




文章目录
OpenGL 缓存数据
1. 创建与分配缓存
- 使用glCreateBuffers创建缓存,可在buffers中得到一个缓存对象名称的数组。
- 使用glNamedBufferStorage为每个缓存对象分配存储空间
- 拥有存储空间后,使用glBindBuffer,绑定缓存对象到缓存目标。
-
创建缓存
void glCreateBuffers(GLsizei n,GLuint* buffers);返回n个当前未使用的缓存对象名称(每个都表示一个新创建的缓存对象),并保存到buffers数组中。
-
绑定缓存
void glBindBuffer(GLenum target,GLuint buffer);将名称为buffer的缓存对象绑定到target所指定的缓存结合点。
buffer必须是通过glCreateBuffers()分配的名称。如果buffer是第一次被绑定,那么它所对应的缓存对象也将被同时创建。
缓存绑定的目标 目标 用途 GL_ARRAY_BUFFER 这个结合点可以用来保存glVertexAttribPointer()设置的顶点数组数据。在实际工程中这一目标可能是最为常用的。 GL_COPY_READ_BUFFER和GL_COPY_WRITE_BUFFER 这两个目标是一对互相匹配的结合点,用于拷贝缓存之间的数据,并不会引起OpenGL的状态变化,也不会影响任何特殊形式的OpenGL调用。 GL_DRAW_INDIRECT_BUFFER 如果采取间接绘制(indirect drawing)的方法,那么这个缓存目标用于存储绘制命令的参数。 GL_ELEMENT_ARRAY_BUFFER 绑定到这个目标的缓存中可以包含顶点索引数据,以便用于glDrawElements()等索引形式的绘制命令。 GL_PIXEL_PACK_BUFFER 这一缓存目标用于从图像对象中读取数据,例如纹理和帧缓存数据。相关的OpenGL命令包括glGetTextImage()和glReadPixels()等 GL_PIXEL_UNPACK_BUFFER 这一缓存目标与之前的GL_PIXEL_PACK_BUFFER相反,它可以作为glTexSubImage2D()等命令的数据源使用。 GL_TEXTURE_BUFFER 纹理缓存也就是直接绑定到纹理对象的缓存,这样就可以直接在着色器中读取它们的数据信息。GL_TEXTURE_BUFFER可以提供一个操控此类缓存的目标,但是我们还需要将缓存关联到纹理,才能确保它们在着色器中可用。 GL_TRANSFORM_FEEDBACK_BUFFER transform feedback 是OpenGL提供的一种便捷方案,它可以在管线的顶点处理部分结束时(即经过了顶点着色,可能还有几何着色阶段),将经过变换的顶点重新捕获,并且将部分属性写入缓存对象中。这一目标就提供了这样的结合点,可以建立专门的缓存来记录这些属性数据。 GL_UNIFORM_BUFFER 这个目标可以用于创建uniform缓存对象(uniform buffer object)的缓存数据。
2.向缓存输入和输出数据
将数据输入和输出OpenGL缓存的方法有很多种,例如:
- 直接显示地传递数据
- 用新的数据替换缓存对象中已有的部分数据
- 由OpenGL负责生成数据然后将它记录到缓存对象中。
最简单方法是在分配内存时读入数据:
void glNamedBufferStorage(GLuint buffer,GLsizeiptr size,const void *data,GLbitfield flags);
为缓存对象buffer分配size大小(单位为字节)的存储空间。如果参数data不是NULL,那么将使用data所在内存区域的内容来初始化整个空间。
flags用来设置缓存的预期用途信息。这些信息flags标识量在用户程序和OpenGL之间构建了协议,允许OpenGL尽可能极致地优化缓存的存储信息。
| 缓存用途标识符 | |
|---|---|
| 标识符 | 意义 |
| GL_DYNAMIC_STORAGE_BIT | 设置之后,缓存的内容可以随后通过glNamedBufferSubData()直接进行修改。如果没有设置,那么缓存内容的修改只能在GPU端完成,例如通过着色器来写入。 |
| GL_MAP_READ_BIT | 设置之后,我们可以映射缓存数据到CPU端进行读取。如果没有设置的话,当前缓存调用glMapNameBufferRange()来获取读取权限的做法都会失败。 |
| GL_MAP_WRITE_BIT | 设置之后,我们可以映射缓存数据到CPU端进行写入。如果没有设置的话,当前缓存调用glMapNamedBufferRange()来获取写入权限的做法都会失败。 |
| GL_MAP_PERSISTENT_BIT | 设置之后,对缓存数据的映射将是永久性的。也就是说,它们在渲染的过程中始终有效。这个标识必须在映射的时候同时设置才能创建永久的映射表。 |
| GL_MAP_COHERENT_BIT | 设置之后,缓存数据在GPU端和CPU端的映射将保持一致。这个标识必须在映射的时候同时进行设置才能创建一致的映射表。 |
| GL_CLIENT_STORAGE_BIT | 对于不一致的内存(nonuniform memory)系统架构来说,有些内存可能从宿主机访问更为高效,而有些内存可能从GPU访问效率更高。在确保其他标识量都设置正确之后,我们可以通过这个标识来引导OpenGL优先选择CPU(宿主)端进行访问来提升效率。 |
缓存部分初始化
-
数据设置
void glNameBufferSubData(GLuint buffer,GLintptr offset,GLsizeiptr size,const void* data);使用新的数据替换缓存对象buffer中的部分数据。缓存中从offset字节处开始需要使用地址为data、大小为size的数据块来进行更新。如果offset和size的总和超出了缓存对象绑定数据的范围,那么将产生一个错误。
缓存buffer中存储的数据必须经过glNamedBufferStorage()初始化,并且标识量应当设置为GL_DYNAMIC_STORAGE_BIT。
将glNamedBufferStorage()和glNamedBufferSubData()结合起来使用,例如:
