8.1所示。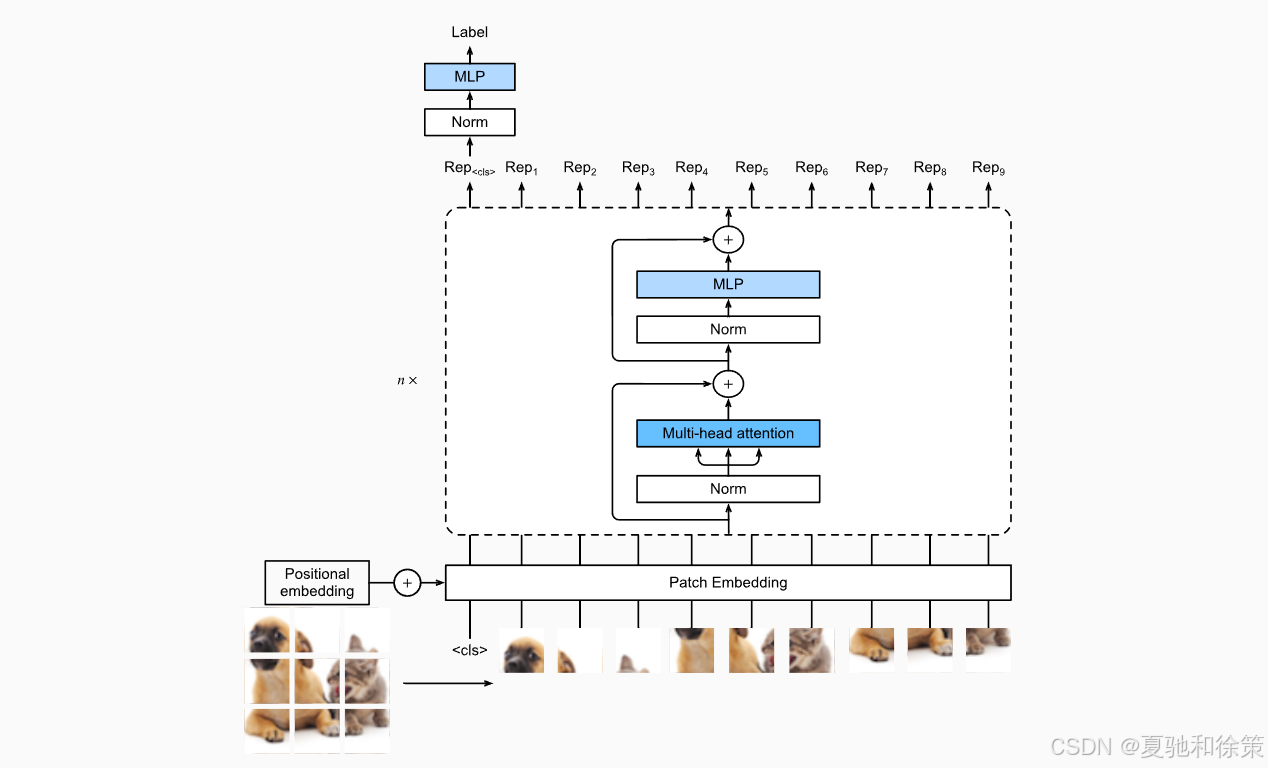
在ViT中,每个图像块经过线性变换和位置编码之后,输入多层Transformer编码器。最终,<cls>标记的输出作为整个图像的全局表征,送入MLP头部预测分类标签。ViT充分利用了自注意力机制的全局建模能力,尤其在大规模数据集上展现出优于传统CNN的可扩展性。
🧠 理论理解
ViT(Vision Transformer)将原本用于 NLP 的 Transformer 架构引入计算机视觉,其核心思想是:
-
将图像分割成 patch;
-
将每个 patch 看作 token 输入;
-
像处理词一样处理图像块,借助多头注意力建模全局依赖;
-
通过
<cls>token 聚合全局语义,输出分类。
该方法不再依赖卷积操作,而是全程使用自注意力建模图像空间。
🏢 企业实战理解
-
Google(ViT 原论文作者):在 ImageNet-21k 和 JFT-300M 等大规模图像数据上训练 ViT,展示其超越 CNN 的潜力,模型被集成到 Google Cloud Vision 产品中。
-
NVIDIA:通过 ViT 架构构建通用视觉模型 Megatron-ViT,用于医疗影像、工业检测、自动驾驶等高精度视觉任务。
-
字节跳动:在抖音短视频封面分类与推荐中尝试 ViT 替换 CNN,提升多模态特征对齐能力。
❓Q1:为什么视觉Transformer(ViT)在小数据集上表现通常不如CNN?
