







使用豪斯多夫距离从大型自然数据集中自动提取相似的交通场景
论文概述
“Automatic extraction of similar traffic scenes from large naturalistic datasets using the Hausdorff” 这篇论文主要讨论了使用Hausdorff距离自动从大型自然交通数据集中提取相似交通场景的方法。
(1) 论文的主要内容包括:
- 动机和背景:介绍了大型自然交通数据集的重要性以及从这些数据集中提取有价值信息的挑战。同时介绍了Hausdorff距离的概念和其在相似性度量中的应用。
- 方法:论文提出了一种基于Hausdorff距离的自动场景提取方法。该方法首先通过车辆轨迹数据构建场景表示,然后使用Hausdorff距离度量不同场景之间的相似性,并应用聚类算法将相似的场景分组。
- 实验和结果:论文描述了使用不同自然交通数据集进行的实验,并展示了场景提取方法的有效性和准确性。通过比较提取的场景与人工标注的场景,证明了方法的可靠性和可扩展性。
- 应用和潜在应用:论文讨论了场景提取方法的应用领域,包括交通行为建模、智能交通系统设计等。同时探讨了该方法在其他类似任务中的潜在应用性。
- 结论和展望:论文总结了基于Hausdorff距离的自动场景提取方法的优点和局限性,并对未来的研究方向和改进进行了展望。
该论文的主要目的是提出一种自动场景提取方法,通过使用Hausdorff距离度量场景之间的相似性,实现对大型自然交通数据集中相似交通场景的自动识别和提取。该方法可以帮助研究人员和工程师们从大规模数据集中提取有用的交通场景,进而支持交通行为建模、交通系统设计和决策等领域的应用。
(2) 什么是Hausdorff距离,具体是怎么使用的,是以什么指标类提取数据集中相似场景的
Hausdorff距离是一种度量两个点集之间的相似性的方法,它衡量了两个点集之间的最大差异或最远距离。在场景提取中,Hausdorff距离被用来度量不同交通场景之间的相似性。
具体使用Hausdorff距离进行相似场景提取的方法如下:
场景表示:首先,将交通数据集中的车辆轨迹数据转化为场景表示。通常可以使用车辆的位置、速度、加速度等信息来描述一个场景。
距离计算:对于数据集中的每个场景,计算其与其他场景之间的Hausdorff距离。Hausdorff距离的计算基于两个点集之间的最远点对之间的欧氏距离。通过比较不同场景之间的距离,可以得到它们的相似性度量。
聚类分组:根据Hausdorff距离的相似性度量结果,应用聚类算法将相似的场景分组在一起。常用的聚类算法包括k均值聚类、层次聚类等。聚类分组的目的是将具有相似特征和行为的场景归为一类。
相似场景提取:从每个聚类中选择代表性的场景作为相似场景的代表。这些代表性场景可以是每个聚类的中心或具有高度相似度的样本。
通过使用Hausdorff距离作为相似性度量指标,可以从数据集中提取具有相似行为和特征的交通场景。Hausdorff距离考虑了两个场景之间的最大差异,因此能够捕捉到场景之间的关键差异和相似性。这样的相似场景提取方法可以帮助研究人员和工程师们更好地理解和分析交通数据,从而支持交通行为建模、智能交通系统设计和决策等领域的应用。
(3) highD数据集是如何进行场景表示的?
在highD数据集中,场景表示是通过将车辆的轨迹数据转化为场景描述来实现的。每个场景都由一系列车辆轨迹组成,而每个轨迹则包含了车辆在时间上的连续运动信息。
具体而言,对于每个场景,以下信息通常被用来表示场景:
- 位置信息:包括车辆在场景中的坐标位置,通常以二维或三维空间中的(x, y, z)坐标表示。
- 速度信息:车辆在每个时间点上的速度,表示车辆的运动状态。
- 加速度信息:车辆在每个时间点上的加速度,用于描述车辆的加减速行为。
- 方向信息:车辆的行进方向,可以使用角度或方向向量表示。
- 车辆类型信息:车辆的类型,例如汽车、卡车、摩托车等,用于区分不同类型的车辆。
- 时间戳信息:每个时间点的时间戳,用于对车辆轨迹进行时间上的排序和对齐。
以上信息可以被组织成结构化的数据形式,例如使用表格或字典的形式存储。每个场景都对应着一个或多个车辆轨迹,而每个轨迹又包含了时间上连续的车辆运动信息。
通过这样的场景表示方式,研究人员可以对highD数据集中的交通行为进行分析、建模和可视化。这种场景表示方式使得高维的轨迹数据变得更加易于理解和处理,为交通研究和应用提供了有价值的信息。
(4)highD数据集场景可视化表示啥,如何提取,基于什么指标来提取特定场景?