//顶点位置 static const GLfloat positions[] = { -1.0f,-1.0f,0.0f,1.0f, 1.0f,-1.0f,0.0f,1.0f, 1.0f,1.0f,0.0f,1.0f, -1.0f,1.0f,0.0f,1.0f, }; //顶点颜色 static const GLfloat colors[] = { 1.0f,0.0f,0.0f, 0.0f,1.0f,0.0f, 0.0f,0.0f,1.0f, 1.0f,1.0f,1.0f, }; //缓存对象 GLuint buffer; //创建新的缓存对象 glCreateBuffers(1,&buffer); //分配足够的空间(sizeof(positions)+sizeof(colors)) glNamedBufferStorage(buffer, //目标 sizeof(positions) + sizeof(colors), //总计大小 nullptr, //无数据 GL_DYNAMIC_STORAGE_BIT); //标识量 //将位置信息放置在缓存的偏移地址为0的位置 glNamedBufferSubData(buffer, //目标 0, //偏移地址 sizeof(positions), //大小 positions); //数据 //放置在缓存中的颜色信息的偏移地址为当前填充大小值的位置,也就是sizeof(positons) glNamedBufferSubData(buffer, //目标 sizeof(positions), //偏移地址 sizeof(colors), //大小 colors); //数据 -
数据清除
将缓存对象的数据清除为一个已知的值,也可用如下接口。
void glClearNamedBufferData(GLuint buffer,GLenum internalformat,GLenum format,GLenum type,const void* data); void glClearNamedBufferSubData(GLuint buffer,GLenum internalformat,GLintptr offset,GLsizeiptr size,GLenum format,GLenum type,const void* data);清除缓存对象中所有或者部分数据。名为buffer的缓存存储空间将使用data中存储的数据进行填充。format和type分别指定了data对应数据的格式和类型。
首先将数据被转换到internalformat所指定的格式,然后填充缓存数据的指定区域范围。
glClearNamedBufferData,进行整个区域的指定的数据填充;
glClearNamedBufferSubData(),填充区域时通过offset和size来指定,分别给出了以字节为单位的起始偏移地址和大小。
-
数据复制
缓存对象中的数据也可以使用glCopyNamedBufferSubData()函数相互进行拷贝。
void glCopyNamedBufferSubData(GLuint readBuffer,GLuint writeBuffer,GLintptr readoffset,GLintptr writeoffset,GLsizeiptr size);将名为readBuffer的缓存对象的一部分存储数据拷贝到名为wirteBuffer的缓存对象的数据区域上。readBuffer对应的数据从readoffset位置开始复制size个字节,然后拷贝到writeBuffer对应的数据的writeoffset位置。
如果readoffset或者writeoffset与size的和超出了绑定的缓存对象的范围,那么OpenGL会产生一个GL_INVALID_VALUE错误。
读取缓存的内容
void glGetNameBufferSubData(GLenum target,GLintptr offset,GLsizeiptr size,void* data);
返回当前名为buffer的缓存对象中的部分或者全部数据。起始数据的偏移字节位置为offset,回读的数据大小为size个字节,它们将从缓存的数据区拷贝到data所指向的内存区域中。
如果缓存对象当前已经被映射,或者offset和size的和超出了缓存对象数据区域的范围,那么将提示一个错误。
3.访问缓存的内容
glNamedBufferData()、glCopyNameBufferSunData()和glGetNamedBufferSubData()都存在一个问题,它们都会导致OpenGL进行一次数据的拷贝操作。
-
根据硬件的配置,也可以通过获取一个指针的形式,直接在应用程序中对OpenGL管理的内存中进行访问。
void* glMapBuffer(GLenum target,GLenum access);将当前绑定到target的缓存对象的整个数据区域映射到客户端的地址空间中。之后可以根据给定的access策略,通过返回的指针对数据进行直接读或者写的操作。
如果OpenGL无法将缓存对象的数据映射出来,那么glMapBuffer将产生一个错误并返回NULL。发生这种情况的原因可能是与系统相关的,比如可用的虚拟内存过低等。
glMapBuffer()访问模式 标识符 意义 GL_READ_ONLY 应用程序仅对OpenGL映射的内存区域执行读操作 GL_WRITE_ONLY 应用程序仅对OpenGL映射的内存区域执行写操作 GL_READ_WRITE 应用程序对OpenGL映射的内存区域可能执行读或者写的操作 -
当结束数据的读取或写入到缓存对象的操作之后,必须执行解除映射操作
GLboolean glUnmapNamedBuffer(Gluint buffer);解除glMapNamedBufferRange()针对缓存对象buffer创建的映射。
如果对象数据的内容在映射过程中没有发生损坏,那么返回值为GL_TRUE;发生损坏的原因通常与系统相关,例如屏幕模式发生了改变,这会影响图形内存的可用性,这种情况,返回GL_FALSE,并且对应的数据内容不可预测。
应用程序必须考虑这几种较低的情形,并且及时对数据进行重新初始化。
-
接口使用顺存
- 使用glNamedBufferStorage()分配数据空间,并且在data参数中直接传递NULL
- 使用glMapBuffer()进行映射,并且直接将数据写入
- 使用glUnmapNamedBuffer()解除映射,完成数据向缓存对象传递的操作。
