







 本文详细介绍了CANdb++和DBC文件中的字节顺序,包括Intel与Motorola的不同模式,如IntelStandard、IntelSequential、MotorolaForwardLSB等。这些概念对于理解CAN总线上的数据解析至关重要,特别是在信号的起始位和字节顺序安排方面。同时,文章还提及了位索引的概念,帮助读者深入理解CAN信号的组织方式。
本文详细介绍了CANdb++和DBC文件中的字节顺序,包括Intel与Motorola的不同模式,如IntelStandard、IntelSequential、MotorolaForwardLSB等。这些概念对于理解CAN总线上的数据解析至关重要,特别是在信号的起始位和字节顺序安排方面。同时,文章还提及了位索引的概念,帮助读者深入理解CAN信号的组织方式。

目录
2.3 字节顺序 “ Motorola Forward LSB”
2.4 字节顺序 “ Motorola Forward MSB”
2.5 字节顺序 “Motorola Sequential”
关键字:
MSB:信号的最高位;
LSB:信号的最低位;
Motorola Forward LSB;
Motorola Backward;
Motorola Sequential;
Motorola Forward MSB;
Intel Standard;
Intel Sequential;
Intel:little endian小端;
Motorola:big endian大端;
Start bit:起始位;
Byte order:字节顺序。
推荐阅读(单击下方文字即可跳转至对应博文):
1、【DBC专题】-1-如何使用CANdb++ Editor创建并制作一个DBC
2、【DBC专题】-2-CAN Signal信号的Multiplexor多路复用在DBC中实现
3、【DBC专题】-3-利用CANdb++ Editor在DBC文件添加帧CAN_ID和信号CAN_Signal
4、【DBC专题】-4-DBC文件中的Signal信号字节顺序Motorola和Intel介绍
0 概述
1 Bit Index位索引

2 Intel 和Motorola的细分介绍
2.1 字节顺序 “Intel Standard”

2.2 字节顺序 “Intel Sequential”

2.3 字节顺序 “ Motorola Forward LSB”

2.4 字节顺序 “ Motorola Forward MSB”

2.5 字节顺序 “Motorola Sequential”