在highD数据集中,场景可视化表示是指将车辆轨迹数据以图形方式呈现,以便更直观地观察和分析交通行为。通过可视化,可以展示车辆在不同场景下的运动轨迹、车辆类型、速度、加速度等信息,帮助理解交通流动和行驶模式。
在提取特定场景时,常用的方法是基于一些特定的指标或规则来识别具有相似特征的轨迹组合,从而形成特定的场景。这些指标和规则可以根据具体的研究目的和场景定义进行定义和调整。
一种常见的指标是基于车辆之间的空间关系和运动特征来提取场景。例如,可以使用聚类算法(如K-means、DBSCAN等)将轨迹分组成具有相似运动模式的簇,每个簇代表一个场景。相似性度量可以考虑车辆之间的距离、速度差异、行进方向等。
另一种方法是基于时间窗口的概念,将时间上连续的轨迹视为一个场景。通过定义一个时间窗口大小,并检查轨迹在时间窗口内的连续性和相似性,可以将具有相似行驶模式的轨迹组合到同一个场景中。
此外,还可以基于交通场景的语义特征进行提取,例如车辆的行驶位置(高速公路、城市道路等)、交通流量、车辆类型分布等。这些特征可以帮助识别不同的交通场景,并对交通行为进行更细粒度的分析和建模。
总而言之,提取highD数据集中的特定场景可以基于空间关系、运动特征、时间窗口等指标,以及交通场景的语义特征。这些方法和指标的选择取决于具体的研究目的和场景定义。
摘要
最近,多个人类驱动轨迹的自然交通数据集已经发表(例如,highD、NGSim和pNEUMA)。这些数据集已被用于调查人类驾驶行为可变性的研究,例如基于场景的自动车辆(AV)行为验证、对驾驶员行为,或验证驾驶员模型。到目前为止,这些研究关注的是作战层面(例如,变道期间的速度分布)的可变性,而不是战术层面(即是否改变车道)。研究这两个层次上的可变性对于开发包含多种战术行为的驾驶员模型和自动驾驶汽车是必要的。为了暴露多层次的可变性,可以调查人类对同一交通场景的反应。然而,没有一种方法可以从数据集中自动提取类似的场景。在这里,我们提出了一个四步提取方法,使用豪斯多夫距离,一个数学距离度量的集合。我们在高D数据集上进行了一个案例研究,结果表明该方法是实际适用的。人类对所选场景的反应暴露了两种战术的可变性
1 介绍
近年来,多个开放获取的自然数据集已经发表。其中一些数据集是通过首先使用安装好的摄像头(如NGSIM [1])或无人机(如highD [2]和pNEUMA [3])录制交通视频来构建的。然后使用图像识别技术从这些视频中提取轨迹数据。这些数据集包含了通过一个特定区域的所有车辆的运动轨迹。
研究人员将这些数据集用于多种目的,其中包括:基于场景的自动驾驶车辆(AV)行为验证(见[4]综述),对驾驶员行为进行建模和预测(例如,[5]-[7]),以及验证用于自动驾驶车辆的驾驶员模型(例如,[8])。在所有这些应用中,可变性(可以预期的人类行为的范围,有时被称为不确定性),在司机的行为中是相关的。
目前,可变性主要被认为是在操作驾驶行为的水平上(例如,[5],[6],[9]-[11])。操作驾驶行为考虑了机动[12]的执行,例如变道。然而,在战术层面上也存在着变化,即当驾驶员对交通场景[12]作出反应时的机动选择。例如,一些司机可能会对车道上行驶较慢的车辆做出反应,而另一些司机则会在同样的情况下刹车。
理解作战和战术层面上的可变性对于评估AV行为的人类相似性和可接受性,以及验证AV[8]中使用的人类驾驶员模型都很重要。原因是这两种应用程序都必须考虑在给定条件下所有可能的战术行为。另一方面,传统的驾驶员模型大多针对特定的战术行为(例如,智能驾驶员模型[13]中的汽车跟踪),因此对于它们的应用,只有操作变化是相关的。在设计描述多种战术行为的驾驶员模型时,战术行为也需要理解其的可变性。