例如:
GLuint buffer; FILE *f; size_t filesize; //打开文件并确定它的大小 f = fopen("data.dat","rb"); fseek(f,0,SEEK_END); filesize = ftell(f); fseek(f,0,SEEK_SET); //生成缓存名字并将它绑定到缓存绑定点上 //GL_COPY WRITE BUFFER glGenBuffers(1,&buffer); glBindBuffer(GL_COPY_WRITE_BUFFER,buffer); //分配缓存中存储的数据空间,向data参数传入NULL即可 glBufferData(GL_COPY_WRITE_BUFFER,(GLsizei)filesize,NULL,GL_STATIC_DRAW); //映射缓存 void *data = glMapBuffer(GL_COPY_WRITE_BUFFER,GL_WRITE_ONLY); //将文件读入缓存 fread(data,1,filesize,f); glUnmapBuffer(GL_COPY_WRITE_BUFFER); fclose(f);
异步和显式的映射
void* glMapNamedBufferRange(GLuint buffer,GLintptr offset,GLsizeiptr length,GLbitfield access);
将缓存对象数据的全部或一部分映射到应用程序的地址空间中。
buffer设置了缓存对象的名字。
offset和length一起设置了准备映射的数据范围(单位为字节)。
access是一个位域表示符,用于描述映射的模式。
对于该函数来说,access位域中必须包含GL_MAP_READ_BIT和GL_MAP_WRITE_BIT中的一个或两个,已确认对映射数据的读写操作,并且还可以一个或多个其他标识符,如下表。
| glMapNamedBufferRange()中使用的标识符 | |
|---|---|
| 标识符 | 意义 |
| GL_MAP_INVALIDATE_RANGE_BIT | 如果设置的话,给定的缓存区域内任何数据都可以被抛弃以及无效化。如果给定区域范围内任何数据没有被随后重新写入的话,那么它将变成未定义的数据。这个标识符无法与GL_MAP_READ_BIT同时使用。 |
| GL_MAP_INVALIDATE_BUFFER_BIT | 如果设置的话,缓存的整个内容都可以被抛弃和无效化,不再受到区域范围的设置影响。所有映射范围之外的数据都会变成未定义的状态,而如果范围内的数据没有被随后重新写入的话,那么它也会变成未定义。这个标识符无法与GL_MAP_READ_BIT同时使用。 |
| GL_MAP_FLUSH_EXPLICIT_BIT | 应用程序将负责通知OpenGL映射范围内的哪个部分包含了可用数据,方法是在调用glUnmapNamedBuffer()之前调用glFlushMappedNamedBufferRange()。如果缓存中较大范围内的数据都会被映射,而并不是全部被应用程序写入的话,应当使用这个标识符。这个位标识符必须与GL_MAP_WRITE_BIT结合使用。如果GL_MAP_FLSUH_EXPLICIT_BIT没有定义的话,那么glUnmapNameBuffer()会自动刷新整个映射区域的内容 |
| GL_MAP_UNSYNCHRONIZED_BIT | 如果这个标识符没有设置的话,那么OpenGL会等待所有正在处理的缓存访问操作结束,然后再返回映射范围的内存。如果设置了这个标识符,那么OpenGL将不会尝试进行这样的缓存同步操作。 |
-
GL_MAP_FLUSH_EXPLICIT_BIT标识符搭配使用的,通知操作函数。
void glFlushMappedNamedBufferRange(GLuint buffer,GLintptr offset,GLsizeiptr length);通知OpenGL,映射缓存buffer中由offset和length所划分的区域已经发生了修改,需要立即更新到缓存对象的数据区域中。
缓存对象中独立或者相互重叠的映射范围可多次调用
glFlushMappedNamedBufferRange()。缓存对象的范围是通过offset和length划分的,这两个值必须位于缓存对象的映射范围之内,并且映射范围必须通过glMapNamedBufferRange()以及GL_MAP_FLUSH_EXPLICIT_BIT标识符来映射。当执行这个操作之后,会假设OpenGL对于映射缓存对象中指定区域的修改已经完成,并且开始执行一些相关的操作,例如重新激活数据的可用性,将它拷贝到图形处理器的显示内存中,或者进行刷新,数据缓存的重新更新等。就算缓存的一部分或者全部还处于映射状态下,这些操作也可以顺利完成。
这一操作对于OpenGL与其他应用程序操作的并行化处理事非常有意义的。举例来说,如果需要从文件加载一个非常庞大的数据块,并将他们送入缓存,那么需要再缓存中分配足够囊括整个文件大小的区域,然后读取文件的各个子块,并且对每个子块都调用一次
glFlushMappedNamedBufferRange()。然后OpenGL就可以与应用程序并行地执行一些工作,从文件读取更多的数据并且存入下一个子块当中。
4.丢弃缓存数据
如果已经完成了对缓存数据的处理,那么可以直接通知OpenGL,我们不再需要使用这些数据。例如,正在项transform feedback的缓存中写入数据,然后使用这些数据进行绘制。如果最后访问数据的是绘制命令,那么我们就可以及时通知OpenGL,让它适时地抛弃数据并且将内存用作其他用途。这样OpenGL就可以完成一些优化工作,诸如紧密的内存分配策略,或者避免系统与多个CPU之间产生代价高昂的拷贝操作。
抛弃缓存对象中的部分或者全部数据接口:
void glInvalidateBufferData(GLuint buffer);
void glInvalidateBufferSubData(GLuint buffer,GLintptr offset,GLsizeiptr length);
顶点规范
1. 深入讨论VertexAttribPointer
void glVertexAttribPointer(GLuint index,GLint size,GLenum type,GLboolean normalized,GLsizei stride,const GLvoid* pointer);
