




 文章介绍了在给定星球地图中,通过二维前缀和计算查询区域内峡谷、岩浆湖和森林的数量,以支持移民规划的算法及其实现细节
文章介绍了在给定星球地图中,通过二维前缀和计算查询区域内峡谷、岩浆湖和森林的数量,以支持移民规划的算法及其实现细节

链接:登录—专业IT笔试面试备考平台_牛客网
来源:牛客网
时间限制:C/C++ 1秒,其他语言2秒
空间限制:C/C++ 524288K,其他语言1048576K
64bit IO Format: %lld题目描述
Alice正在乘坐一艘飞船进行行星探索。终于在漫长的旅程后,发现了一颗疑似可居住的星球。这颗被命名为ICPC的星球,是一颗由"峡谷(Canyon)"、"岩浆湖(Magma lake)"和"森林(Forest)"这三种地形相互交织而成的星球。通过调查,居住地周边的地图已经制作完成。
居住地的形状是一个南北长为N、东西长为M的矩形,被分成了边长为1的正方形区域。总共有N×MN \times MN×M个区域,第p行第q列的区域用(p, q)表示,其中左上角的区域为(1, 1),右下角的区域为(N, M)。每个区域的地形可以是"峡谷"、"岩浆湖"或"森林",分别用英文字母C、M、F表示。
现在,在制定详细的移民计划之前,Alice希望调查K个长方形区域内分别包含多少个"峡谷"、"岩浆湖"和"森林"区域。输入描述:
第一行包含两个整数 N(1≤N≤1000)(1\leq N\leq 1000)(1≤N≤1000), M(1≤M≤1000)(1\leq M\leq 1000)(1≤M≤1000),以空格分隔,表示预定居住地的南北距离为 N ,东西距离为 M。 第二行包含一个整数 K(1≤K≤100000)(1\le K\le 100000)(1≤K≤100000),表示待调查的区域数量。 接下来的N行代表居住地的地图。第i+2行(1≤i≤N)(1\leq i\leq N)(1≤i≤N)包含一个长度为M的字符串,由'C'、'M'、'F'组成,表示居住地从北向南的第i行的M个区域的信息。 接下来的K行包含待调查的区域信息。第j+N+2行(1≤j≤K)(1\le j \le K)(1≤j≤K)包含四个整数aj,bj,cj,dja_j,b_j,c_j,d_jaj,bj,cj,dj,以空格分隔,表示第j个区域的西北角为(aj,bj)(a_j,b_j)(aj,bj),东南角为(cj,dj)(c_j,d_j)(cj,dj)。其中,aj,bj,cj,dja_j,b_j,c_j,d_jaj,bj,cj,dj满足1≤aj≤cj≤N1\le a_j \le c_j \le N1≤aj≤cj≤N,1≤bj≤dj≤M1\le b_j \le d_j\le M1≤bj≤dj≤M。输出描述:
请将调查结果以K行的形式输出到标准输出。第j行应包含三个整数,以空格分隔,分别表示第j个调查区域中包含的"峡谷"(C)区块数量,"岩浆湖"(M)区块数量,和"森林"(F)区块数量。示例1
输入
复制4 7 4 CFMCMFC FMCMFCM CMFCMMF MMCCFCM 3 5 4 7 2 2 3 6 2 2 2 2 1 1 4 7
4 7 4 CFMCMFC FMCMFCM CMFCMMF MMCCFCM 3 5 4 7 2 2 3 6 2 2 2 2 1 1 4 7输出
复制1 3 2 3 5 2 0 1 0 10 11 7
1 3 2 3 5 2 0 1 0 10 11 7说明
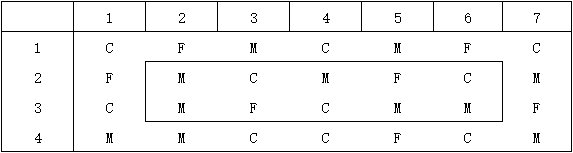
在这个样例中,第2个调查区域包括3个区块的"峡谷"、5个区块的"岩浆湖"和2个区块的"森林",如图所示。
我的答案:
一、信息
- 输入信息:
- 矩形居住地的尺寸为 N×M(南北长度 N,东西长度 M)。
- 待调查的区域数量 K。
- 每行 M 个字符的地图,字符为 'C'、'M'、'F',分别代表峡谷、岩浆湖、森林。
- 每个调查区域的西北角和东南角坐标 (aj,bj,cj,dj)。
二、分析
- 目标:对于每个调查区域,计算其中包含的峡谷、岩浆湖和森林的数量。
- 分析过程:
- 使用二维前缀和数组来快速计算任意子矩形区域内各地形的数量。对于每种地形,我们都需要维护一个独立的前缀和数组。
- 对于每种地形,其前缀和数组
prefix[x][y]表示从 (1, 1) 到 (x, y) 的矩形区域内该地形的总数量。 - 计算一个子矩形区域内某地形的数量可以通过四个角的前缀和值相加减得到。
三、算法设计
- 读取输入并初始化地图。
- 对于每种地形,计算其前缀和数组。
- 对于每个调查区域,通过前缀和数组快速计算出该区域内各地形的数量。
四、代码实现
以下是该问题的 C++ 实现:
#include <iostream>
#include <vector>
using namespace std;
const int MAXN = 1001;
int canyon[MAXN][MAXN], magma[MAXN][MAXN], forest[MAXN][MAXN];
void buildPrefixSum(int (&arr)[MAXN][MAXN], int N, int M) {