为了充分研究驾驶员的行为可变性,必须(自动地)从前面提到的数据集中提取类似的交通场景,以便比较人类对这些场景的反应。然而,大多数自动提取方法选择了交通场景(参见[4]的审查),而不是交通场景。根据Ulbrich等人[14]的说法,场景“描述了多个场景之间的时间发展”,其中“交通场景描述了环境的快照,包括场景和动态元素。”(讨论的数据集中的动态元素是(人类驱动的)车辆)。这些定义表明,(提取的)交通场景包括了一个轨迹的一部分。在大多数情况下,相似的轨迹描述了相同的战术行为。因此,选择相似的交通场景隐式地意味着选择相似的战术响应。其他一些方法甚至可以显式地提取数据对应于预先指定的战术行为(例如,[6],[8]中的车道变化)。
这些现有的方法暴露了一个给定的战术机动的作战执行的可变性,但忽略了战术行为的可变性。此外,将轨迹作为自动提取数据的一部分,合并了初始交通场景(即驾驶员的反应)和驾驶员本身的反应。这使得调查人类对特定初始交通场景的反应的全部变化程度变得更加困难。
一种从自然数据集中自动提取类似交通场景的方法将支持对操作和战术层面上的驾驶员行为可变性的研究。利用这种方法,可以从作战和战术特征方面研究初始场景的轨迹。然而,据我们所知,所有已经提出的从数据中自动提取交通场景的方法都不能提取交通场景。
本文提出了一种从大型自然数据集中自动提取类似交通场景的方法(关于示意图概述,见图1)。为了进一步指定与比较人类响应的初始交通场景相关的部分,我们引入了交通上下文的概念。我们将交通背景定义为在给定时间内所有周围车辆的所有位置和速度。与完整的交通场景相比,交通环境不包括风景和自我车辆的状态。因此,交通环境代表了自我-车辆所响应的场景的各个方面。
我们提出的方法依赖于距离度量的概念来表达交通上下文实例之间的差异。我们使用数学集[15]的豪斯多夫距离作为距离度量,以找到与手动选择的交通上下文的例子最近的可用场景。该方法在GitHub [16]上得到了一个实现,作为流量可视化软件TraViA [17]的扩展。我们在一个使用highD数据集的案例研究中验证了该方法,其中我们证明了该方法是实际适用的,并提供了对驾驶员行为的操作和战术可变性的见解。
2 提出的方法
我们提出的方法由四个步骤组成(图1)。本节将简要介绍这些步骤,并在案例研究中应用时进行更详细的解释。在第一步中,人们应该从数据集中手动选择一个感兴趣的场景的示例。此示例表示应该找到多个实例的感兴趣的交通场景。在第二步中,此示例中的流量上下文将被转换为数学集(上下文集)。然后,将使用“豪斯多夫距离”来确定选定场景中的交通上下文与数据集中的所有其他场景之间的距离。最后,选择与示例距离最短的N个上下文。生成的场景是与整个数据集上的示例最相似的流量上下文的场景。
豪斯多夫距离是由费利克斯·豪斯多夫在1914年[15]提出的数学集的距离度量。它可以是用于表示两个非空紧化集之间的距离。许多关于豪斯多夫距离以及如何计算它的解释可以在文献(如[18])和在线中找到。例如,维基百科的[19]声明:
非正式地,如果两个集合的每一点都接近另一个集合的某个点,则这两个集合在豪斯多夫距离上很接近。豪斯多夫距离是对手在两个集合中选择一个点的最长距离,然后你必须从那里走到另一个集合。换句话说,它是从一个集合中的一个点到另一个集合中的最近点的所有距离中最大的
我们确实想指出的另一个重要方面是,与豪斯多夫距离相比的集合可以包含不同数量的点。这确保了可以比较具有不同车辆数量的场景。
3 案例研究:方法
在这个案例研究中,我们利用高D数据集[2]来显示我们所提出的方法的潜力。高D数据集由德国记录在6个不同高速公路地点的交通数据组成。该数据集由60个独立的录音组成。为了可视化数据并生成在本工作中使用的图像,我们使用了TraViA可视化软件[17]。实现该方法的源代码可以作为TraViA [16]的扩展公开提供。
A.步骤1:选择一个示例