设置顶点属性在index位置可访问的数据值。
pointer 的起始位置也就是数组中的第一组数据值,它是以基本计算机单位(例如字节)度量的,有绑定到GL_ARRAY_BUFFER目标的缓存对象中的地址偏移量确定的。
size表示每个顶点中需要更新的元素个数。
type表示数组中每个元素的数据类型。
normalized表示顶点数据是否需要再传递到顶点数组之前进行归一化处理。
stride 表示数组中两个连续元素之间的偏移字节数。如果stride为0,那么在内存当中各个数据就是紧密贴合的。
glVertexAttribPointer()所设置的状态会保存到当前绑定的顶点数据对象(VAO)中。size表示属性向量的元素个数(1、2、3、4),或者是一个特殊的标识符GL_BGRA,它专用于压缩顶点数据的格式设置。
type参数设置了缓存对象中存储的数据类型。
| glVertexAttribPointer()的数据类型标识符 | |
|---|---|
| 标识符 | OpenGL类型 |
| GL_BYTE | GLbyte(有符号8位整型) |
| GL_UNSIGNED_BYTE | GLubyte(无符号8位整型) |
| GL_SHORT | GLshort(有符号16位整型) |
| GL_UNSIGNED_SHORT | GLushort(无符号16位整型) |
| GL_INT | GLint(有符号32位整型) |
| GL_UNSIGNED_INT | GLuint(无符号32位整型) |
| GL_FIXED | GLfixed(有符号16位定点型) |
| GL_FLOAT | GLfloat(32位IEEE单精度浮点型) |
| GL_HALF_FLOAT | GLhalf(16位S1E5M10半精度浮点型) |
| GL_DOUBLE | GLdouble(64位IEEE双精度浮点数) |
| GL_INT_2_10_10_10_REV | GLuint(压缩数据类型) |
| GL_UNSIGNED_INT_2_10_10_10_REV | GLuint(压缩数据类型) |
如果type传入整数类型,那么OpenGL只能将这些数据类型存储到缓存对象的内存中。OpenGL必须将这些数据转换为浮点数才可以将它们读取到浮点数的顶点属性中。执行这一转换过程可以通过normalize参数来控制。
如果normalize为GL_FALSE,那么整数将直接被强制转换为浮点数的形式,然后再传入到顶点着色器中。
如果normalize为GL_TRUE,那么数据在传入到顶点着色器之前需要首先进行归一化。为此,OpenGL会使用一个固定的依赖于输入数据类型的常数去除每个元素。如果数据类型是有符号的,那么相应计算公式如下:
f
=
c
2
b
−
1
f = \frac{c}{2^b-1}
f=2b−1c
如果数据类型是无符号的,那么相应的计算公式如下:
f
=
2
c
+
1
2
b
−
1
f = \frac{2c+1}{2^b-1}
f=2b−12c+1
f的结果是浮点数值,c表示输入的整数分量,b表示数据类型的位数(例如GL_UNSIGNED_BYTE就是8,GL_SHORT就是16,以此类推)。
整型顶点属性
另一个顶点属性的函数将整数传递到顶点属性中,它不会执行自动转换到浮点数的操作。其中I表示整型的意思。
void glVertexAttribIPointer(GLuint index,GLint size,GLenum type,GLsizei stride,const GLvoid* pointer);
它专用于向顶点着色器中传递整型的顶点属性。type必须是整型数据类型的一种,包括GL_BYTE、GL_UNSIGNED_BYTE、GL_SHORT、GL_UNSIGNED_SHORT、GL_INT,以及GL_UNSIGNED_INT。
双精度顶点属性
L表示“long”,这个函数专门用于将属性数据加载到64位的双精度浮点型顶点属性中。
void glVertexAttribLPointer(GLuint index,GLint size,GLenum type,GLsizei stride,const GLvoid* pointer);
type必须设置为GL_DOUBLE。
如果glVertexAttribPointer()函数也使用了GL_DOUBLE类型,那么实际上数据在传递到顶点着色器之前会被自动转换到32位单精度浮点型方式——即使目标顶点属性已经声明为双精度类型,例如double、dvec2、dvec3、dvec4,或者双精度的矩阵类型,例如dmat4。
但是,glVertexAttribLPointer可以保证输入数据的完整精度,并且将它们直接传递到顶点着色器阶段。
顶点属性的压缩数据格式
size的特殊的标识符GL_BGRA,type的某些特殊值,即GL_INT_2_10_10_10_REV或者GL_UNSIGNED_INT_2_10_10_10_REV,它们都对应于GLuint数据类型。
GL_INT_2_10_10_10_REV和GL_UNSIGNED_INT_2_10_10_10_REV标识符表示了一个有四个分量的数据格式,前三个分量均占据10个字节,第四个分量占据2个字节,这样压缩后的大小是一个32为单精度数据(GLuint)。
GL_BGRA可以被简单地视为GL_ZYXW的格式。根据32位字符类型的数据布局方式,数据划分如下:

顶点元素分布在一个32位单精度整数中,顺序为w、x、y、z——反转之后就是z、y、x、w,或者用来表示颜色分量,压缩顺序w、z、y、x,反转并写作颜色分量的形式就是r、g、b、a。
如果glVertexAttribPointer()的type参数设置为其中一中标识符,那么顶点数组中的每个顶点都会占据32位。这个数据会被分解为各个分量然后根据需要进行归一化(根据normalize参数的设置),最后被传递到对应的顶点属性当中。
2.静态顶点属性的规范
glEnableVertexAttribArray()和glDisableVertexAttribArray()函数,在OpenGL从顶点缓存中读取数据之前,必须使用glEnableVertexAttribArray()启用对应的顶点属性数组。
如果某个顶点属性对应的属性数组没有启用,OpenGL会使用静态顶点数组。每个顶点的静态顶点属性都是一个默认值。