2.6 字节顺序 “ Motorola Backward”
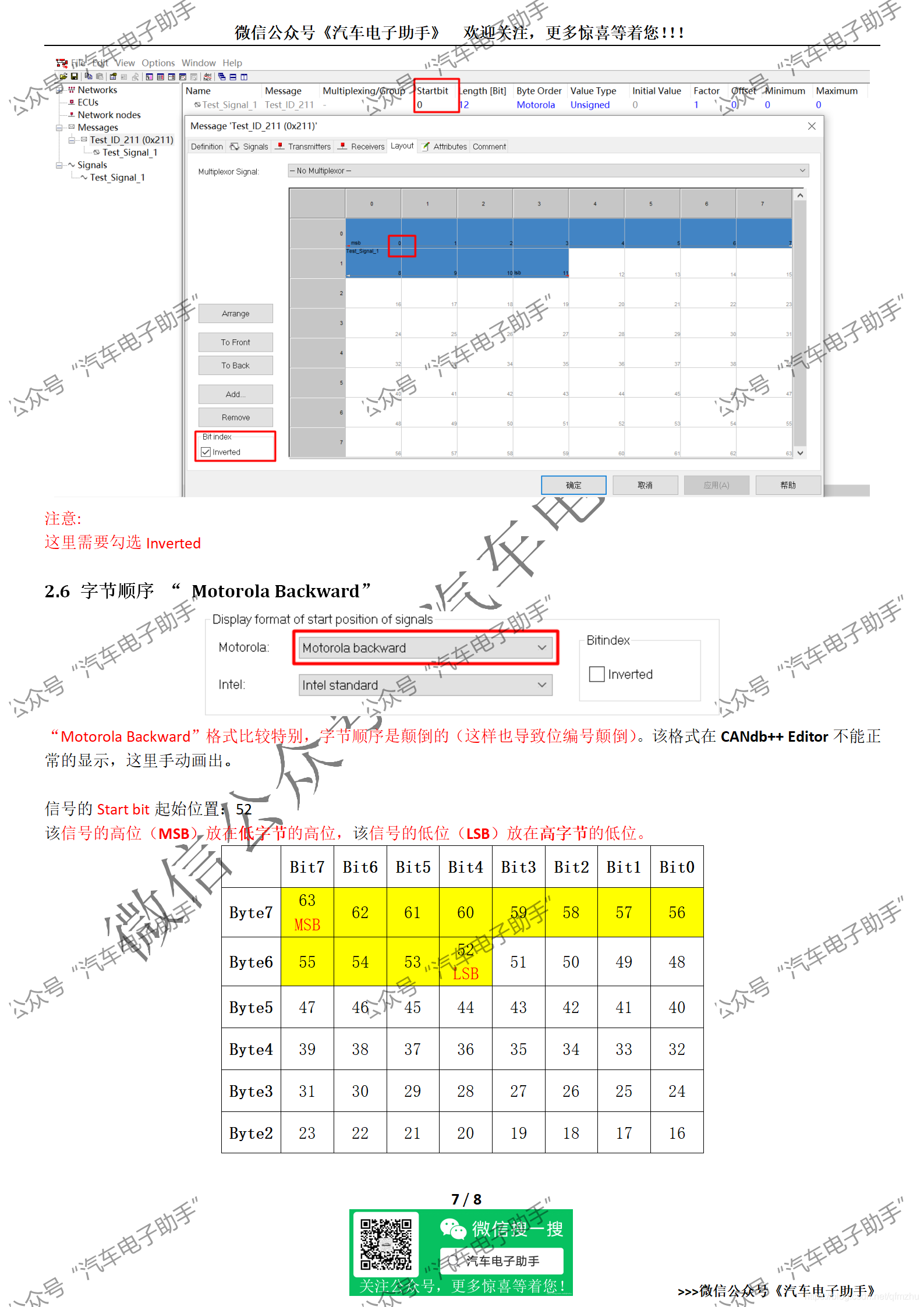
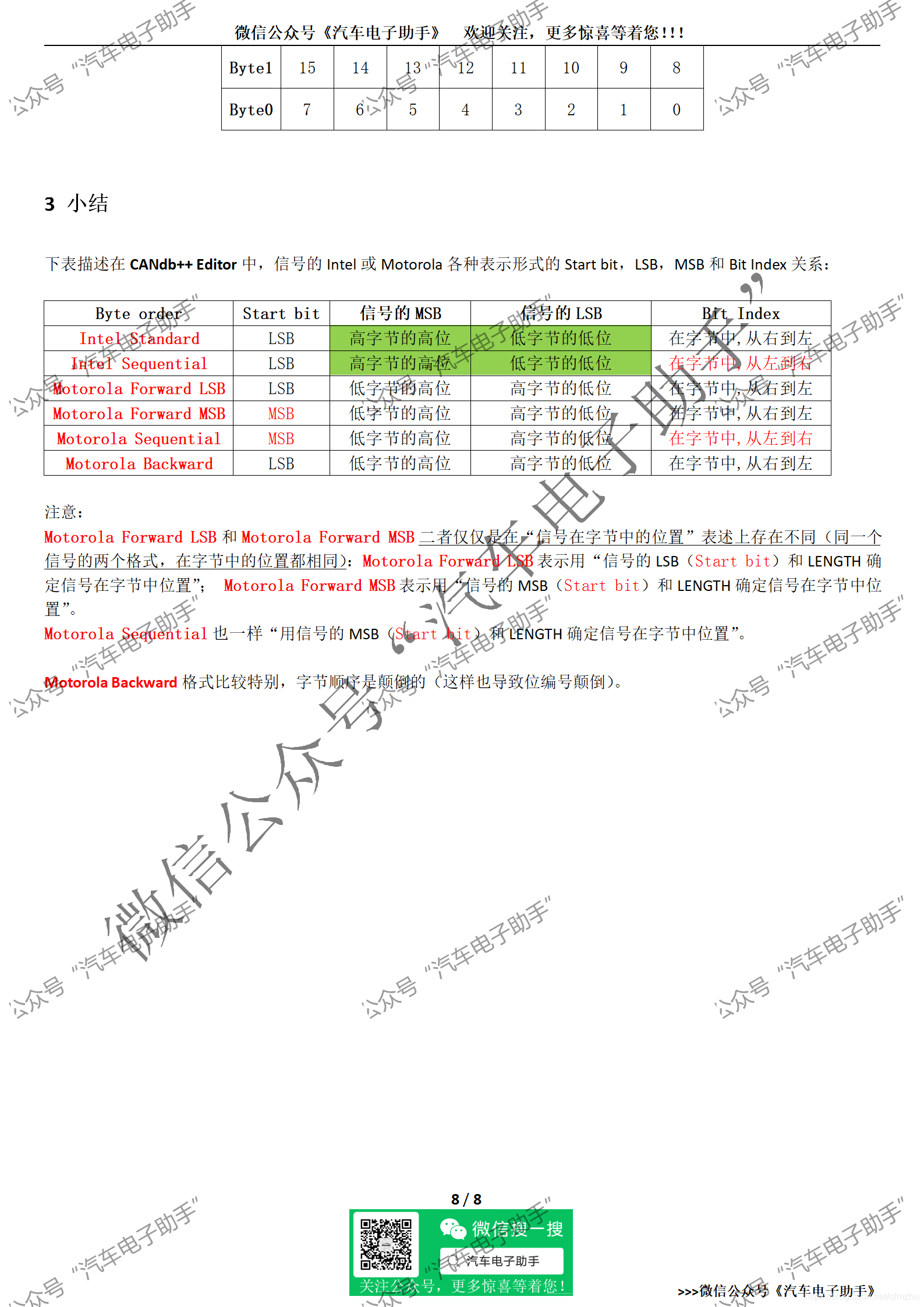
3 小结
推荐阅读(单击下方文字即可跳转至对应博文):
1、【DBC专题】-1-如何使用CANdb++ Editor创建并制作一个DBC
2、【DBC专题】-2-CAN Signal信号的Multiplexor多路复用在DBC中实现
3、【DBC专题】-3-利用CANdb++ Editor在DBC文件添加帧CAN_ID和信号CAN_Signal
4、【DBC专题】-4-DBC文件中的Signal信号字节顺序Motorola和Intel介绍
4 结尾



















 3255
3255





 到【灌水乐园】发言
到【灌水乐园】发言