该方法的第一步是选择一个场景的例子,其中响应的可变性是研究的主题。我们将把这个场景称为感兴趣的交通场景。这个例子应该是在一个特定的时间点,从一个被选择的自我载体的角度来看。对于高级数据集,这意味着该示例可以完全由三个数字的组合来定义:数据集id、车辆id和帧号。对于这个案例研究,我们选择了如图2所示的示例。这个场景可以在数据集1,帧379中找到,自我车辆id为21。
选择这个例子是因为自我车辆(蓝色,id 21)的驾驶员可以以多种(战术)方式响应这个场景,如图2所示:驾驶员可以决定留在它当前跟随的车辆后面(id 20),但也可以决定加速和超过该车辆。以下车辆(id25和26)和自我车辆之间的进展足够大(95米和128.7米),可以允许自我车辆改变车道,但也足够小,可以预期它们的存在会对自我车辆的行为产生一些影响。
B.步骤2:提取上下文集
我们提出的方法的第二步是将交通上下文转换为一个四维点的数学集。我们将把这个集合称为由上下文点组成的上下文集。对于周围的每一个车辆,都有一个上下文点。上下文集可以包含任何数字的上下文点,这取决于被假定为交通上下文的一部分的周围车辆的数量。在我们的案例研究中,我们使用了highD提供的定义来确定构成交通背景的车辆。在高D数据集中,每个自我车辆都报告了周围车辆的8个位置。我们假设这些周围的车辆构成了交通环境。
为了将周围车辆的状态转换为上下文点,每个车辆的二维位置在自我车辆的参考系中表示。然后,将每个车辆的二维绝对速度(沿相同的轴表示)连接到相对位置。结果是每个周围的车辆都有一个4维点。在数学形式中,表示单个周围车辆的单一上下文点可以表示为
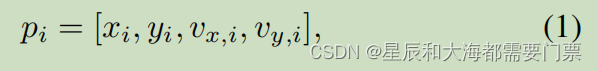
式中,i表示周围车辆的第i个位置,x和y表示车辆相对于自我车辆和vx的中心x位置和y位置,vy表示x和y方向上的速度。
如式1中所做的那样,定义上下文点的一个潜在问题是,点之间的可变性在纵向(x)方向上的可变性将比在横向(y)方向上大得多。这将反映在上下文集之间的豪斯多夫距离上。要举一个例子,请考虑图2中的场景。图2与车辆20在左车道上行驶的另一个场景之间的豪斯多夫距离将等于图2与车辆20和21之间的间隙比一个车道宽度小的场景之间的距离。直观地说,在第一次比较中应该有一个更大的距离。为了解释这种直觉,我们引入了参数λ来缩放上下文点的横向维度。使用新的参数λ时,上下文点的定义将变为
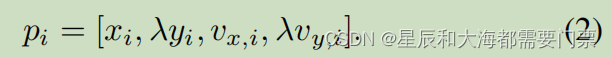
在我们的案例研究中,我们假设λ=为10.0。这与周围车辆横向位置变化1米与纵向位置变化10米同样重要的概念相一致。
C. 步骤3:应用豪斯多夫距离
现在交通上下文已经被表示为一个数学集,我们可以使用豪斯多夫距离来比较不同的上下文集。该方法的这一步要求计算所选示例的上下文集和数据集中所有帧数和车辆id的可能组合的上下文集之间的豪斯多夫距离。对于高D数据集,有39.7的6次方个这样的组合。因为这是大量需要计算的距离,我们将在计算距离之前通过过滤相关的车辆来减少它。
当搜索具有相似交通背景的场景时,一个重要的方面是自我车辆正在行驶的车道。这决定了周围车辆可以在哪里,自我车辆可以在哪个方向变道(例如,在中心车道行驶的车辆可以向左和向右行驶,但在左车道行驶的车辆只能向右变道)。因此,我们只考虑在选定例中与自我车辆在同一相对车道上行驶的车辆。我们考虑了4种可能的相对车道:左车道、中心车道、右车道和合并车道。我们在选定的示例中确定车道(例如,图2:右车道),并且只使用来自车辆在同一相对车道中行驶的数据集中的车辆框架组合。在我们的案例研究中,这只剩下12,515,286个车架组合。
如果在应用此滤波器后,要计算的结果距离数仍然太大,则可以考虑对帧进行降采样。根据所选数据集的特定帧率,我们可以假设流量上下文在一定的帧数内没有本质上的差异,因此只查看所有帧的一个子集。这将减少需要计算的距离数,甚至进一步。在我们的案例研究中,这是不必要的,因为所需的距离计算的结果数量被证明是可行的。