单精度浮点数函数
举例来说,顶点着色器中可能需要从某个顶点属性中读取顶点的颜色值。如果某个模型中所有的顶点或者一部分顶点的颜色值是相同的,那么可以使用一个常数值来填充模型中所有顶点的数据缓存,这无疑是一种内存浪费和性能损失。因此,这可以禁止顶点属性数组,并且使用静态的顶点属性值来设置所有顶点的颜色。
void glVertexAttrib{1234}{fds}(GLuint index,TYPE values);
void glVertexAttrib{1234}{fds}v(GLuint index,const TYPE* values);
void glVertexAttrib4{bsifd ub us ui}v(GLuint index,const TYPE* values);
设置索引值为index的顶点属性的静态值。如果函数名称末尾没有v,那么最多可以指定4个参数值,即x、y、z、w参数。如果函数末尾有v,那么最多有4个参数值是保存在一个数组中传入的,它的地址通过values来指定,存储顺序依次为x、y、z和w分量。
所有函数都会自动将输入参数转换为浮点数,然后传递到顶点着色器中。对于函数中需要传入整型数值的情况,将数据归一化到[0,1]或者[-1,1]的范围内,其依据是输入参数是否为有符号(或者无符号)类型。
归一化函数
void glVertexAttrib4Nub(GLuint index,GLubyte x,GLubyte y,GLunyte z,GLubyte w);
void glVertexAttrib4N{bsi ub us ui}v(GLuint index,const TYPE* v);
设置属性index所对应的一个或者多个顶点属性值,并且在转换过程中将无符号参数归一化到[0,1]的范围,将有符号参数归一化到[-1,1]的范围。
整数或双精度浮点数函数
void glVertexAttribl{1234}{i ui}(GLuint index,TYPE values);
void glVertexAttribl{123}{i ui}v(GLuint index,const TYPE* values);
void glVertexAttribl4{bsi ub us ui}v(GLuint index,const TYPE* values);
设置一个或者多个静态整型顶点属性值,以用于index位置的整型顶点属性。
双精度浮点数函数
void glVertexAttribL{1234}(GLuint index,TYPE values);
void glVertexAttribL{1234}v(GLuint index,const TYPE* values);
设置一个或者多个静态顶点属性值,以用于index位置的双精度顶点属性。
静态顶点属性值是保存在当前VAO当中的,而不是程序对象。这也就意味着,如果当前的顶点着色器中存在一个vec3的输入属性,而我们使用glVertexAttrib*()的4fv形式设置了一个四分量的向量给它,那么第四个分量值虽然会被忽略,但是依然被保存了。如果改变顶点着色器的内容,重新设置当前属性为vec4的输入形式,那么之前设置的第四个分量值就会出现在属性w分量当中了。
绘制命令
绘制命令大致可以分为两个部分:索引形式和非索引形式的绘制。索引形式的绘制需要用到绑定GL_ELEMENT_ARRAY_BUFFER的缓存对象中存储的索引数组,它可以用来间接地对已经启用的顶点数组进行索引。另一方面,非索引的绘制不需要使用GL_ELEMENT_ARRAY_BUFFER,只需要简单地按顺序读取顶点数据即可。
非索引形式绘制
void glDrawArrays(GLenum mode,GLint first,GLsizei count);
使用数组元素建立连续的几何图元序列,每个启用的数组中起始位置为first,结束位置为first + count - 1。mode表示构建图元的类型,它必须是GL_TRIANGLES、GL_LINE_LOOP、GL_LINES、GL_POINTS等类型标识符之一。
索引形式绘制
void glDrawElements(GLenum mode,GLsizei count,GLenum type,count GLvoid* indices);
使用count个元素来定义一系列几何图元,而元素的索引位置保存在一个绑定到GL_ELEMENT_ARRAY_BUFFER的缓存中(元素数组缓存,element array buffer)。
indices定义了元素数组缓存中的偏移地址,也就是索引数据开始的位置,单位为字节。
type必须是GL_UNSIGNED_BYTE、GL_UNSIGNED_SHORT或者GL_UNSIGNED_INT中的一个,它给出了元素数组中索引数据的类型。
mode定义了图元构建的方式,它必须是图元类型标识符中的一个,例如GL_TRIANGLES、GL_LINE_LOOP、GL_LINES或者GL_POINTS。
这些函数从当前启用的顶点属性数组中读取顶点信息,然后使用它们来构建mode指定的图元类型。顶点属性数组需通过glEnableVertexAttribArray()来完成启用。
索引数据,以固定数量偏移
void glDrawElementsBaseVertex(GLenum mode,GLsizei count,GLenum type,const GLvoid* indices,GLint basevertex);
本质上与glDrawElements()并无区别,但是它的第i个元素在传入绘制命令时,实际上读取的是各个顶点属性数组中的第indices[i]+basevertex个元素。
其他索引函数
void glDrawRangeElements(GLenum mode,GLuint start,GLuint end,GLsizei count,GLenum type,const GLvoid* indices);
这是glDrawElements()的一种更严格的形式,它实际上相当于应用程序(也就是开发者)与OpenGL之间形成的一种约定,即元素数组缓存中所包含的任何一个索引值(来自indices)都会落入到start和end所定义的范围当中。