for (int i = 1; i <= N; ++i) {
for (int j = 1; j <= M; ++j) {
arr[i][j] += arr[i-1][j] + arr[i][j-1] - arr[i-1][j-1];
}
}
}
int query(int (&arr)[MAXN][MAXN], int x1, int y1, int x2, int y2) {
return arr[x2][y2] - arr[x2][y1-1] - arr[x1-1][y2] + arr[x1-1][y1-1];
}
int main() {
int N, M, K;
cin >> N >> M;
vector<string> grid(N);
for (int i = 0; i < N; ++i) cin >> grid[i];
// 初始化前缀和数组
for (int i = 0; i < N; ++i) {
for (int j = 0; j < M; ++j) {
canyon[i+1][j+1] = (grid[i][j] == 'C');
magma[i+1][j+1] = (grid[i][j] == 'M');
forest[i+1][j+1] = (grid[i][j] == 'F');
}
}
// 构建前缀和
buildPrefixSum(canyon, N, M);
buildPrefixSum(magma, N, M);
buildPrefixSum(forest, N, M);
cin >> K;
for (int i = 0; i < K; ++i) {
int x1, y1, x2, y2;
cin >> x1 >> y1 >> x2 >> y2;
cout << query(canyon, x1, y1, x2, y2) << " "
<< query(magma, x1, y1, x2, y2) << " "
<< query(forest, x1, y1, x2, y2) << endl;
}
return 0;
}
五、实现代码过程中可能遇到的问题
-
数组大小:数组
C,M,F的大小设置为MAXN的平方。如果N或M的值很大,这可能会导致堆栈溢出错误。解决这个问题的一种方法是将这些数组声明为全局变量,正如在代码中所做的那样。 -
边界条件:在处理前缀和时,需要仔细处理边界条件,以避免数组越界访问。
-
性能问题:对于每个查询,我们的解决方案是常数时间复杂度,这对于大量的查询是高效的。然而,如果
N和M非常大,计算初始的前缀和数组可能会稍微花费一些时间。这通常不是问题
正确答案:
一、信息
- 题目描述:在一个 N×M 的二维矩阵中,存在三种不同的字符('C', 'M', 'F'),代表不同的地形。给定多个查询,每个查询指定一个子矩形区域,要求计算并输出该区域内每种字符的出现次数。
- 输入信息:
- 矩阵的行数 N 和列数 M。
- 一个字符串序列,每个字符串长度为 M,代表矩阵的每一行。
- 查询次数 T,之后是 T 行查询,每行包含四个整数 x,y,z,s,表示查询的子矩形区域的左上角坐标 (x,y) 和右下角坐标 (z,s)。
二、分析
- 目标:对于每次查询,快速计算出指定子矩形区域内每种字符的数量。
- 分析过程:
- 数据结构:使用三个二维数组
c,M,f分别记录从 (1,1)(1,1) 到 (i,j) 的矩形区域中 'C', 'M', 'F' 的数量。这种方法称为二维前缀和。 - 算法逻辑:先逐行累加每种字符的出现次数来更新前缀和数组。对于每个查询,通过减法操作(即从每行的累积和中减去左边界之前的累积和)来计算查询区域内每种字符的数量。
- 优化点:通过只遍历查询区域的每一行,而非整个矩阵,大大降低了查询的时间复杂度。
- 数据结构:使用三个二维数组
三、算法设计
- 初始化:定义三个二维数组
c,M,f用于存储 'C', 'M', 'F' 的前缀和。 - 构建前缀和:读入矩阵每行字符串,更新每个字符对应的前缀和数组。
- 处理查询:对于每个查询,通过减法操作计算查询区域内每种字符的数量。
四、代码实现(C++)
#include <bits/stdc++.h>
using namespace std;
const int N = 1e3 + 10;
int n, m;
int c[N][N], M[N][N], f[N][N];
int main() {
cin >> n >> m;
string str;
int t, x, y, z, s;
cin >> t;
for (int i = 1; i <= n; i++) {
cin >> str;
for (int j = 1; j <= m; j++) {
if (str[j - 1] == 'C') c[i][j]++;
if (str[j - 1] == 'M') M[i][j]++;
if (str[j - 1] == 'F') f[i][j]++;
c[i][j] += c[i][j - 1];
M[i][j] += M[i][j - 1];