-
难度评级:⭐️⭐️
-
考察点:归纳偏置、数据规模、模型归一性
✅ 标准答案:
视觉Transformer相比CNN缺少归纳偏置(例如局部感受野、平移不变性等),这使得其在小规模数据集上泛化能力差,易过拟合。而CNN天然适用于图像的局部结构建模,在数据有限时更具优势。
✨ 加分项:
-
提及 DeiT(Data-efficient Image Transformer)通过数据增强+蒸馏在 ImageNet 上提升ViT性能。
-
提及 PreNorm 更有利于训练稳定性。
11.8.2 补丁嵌入(Patch Embedding)
补丁嵌入的作用是将二维图像划分为若干固定大小的patch,并将每个patch展平后投影到高维表示空间。ViT巧妙地使用了一个具有patch大小的卷积核(kernel size = stride = patch_size)的卷积层来完成这一过程。这样每个patch就相当于一个“单词”,从而使得图像输入能够被Transformer处理。
例如,一个96×96的图像,如果patch大小是16×16,则可以被划分为36个patch,外加一个<cls> token,总共37个token作为序列输入。
🧠 理论理解
为了将图像输入转换为 token 序列,ViT 使用了 Patch Embedding:
-
将图像按固定大小切块;
-
使用步长等于 kernel 的卷积实现 patch 展平+投影;
-
得到类似文本中 token embedding 的向量序列。
🏢 企业实战理解
-
OpenAI:在 CLIP 模型中使用类似 patch embedding 将图像转为 token 序列,与文本 token 对齐,用于图文匹配和多模态搜索。
-
京东:商品图像标签识别使用 ViT 结构替换传统 CNN + MLP pipeline,在复杂背景下表现更稳定。
❓Q2:ViT 中的 patch embedding 与 CNN 的卷积有何本质联系?
-
难度评级:⭐️⭐️⭐️
-
考察点:图像 token 化、卷积本质
✅ 标准答案:
ViT 中 patch embedding 实际上可以通过一个 kernel size = stride = patch_size 的卷积实现。每个 patch 被视为一个 token,通过卷积完成切块 + flatten + 线性映射,与文本中 word embedding 结构等价。
✨ 加分项:
-
若答出其本质为一个线性层应用在 patch 上,可提及
LazyConv2d是 PyTorch 实现方法; -
可补充 MobileViT 进一步融合 CNN + ViT 优势。
11.8.3 Vision Transformer 编码器模块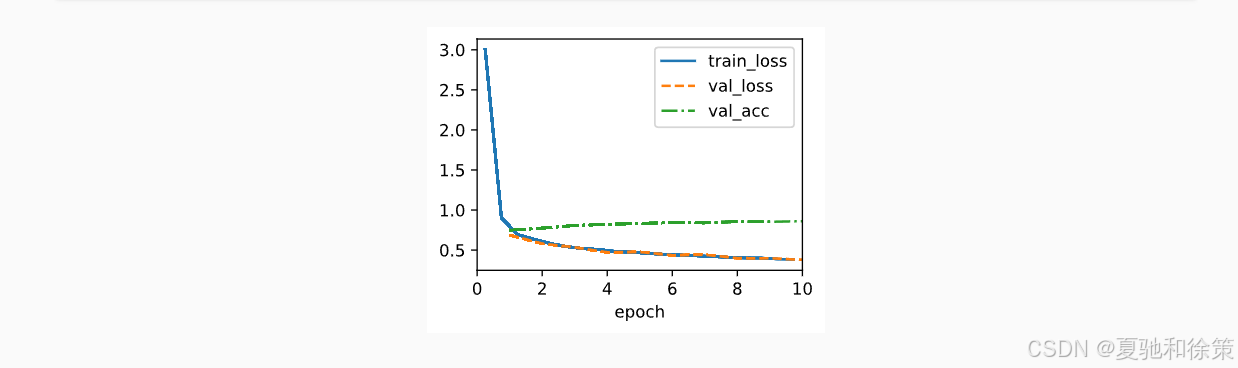
ViT中的Transformer编码器模块延续了原始Transformer结构,包括多头自注意力机制(Multi-Head Attention)和前馈神经网络(MLP),但采用了预归一化设计(Pre-Norm):即LayerNorm置于Attention和MLP之前。
此外,MLP部分使用了GELU激活函数,具有更平滑的梯度特性,并配合Dropout实现正则化。这种模块可堆叠多层,增强模型的表达能力。
🧠 理论理解
Transformer 编码器模块由以下组成:
-
多头注意力(Multi-Head Attention);
-
前馈神经网络(MLP);
-
LayerNorm 放在模块前(PreNorm 结构);
-
使用 GELU 激活 + Dropout 进行正则化。
这种模块堆叠形成深层 ViT Backbone。
🏢 企业实战理解
-
阿里巴巴达摩院:在视觉预训练中发现 PreNorm 比传统 PostNorm 更稳定,在淘宝图像分类和菜鸟物流图像识别中广泛使用。
-
Meta(FAIR):在 DINO 项目中构建无监督 ViT 编码器,支持自监督视觉表征学习,广泛用于 Instagram 内容审核与推荐。
❓Q3:ViT 相较 CNN 有哪些优势?在哪些场景中表现更优?