void glDrawRangeElementsBaseVertx(GLenum mode,GLuint start,GLuint end,GLsizei count,GLenum type,const GLvoid* indices,GLint basevertex);
同应用程序之间建立一种约束,其形式与glDrawRangeElemets()类似,不过它同时也支持使用basevertex来设置顶点索引的基数。在这里,这个函数将首先检查元素数组缓存中保存的数据是否落入start和end之间,然后再对其添加basevertex基数。
间接绘制函数
它们的参数不是直接从程序中得到,而是从缓存对象当中获取。
void glDrawArraysIndirect(GLenum mode,const GLvoid* indirect);
特性与glDrawArraysInstanced()完全一致,不过绘制命令的参数是从绑定到GL_DRAW_INDIRECT_BUFFER的缓存(间接绘制缓存,draw indirect buffer)中获取的结构体数据。indirect记录间接绘制缓存中的偏移地址。
mode必须是glDrawArrays()所支持的某个图元类型。
该函数的实际绘制命令参数,是从间接绘制缓存中indirect地址的结构体中获取的,这个结构体的C语言形式的声明如下:
typedef struct DrawArraysIndirectCommand_t
{
GLuint count;
GLuint primCount;
GLuint first;
GLuint baseInstance;
} DrawArraysIndirectCommand;
first和count会被直接传递到内部函数中。primCount表示多实例的个数,而baseInstance就相当于多实例顶点属性的baseInstance偏移。
// 创建顶点数据
float vertices[] = {
-0.5f, -0.5f, 0.0f,
0.5f, -0.5f, 0.0f,
0.0f, 0.5f, 0.0f
};
// 创建 VBO 并绑定数据
GLuint VBO;
glGenBuffers(1, &VBO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 创建并编译着色器程序
GLuint shaderProgram = createShaderProgram(vertexShaderSource, fragmentShaderSource);
glUseProgram(shaderProgram);
// 获取顶点属性位置
GLint posAttrib = glGetAttribLocation(shaderProgram, "aPos");
glEnableVertexAttribArray(posAttrib);
// 设置顶点属性指针
glVertexAttribPointer(posAttrib, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
// 创建并设置间接绘制命令缓冲区
GLuint drawCommands;
glGenBuffers(1, &drawCommands);
glBindBuffer(GL_DRAW_INDIRECT_BUFFER, drawCommands);
// 定义绘制命令
struct DrawArraysIndirectCommand {
GLuint count;
GLuint instanceCount;
GLuint first;
GLuint baseInstance;
};
DrawArraysIndirectCommand command = {3, 1, 0, 0}; // 绘制3个顶点,从索引0开始
glBufferData(GL_DRAW_INDIRECT_BUFFER, sizeof(command), &command, GL_STATIC_DRAW);
//绘制函数
// 渲染
glClearColor(0.2f, 0.3f, 0.3f, 1.0f);
glClear(GL_COLOR_BUFFER_BIT);
// 使用间接绘制命令
glBindBuffer(GL_DRAW_INDIRECT_BUFFER, drawCommands);
glDrawArraysIndirect(GL_TRIANGLES, NULL);
void glDrawElementsIndirect(GLenum mode,GLenum type,const GLvoid* indirect);
本质上与glDrawElements()是一致的,但是绘制命令的参数是从绑定到GL_DRAW_INDIRECT_BUFFER的缓存中获取的。
indirect记录了间接绘制缓存中的偏移地址。mode必须是glDrawElements()所支持的某个图元类型,而type指定了绘制命令调用时元素数组缓存中索引值的类型。
typedef struct DrawElementsIndirectCommand_t
{
GLuint count;
GLuint primCount;
GLuint firstIndex;
GLuint baseVertex;
GLuint baseInstance;
} DrawElementsInidrectCommand;
count和baseVertex会被直接传递到内部函数中。
primCount也表示多实例的个数,
firstIndex可以与type参数所定义的索引数据大小相结合,以计算传递到glDrawElementsIndirect()的索引数据结果。
baseInstance用来表示结果绘制命令中,所有多实例顶点属性的实力偏移值。
多变量形式绘制函数
每个函数都记录了一个first参数的数组,以及一个count参数的数组,其工作方式相当于对每个数组的元素,都会执行一次原始的单一变量函数。
- glMultiDrawArrays
void glMultiDrawArrays(GLenum mode,const GLint* first,const GLint* count,GLsizei primcount);
在一个OpenGL函数调用过程中绘制多组几何图元集。first和count都是数组的形式,数组的每个元素都相当于一次glDrawArrays()调用,元素的总数有primcount决定。
调用glMultiDrawArrays()等价于下面的OpenGL代码段:
void glMultiDrawArrays(GLenum mode,const GLint *first,const GLint *count,GLsizei primcount)
{
GLsizei i;
for(i = 0;i < primcount;i++)
{
glDrawArrays(mode,first[i],count[i]);
}
}
- glDrawElements()的多变量版本就是glMultiDrawElements(),它的原型如下:
void glMultiDrawElements(GLenum mode,const GLint* count,GLenum type,const GLvoid* const* indices,GLsizei primcount);
在一个OpenGL函数调用过程中绘制多组几何图元集。first和indices都是数组的形式,数组的每个元素都相当于一次glDrawElements()调用,元素的总数由primcount决定。
函数等价代码如下:
void glMultiDrawElements(GLenum mode,const GLsizei* count,GLenum type,const GLvoid* const* indices,GLsizei primcount)
{
GLsizei i;
for(i= 0;i < primcount;i++)
{
glDrawElements(mode,count[i],type,indices[i]);
}
}
- glMultiDrawElements扩展版本,包含额外baseVertex参数
void glMultiDrawElementsBaseVertex(GLenum mode,const GLint* count,GLenum type,const GLvoid* const* indices,GLsizei primcount,const GLint* baseVertex);
在一个OpenGL函数调用过程中绘制多组几何图元集。first、indices和baseVertex都是数组的形式,数组的每个元素都相当于一次glDrawElementsBaseVertex()调用,元素的总数由primcount决定。
函数等价代码如下:
void glMultiDrawElementsBaseVertex(GLenum mode,const GLsizei*count,GLenum type,const GLvoid* const* indices,GLsizei primcount,const GLint *baseVertex)
{
GLsizei i;
for(i = 0;i < primcount;i++)
{
glDrawElementsBaseVertex(mode,count[i],type,indices[i],baseVertex[i]);
}
}
间接绘制多变量版本
void glMultiDrawArraysIndirect(GLenum mode,const void* indirect,GLsizei drawcount,GLsizei stride);
绘制多组图元集,相关参数全部保存到缓存对象中。在一次调用当中,可以分发总共drawcount个独立的绘制命令,命令中的参数与glDrawArraysIndirect()所用的参数是一致的。
每个DrawArraysIndirectCommand结构体之间的间隔都是stride个字节。如果stride是0的话,那么所有的数据结构体构成一个紧密排列的数组。
void glMultiDrawElementsIndirect(GLenum mode,GLenum type,const void* indirect,GLsizei drawcount,GLsizei stride);
绘制多组图元集,相关参数全部保存到缓存对象中。在一次调用中,可以分发总共drawcount个独立的绘制命令,命令中的参数与glDrawElementsIndirect()所用的参数是一致的。
每个DrawElementsIndirectCommand结构体之间的间隔都是stride个字节。如果stride是0,那么所有的数据结构体将构成一个紧密排列的数组。
图元重启动
当需要处理较大的顶点数据集时,可能会被迫执行大量的OpenGL绘制操作,并且每次绘制的内容总是与前一次图元的类型相同(例如GL_TRIANGLE_STRIP)。这时,也可以使用glMultiDraw*()形式的函数,但是这样需要额外区管理图元的起始索引位置和长度的数组。
OpenGL支持在同一个渲染命令中,进行图元重启动的功能,此时需要指定一个特殊的值,叫做图元重启动索引(primitive restart index),OpenGL内部会对它做特殊的处理。如果绘制调用过程中遇到这个重启动索引,那么就会从这个索引之后的顶点开始,重新开始进行相同图元类型的渲染。
图元重启动索引的定义是通过glPrimitiveRestartIndex()函数来完成的。
void glPrimitiveRestartIndex(GLuint index);
设置一个顶点数组元素的索引值,用来指定渲染过程中,从什么地方启动新的图元绘制。如果在处理顶点数组元素索引的过程中遇到一个符合该索引的数值,那么系统不会处理它对应的顶点数据,而是终止当前的图元绘制,并且从下一个顶点重新开始渲染同一类型的图元集合。
如果顶点的渲染需要在 glDrawElements() 系列的函数调用中完成,那么可以用 glPrimitiveRestartIndex() 所指定的索引,并检查这个索引值是否会出现在元素数组缓存中。这种检查需要启用图元重启动特性,是否启用可以通过glEnable()和glDisable()函数来完成,调用的参数为GL_PRIMITIVE_RESTART。
示例:
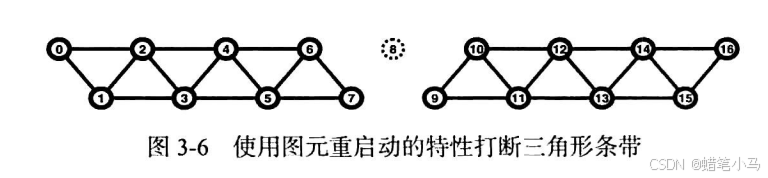
对于上图中的顶点布局,它给出了一个三角形条带,并且通过图元重启动的方式打断为两个部分。在图中,图元重启动索引设置为8。在三角形渲染过程中,OpenGL会一直监控元素数组缓存中是否出现索引8,当这个值出现的时候,OpenGL不会创建一个顶点,而是结束当前的三角形条带绘制。下一个顶点(索引9)将成为一个新的三角形条带的第一个顶点,因此我们最终构建了两个三角形条带。