D. 步骤4:获取场景
当计算出所有的豪斯多夫距离时,通过选择N个最短的距离,可以很容易地获得数据集中最接近该示例的场景。这里唯一需要注意的是,连续的数据帧非常相似,这导致具有相同车辆id的组和许多连续的帧数与感兴趣的场景示例非常相似(短的)豪斯多夫距离。这个问题可以通过根据最短的距离对所有结果进行排序来解释,只保持每辆车的最高入口。从结果表中选择前N个条目将得到最终结果
4 案例研究:结果
我们在一个案例研究中使用了所提出的方法,从高数据数据集中提取了250个具有相似流量上下文的场景。在步骤1中,对感兴趣的场景的手工选择的示例如图2所示。该方法产生了250个场景,其中交通上下文最接近本例。结果的上下文点的分布如图3所示。在图3中描述的250个场景中,233精确地包含了3个周围的车辆,与图2中描述的场景中的数量相同。其他17个场景包含了4辆周围的车辆
图3显示出,所提出的从数据集中自动选择场景的方法成功地选择了与感兴趣场景的流量上下文相似的上下文集。请注意,本图中的三个集群并不是三个独立的分布分布。集合之间的豪斯多夫距离可以解释为集合中的点之间的权衡。如果一个远离这个例子,另外两个需要更近,以导致一个较短的豪斯多夫距离。因此,一个集合内的点不能被看作是来自独立分布的样本。
图3还显示了结果的扩散在纵向上比在横向上大。例如,在纵向位置上,所发现的集合与所选示例之间的最大差异约为25 m,其中最大横向偏差约为2m。这些值对应于所使用的λ值为10。
结果中的可变性确实取决于数据的量和感兴趣的场景。所提出的方法可以找到最接近的可用集,因此,如果示例表示一个更常见的场景或要搜索的数据集更大,则可以期望所找到的上下文集有更低的可变性。可变性也可以通过选择更少的上下文集来减少,即选择N = 100最近的集而不是N = 250,但这是与产生的可变性估计的力量的权衡。
在其他用例中,这些结果可用于研究针对人类对类似交通上下文的反应的可变性。为了说明这些结果的效用,图4显示了这些人类的反应:一些司机变道,而大多数人仍在跟踪和减速。图中还显示了多个时间点的纵向和横向分布的核密度估计。这些估计的分布可以用来验证以分布的形式进行预测的驱动程序模型。该图说明了所提出的方法的两个潜在好处:该方法可以用于提取人类对不同战术行为做出反应的场景,并且可以从对这些选定场景的反应中估计出人类行为的分布。
结论
在本文中,我们提出了一种从大型自然数据集中自动提取相似交通场景的新方法。在一个对高D数据集的案例研究中,我们证明了所提出的方法是实用的,并提供了深刻的结果,揭示了人类对类似交通场景的反应的操作和战术可变性。因此,我们提出的方法可以成为一个有价值的工具,以开发自动驾驶车辆和交通系统,将人类的反应纳入他们的控制决策。此外,该案例研究还表明,人类对相似的交通场景的反应具有不同的战术行为(有些人会改变车道,而另一些人则呆在最初的车道上)。
与我们的方法相关的其他一种方法是那些集群场景的方法。正如引言中所讨论的,获得相似场景与提取相似场景具有不同的用例。然而,聚类需要一个距离度量,这使得它可以与我们的方法相媲美。有两种特定的轨迹聚类方法与我们的方法相似。在[20]中,使用了与我们的方法相同的距离度量:豪斯多夫距离。然而,在他们的方法中,当我们将交通上下文转换为一个数学集时,它被用来确定两个轨迹之间的距离。在[21]中,提出了另一种基于自我车辆周围的网格和与其他车辆的纵向距离的场景距离度量方法。虽然确实可以仅通过纵向距离找到类似的场景,但我们基于豪斯多夫距离的方法更为完整,因为它还考虑了周围车辆的横向位置和纵向和横向速度。