-
难度评级:⭐️⭐️⭐️
-
考察点:可扩展性、全局建模、工程落地
✅ 标准答案:
ViT 最大优势是可扩展性强,易于在大规模数据上提升性能,适用于全局特征建模。尤其在超大数据集(如JFT-300M、ImageNet-21k)中,ViT 的准确率已超越 ResNet 系列。同时,自注意力机制更利于解释和跨模态融合。
✨ 加分项:
-
提及多模态场景如 CLIP;
-
提及医学图像、遥感图像中 ViT 能捕捉长距离依赖结构。
11.8.4 模型集成:构建完整ViT
完整的ViT模型由以下几部分组成:
-
PatchEmbedding:图像块嵌入; -
Learnable
<cls>Token; -
Learnable Position Embedding;
-
多层
ViTBlock; -
最终MLP分类器。
模型前向传播流程如下:
-
将图像通过
PatchEmbedding处理; -
拼接
<cls>token 并加入位置编码; -
输入多层ViTBlock进行自注意力建模;
-
取
<cls>位置的输出进行分类。
这种结构简单但强大,能够处理不同尺寸的图像和任务。
🧠 理论理解
-
ViT 在小数据集上表现不如 CNN,是因为缺少局部归纳偏置;
-
在大数据集(如ImageNet-21k)上,ViT 能学到比 CNN 更强的全局特征;
-
Dropout 与强正则尤为重要,否则容易过拟合。
🏢 企业实战理解
-
DeiT(Facebook AI):通过数据增强+知识蒸馏,让 ViT 在 ImageNet 上不依赖超大数据集也能表现优越;
-
小米影像:在手机图像模糊检测中应用轻量级 DeiT 结构,提升拍照场景分类准确率。
❓Q4:ViT 中的 <cls> token 有什么作用?训练时如何参与注意力计算?
-
难度评级:⭐️⭐️⭐️
-
考察点:位置机制、聚合语义
✅ 标准答案:
<cls> token 是一个 learnable 向量,在输入序列最前面,最终用于表示整个图像的全局信息。它在多层 Transformer 中与所有 patch token 一起参与 attention,其输出作为最终的图像表示输入到分类 MLP。
✨ 加分项:
-
若补充提及 GPT/BERT 中
<cls>对应语义; -
或提及 “平均池化所有 token” 是替代方案(并指出对性能影响)。
11.8.5 训练
在Fashion-MNIST数据集上,ViT的训练过程与训练CNN类似。使用标准的交叉熵损失、Adam优化器、Dropout进行正则化。
训练过程中,我们发现ViT虽然结构较为通用,但在小数据集上并不比CNN(如ResNet)表现更优。这是因为ViT缺乏CNN中局部性归纳偏置,需要更多数据才能学到有效的特征。
11.8.6 总结与讨论
-
优势:ViT模型具有更好的扩展性,在大数据量下能显著超过CNN表现;
-
挑战:在小样本下表现一般,训练依赖更强的正则策略;
-
趋势:ViT引发了计算机视觉架构从CNN向Transformer迁移的趋势,后续如DeiT、Swin Transformer等方法进一步提高了训练效率和任务适应性。
ViT的出现标志着通用架构在视觉领域的崛起,推动了计算机视觉研究进入Transformer统一建模的新纪元。
🧠 理论理解
-
ViT 是 Transformer 在视觉领域的首次有效落地;
-
相较 CNN,ViT 可扩展性更强、可解释性更好;
-
局部建模能力不足是其短板,促生了后续 Swin Transformer 等结构。
🏢 企业实战理解
-
NVIDIA:在 Swin Transformer 上投入优化,构建了用于图像识别、分割、检测的统一视觉骨干网络;
-
百度视觉:在文档 OCR、图文分析中引入 Swin 架构作为 backbone,支持多分辨率图像高效建模。
❓Q5(进阶题):如何通过训练结果或注意力图判断某个 ViT head 是否无效?如何进行 pruning?