多实例渲染
实例化(instancing)或者多实例渲染(instanced rendering)是一种执行多条相同的渲染命令的方法,并且每个渲染命令所产生的结果会有轻微的差异。
-
glDrawArrays多实例
void glDrawArraysInstanced(GLenum mode,GLint first,GLsizei count,GLsizei primCount);通过mode、first和count所构成的几何体图元集(相当于glDrawArrays函数所需的独立参数),绘制它的primCount个实例。对于每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同实例的顶点属性。
-
glDrawElements多实例
void glDrawElementsInstanced(GLenum mode,GLsizei count,GLenum type,const void* indices,GLsizei primCount);通过mode、count和indices所构成的几何体图元集(相当于glDrawElements()函数所需的独立参数),绘制它的primCount个实例。对于每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同实例的顶点属性。
void glDrawElementsInstancedBaseVertex(GLenum mode,GLsizei count,GLenum type,const void* indices,GLsizei instanceCount,GLuint baseVertex);通过mode、count、indices和baseVertex所构成的几何体图元集(相当于glDrawElementsBaseVertex()函数所需的独立参数),绘制它的instanceCount个实例。对于每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同实例的顶点属性。
-
多实例的顶点属性
多实例的顶点属性与正规的顶点属性是类似的。它们需要保存到缓存对象中,可以通过
glGetAttribLocation()查询,通过glVertexAttribPointer()来设置,以及通过glEnableVertexAttribArray()和glDisableVertexAttribArray()进行启用与禁用。以下函数用来启用多实例的顶点属性:
void glVertexAttribDivisor(GLuint index,GLuint divisor);设置多实例渲染时,位于index位置的顶点着色器中顶点属性是如何分配到每个实例的。
divisor的值如果是0的话,那么该属性的多实例特性将被禁用,而其他的值则表示顶点着色器,每divisor个实例都会分配一个新的属性值。
该函数用于控制顶点属性更新的频率。index表示设置多实例特性的顶点属性的索引位置,它与传递给
glVertexAttribPointer()和glEnableVertexAttribArray()的索引值一致。默认情况下,每个顶点都会分配到一个独立的属性值。如果divisor设置为0的话,那么顶点属性将遵循这一默认,非实例化规则。
如果divisor设置为一个非零的值,那么顶点属性将启用多实例的特性,此时OpenGL从属性数组中每隔divisor个实例都会读取一个新的数值(而不是每个顶点)。此时在这个属性所对应的顶点属性数组中,数据索引值的计算将会变成instance/divisor的形式,其中instance表示当前的实力数目,而divisor就是当前属性的更新频率值。
对于每个多实例的顶点属性来说,在顶点着色器中,每个实例中的所有顶点都会共享同一个属性值。如果divisor设置为2的话,那么每两个实例会共享同一个属性值;如果值为3,那就是每三个实例。
-
其他多实例接口
void glDrawArraysInstancedBaseInstance(GLenum mode,GLint first,GLsizei count,GLsizei instanceCount,GLuint baseInstance);对于通过mode、first和count所构成的几何体图元集,绘制它的instanceCount个实例。对与每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同的实例的顶点属性。此外,baseInstance的值用来对实例化的顶点属性设置一个索引的偏移值,从而改变OpenGL取出的索引位置。
void glDrawElementsInstancedBaseInstance(GLenum mode,GLsizei count,GLenum type,const GLvoid* indices,GLsizei instanceCount,GLuint baseInstance);对于通过mode、count和indices所构成的几何体图元集,绘制它的instanceCount个实例。对于每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同实例的顶点属性。此外,baseInstance的值用来对实例化的顶点属性来设置一个索引的偏移值,从而改变OpenGL取出的索引位置。
void glDrawElementsInstancedBaseVertexBaseInstance(GLenum mode,GLsizei count,GLenum type,const GLvoid* indices,GLsizei instanceCount,GLuint baseVertex,GLuint baseInstance);对于通过mode、count、indices和baseVertex所构成的几何体图元集,绘制它的instanceCount个实例。对于每个实例,内置变量gl_InstanceID都会依次递增,新的数值会被传递到顶点着色器,以区分不同实例的顶点属性。baseInstance的值用来对实例化的顶点属性设置一个索引的偏移值,从而改变OpenGL取出的索引位置。

















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