使用自然的交通数据集并不是调查人类对同一场景反应的可变性的唯一方法,驾驶模拟器实验是一个成熟的替代方法。在驾驶模拟器中,多个参与者可以使用相同的交通环境进行完全相同的场景。然而,自然数据应该应用于一些应用,例如在验证自动驾驶汽车[8]的人类驾驶员模型时。在其他情况下,可能需要大量不同的驱动因素(例如,当人们对整个人群的行为感兴趣时)。这将使驾驶模拟器的实验更加耗时和昂贵。因此,我们提出的基于自然数据的方法来研究人类对类似交通环境的反应是一种有价值的新方法。
所提出的方法有四个主要的限制,其中一些可以在未来的工作中加以解决。首先,没有足够的方法来从人类的角度来确定两个交通场景的相似程度。这意味着所选场景之间的异同的大小,以及模型的性能,都无法被量化。构建这种度量的最好方法是通过让人类体验从数据集中选择的场景对,从人类那里收集相似性评级。
第二,车辆的尺寸没有考虑到交通环境。如果这些维度被认为对回答一个人的研究问题很重要,那么这可以在后处理步骤中得到解决。然而,这可能会限制所提取的场景的数量。第三,忽略了自我载体的初始速度。这是有目的的,因为我们认为自我车辆的初始速度是人类反应的一部分,而不是交通环境的一部分。当使用结果数据验证考虑这些信息的驱动程序模型时,这是一个限制。包括自我载体的速度可以通过将自我载体作为位置(0.0,0.0)上下文设置的额外上下文点来实现。
最后,目前还没有系统的方法来确定参数λ。其他车辆的纵向和横向位置的相对重要性可能取决于许多因素,如车辆的速度、道路尺寸和目标场景。研究λ参数的影响,并开发一个系统的方法来确定它可以是未来工作的主题。
在本文中,我们展示了来自高数据集的一个例子的案例研究。虽然我们相信这是一个说明性的例子,但它只显示了我们的方法对单个场景的结果。为了帮助复制这些结果,并允许在高d数据集的其他场景上进行复制(包括生成图形),我们公开共享了我们的方法[16]的源代码。未来的研究还可以使用这段代码来系统地研究我们的方法在不同的应用程序和其他交通数据集上的使用。
5 结论
我们的结论是:
- 该方法基于豪斯多夫距离,可用于从一个大型自然数据集中选择具有相似交通上下文的场景。
- 通过提取的场景,人类反应的可变性将被调查,独立于执行的机动,并且不需要昂贵和耗时的驾驶模拟器实验。
- 研究人类对这些场景的反应(即从相似的初始条件演变而来的轨迹)暴露了人类在作战和战术层面上的反应的可变性。
6 参考文献
[16] O. Siebinga, “Hausdorff Scene Extraction.” https://github.com/tudhri/hausdorffsceneextraction, 2022.
[20] S. Atev, G. Miller, and N. P. Papanikolopoulos, “Clustering of vehicle
trajectories,” IEEE Transactions on Intelligent Transportation Systems,
vol. 11, no. 3, pp. 647–657, 2010.
“车辆轨迹的聚集”,《智能交通系统学报》,第11卷,第3页
[21] J. Kerber, S. Wagner, K. Groh, D. Notz, T. Kuhbeck, D. Watzenig, and
A. Knoll, “Clustering of the Scenario Space for the Assessment of Automated Driving,” IEEE Intelligent Vehicles Symposium, Proceedings,
no. Iv, pp. 578–583, 2020.
“自动驾驶评估场景空间的聚类”,IEEE智能车辆研讨会,论文集,第1期
豪斯多夫距离定义
https://en.wikipedia.org/wiki/Hausdorff_distance




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