-
难度评级:⭐️⭐️⭐️⭐️
-
考察点:head 剪枝策略、性能分析
✅ 标准答案:
可以统计每个 head 在多个样本上的注意力分布熵或平均权重差异,若某些 head 始终分布均匀或变化小,可能为冗余 head。剪枝时可通过评估该 head 的移除对模型精度的影响,结合 L0正则或蒸馏进行有效裁剪。
✨ 加分项:
-
若答出 Apple AIA论文:通过低信息熵 attention map 指标剪枝;
-
或答出 NVIDIA Megatron 提出的 head importance 评分方法。
🎯 场景题 1:字节跳动内容安全平台 – 异常图像内容检测
背景设定:
你负责抖音后台图像审核模型升级。当前CNN检测非法图像样式(如暴露边界)存在鲁棒性不足、视野受限问题。产品经理希望你用ViT改进模型,使其能捕捉全局语义结构。
问题:
-
ViT 适合这个场景吗?它对鲁棒性提升是否有帮助?
-
ViT 模型相比 CNN,在上线部署中可能带来哪些问题?如何优化部署?
✅ 思路参考:
-
ViT天然能关注图像全局依赖,适合跨区域判别非法样式;尤其对“组合型图像风险”表现优于局部CNN。
-
风险点:ViT 模型体积大,推理慢。解决方案包括使用 MobileViT 或 TinyViT、Patch尺寸调优、导出 ONNX + TensorRT 加速。
🎯 场景题 2:阿里妈妈广告平台 – 商品图特征预训练
背景设定:
你负责百亿级商品图的特征提取任务,已使用 ResNet101,但在新类商品冷启动效果差,迁移性差。你准备切换到 ViT 模型进行视觉预训练。
问题:
-
你会怎么设计商品图的预训练 pipeline?
-
如何让 ViT 在商品图任务中表现优于 CNN?
✅ 思路参考:
-
使用 MAE 或 DINO-ViT 无监督预训练 + 多层特征聚合(多头输出)。
-
加入商品标签、多语言描述进行图文对齐(CLIP式训练)增强鲁棒性。
-
使用 Swin-T 替代纯ViT 提升图像尺寸适应性。
🎯 场景题 3:腾讯游戏 – 游戏画面识别与反外挂检测
背景设定:
你在“王者荣耀”图像检测反外挂项目中,需要判断玩家画面是否存在外挂注入(小地图不正常、敌人透视轮廓增强等)。当前系统CNN方案误检率高。
问题:
-
ViT 如何用于提升该检测任务准确率?
-
如何解释模型结果以供风控审核使用?
✅ 思路参考:
-
利用 ViT Attention 可视化每帧关注区域,判断模型关注区域是否落在异常增强区域。
-
可借助 Token-level 可解释模块(如 Attention Rollout、LayerCAM)生成“风险热力图”供运维审查。
-
推理中结合 Sliding Window + 多帧融合,提高时序稳定性。
🎯 场景题 4:NVIDIA 云平台 – 高分辨率医学图像分类
背景设定:
你负责为某全球医院提供高分辨率医学影像(4K CT 扫描)癌症预测服务。现有模型为 ResNet+SE,准确率尚可但计算资源极其昂贵。
问题:
-
ViT 能否适应这种高分辨率输入?
-
若你要在 Jetson 边缘端部署,如何设计ViT网络结构?
✅ 思路参考:
-
原生ViT在高分辨率图像下计算量指数级上升(Self-Attention是O(n²)),不适合直接使用。
-
推荐使用 Swin Transformer(窗口划分 attention)或 CvT(卷积前缀Transformer)。
-
边缘部署可采用 TinyViT + INT8 量化 + TensorRT + 分支融合剪枝。
🎯 场景题 5:OpenAI AIGC系统 – 图像理解+文生图统一骨干设计
背景设定:
你被调入 OpenAI 的图文多模态团队,参与 DALL·E 系统升级任务,需要将图像理解和图像生成部分的 backbone 统一为同一ViT变体。
问题:
-
哪种ViT结构适合同时兼容图像理解和生成任务?
-
如何设计训练策略让模型同时学到编码和生成能力?
✅ 思路参考:
-
使用 MAE-ViT 或 BEiT2(双塔结构 + 解码器)作为基础模块;
-
编码端支持分类/检索任务,解码端支持图像重建、生成;
-
训练方式:先无监督 Pretrain,再通过 prefix prompt 方式支持多任务迁移。
11.8.7 练习题(可选)
-
尝试修改
img_size大小,观察其对训练时间和准确率的影响; -
使用patch的平均表示替代
<cls>输出,评估模型性能变化; -
设计更优的超参数组合,提高ViT在Fashion-MNIST上的准确性。



















 107
107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