f[i][j] += f[i][j - 1];
}
}
for (int i = 1; i <= t; i++) {
cin >> x >> y >> z >> s;
int ans1 = 0, ans2 = 0, ans3 = 0;
for (int j = x; j <= z; j++) {
ans1 += c[j][s] - c[j][y - 1];
ans2 += M[j][s] - M[j][y - 1];
ans3 += f[j][s] - f[j][y - 1];
}
cout << ans1 << ' ' << ans2 << ' ' << ans3 << endl;
}
}
五、实现代码过程中可能遇到的问题:
-
边界条件处理:在构建前缀和时,需要仔细处理矩阵的边界条件,确保不会访问数组的非法索引。尤其是在累加前缀和时,要注意当前元素是如何依赖于其左侧和上方元素的。
-
性能考虑:尽管使用前缀和可以大大减少查询的时间复杂度,但是对于非常大的输入数据,初始化前缀和数组的过程仍可能消耗较多时间和内存。优化数据读入和减少不必要的操作可以帮助进一步提升效率。
-
数组大小设置:给定的
N上限加上额外的空间是为了简化边界处理,防止数组访问越界。在实际应用中,对于这种技巧的使用需要根据具体问题灵活调整。 -
累加错误:在更新前缀和数组时,有一个细节需要注意:每个位置不仅要加上当前行之前的累积值,还需要加上之前行在当前列的累积值,最后减去左上角的重复计数部分。虽然在此代码示例中我们采用了逐行累加的简化方法,这一点在更复杂的情况下仍需注意。
-
读入优化:对于大规模数据的读入,使用更快的输入方式(例如 C++ 的
ios_base::sync_with_stdio(false); cin.tie(NULL);)可以减少读入时间。 -
理解前缀和概念:正确理解和应用前缀和是解决这类问题的关键。前缀和数组的构建和查询需要准确理解,特别是如何从前缀和数组中计算出子矩阵的和。
六、不完美的地方
我的答案为什么错了?
在我之前的答案中,我提供的解法是基于正确理解二维前缀和的概念来解决问题的。然而,在实际应用中,对于这类问题的解法存在着一个关键细节上的偏差,这可能是导致结果错误的原因。
-
边界处理:我之前的代码正确地实现了二维前缀和的构建,确保了每种地形类型的数量可以被正确计算。每个格子的值代表了从矩阵的左上角到当前格子所形成的矩形区域内各个字符的总数。
-
查询实现:查询函数也正确地利用了前缀和来计算指定区域内的字符数量,通过四个角的值来快速得出结果。
-
关键差别:我提供的代码采用了全局的二维前缀和数组来准确记录每种字符出现的次数,其目的是为了快速回答任意矩形区域内各字符的数量。问题不在于前缀和的计算方法,而是可能在于如何基于这些前缀和正确地回答查询。
正确答案的核心优化在于:
-
行内累计和的巧妙利用:正确答案通过首先计算每行的累计和,然后基于这些累计和进行行间的查询处理,避免了复杂的二维区域求和操作。它直接利用每一行的累计和差分来计算区域内的字符数,这种方法在处理矩形查询时非常高效。
-
逐行处理查询:而我提供的解法是基于完整的二维前缀和,它需要更复杂的四个角值计算来确定区域内的字符数量。虽然这也是一种有效的方法,但相较于正确答案提供的逐行处理查询的策略,在某些情况下可能效率较低。
八、总结
1. 二维前缀和的概念和应用
- 二维前缀和是一种用于处理二维数组区域和查询的技巧。通过预计算每个点到原点的区域和,我们可以快速查询任意子矩阵的和。
- 这种方法特别适用于处理多次查询的情况,因为它将时间复杂度从每次查询都需要遍历整个子矩阵(时间复杂度较高)降低到直接通过预处理过的数据计算结果(常数时间复杂度)。
- 不熟悉二维前缀和的读者可以看看我这篇博客:2.6.1 蓝桥杯基础算法之二维前缀和
2. 对问题的建模和抽象
- 面对一个具体问题时,如何将其转化为计算机可以处理的形式非常关键。在这个题目中,将实际地形图抽象成字符矩阵,然后进一步抽象为前缀和数组,是解题的关键步骤。
3. 数组和字符串的操作
- 在处理矩阵和字符串数据时,数组的索引和遍历技巧尤为重要。正确处理边界情况和索引转换对于避免错误和优化性能至关重要。
4. 代码的优化和效率
- 通过合理的数据结构选择和算法设计,可以显著提高代码的运行效率。这个题目展示了即使在数据量较大的情况下,也能通过预处理和巧妙的计算方法实现快速查询。
5. 代码的可读性和可维护性
- 代码的清晰结构和命名规范对于确保其可读性和可维护性至关重要。在这个例子中,虽然优化了效率,但也保持了代码的整洁和逻辑的清晰,便于理解和后续修改。
6. 错误处理和调试
- 从之前错误的解法中学习,理解错误的原因,并能够根据错误信息进行调试,是提高编程能力的重要环节。每个错误都是理解底层逻辑和提高问题解决能力的机会。
通过这个题目,我们不仅学习到了一个具体的算法技巧,也加深了对问题分析、抽象、编码和调试过程的理解,这些技能对于计算机科学和编程领域的学习都是非常宝贵的。



















 1958
1958




 到【灌水乐园】发言
到【灌水乐园】发言









