



【12】CNN-BIGRU- KDE采用了 CNN-BIGRU 结构,并使用了 KDE(核密度估计)来对模型的预测结果进行评估。 考虑了预测值的单点预测和区间预测,计算了不同置信区间下的区间覆盖率和区间平均宽度百分比等指标,用于评估模型的区间预测能力。
在机器学习和深度学习的广阔领域中,不断涌现出各种新颖的模型结构和评估方法,今天就来聊聊这个CNN - BIGRU - KDE模型。
CNN - BIGRU结构探秘
CNN(卷积神经网络)在处理图像、音频等数据时展现出强大的特征提取能力。它通过卷积层、池化层等操作,能够有效地挖掘数据中的局部特征。比如在Python的Keras库中构建一个简单的CNN层代码如下:
from keras.models import Sequential
from keras.layers import Conv2D
model = Sequential()
model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(img_width, img_height, channels)))这里Conv2D层中,32表示输出的特征图数量,(3, 3)是卷积核的大小,activation='relu'使用ReLU激活函数对输出进行非线性变换。
而BIGRU(双向门控循环单元)结合了GRU的优势,能够处理序列数据中的长期依赖关系。双向的结构可以同时从正向和反向两个方向对序列进行学习,从而更全面地捕捉序列信息。以下是使用TensorFlow构建BIGRU层的代码示例:
import tensorflow as tf
from tensorflow.keras.layers import Bidirectional, GRU
model.add(Bidirectional(GRU(64)))Bidirectional包裹GRU层,64是GRU隐藏单元的数量。
当CNN与BIGRU结合,就可以充分利用CNN强大的特征提取能力和BIGRU对序列信息的处理能力,在一些时空序列数据等场景中发挥独特优势。
KDE(核密度估计)评估预测结果
KDE在这里用于对模型的预测结果进行评估。它可以理解为一种非参数的概率密度函数估计方法。在实际应用中,比如我们得到了模型的一系列预测值,就可以通过KDE来估计这些预测值的概率密度分布。在Python中,scikit - learn库提供了方便的KDE实现,代码如下:
from sklearn.neighbors import KernelDensity
import numpy as np
# 假设y_pred是模型的预测值
y_pred = np.array([1.2, 1.5, 1.8, 2.1, 2.3])
kde = KernelDensity(kernel='gaussian', bandwidth=0.2).fit(y_pred.reshape(-1, 1))这里kernel='gaussian'表示使用高斯核,bandwidth=0.2是核的带宽参数,它控制着估计的平滑程度。带宽越小,估计越接近数据点,曲线越不平滑;带宽越大,曲线越平滑。
预测能力评估指标
这个模型考虑了单点预测和区间预测。对于区间预测能力的评估,采用了区间覆盖率和区间平均宽度百分比等指标。
区间覆盖率指的是真实值落在预测区间内的比例。假设我们有n个样本,m个样本的真实值落在预测区间内,那么区间覆盖率就是m / n。
区间平均宽度百分比是所有预测区间宽度的平均值与数据范围的比例。计算这两个指标能够更全面地评估模型的区间预测能力。
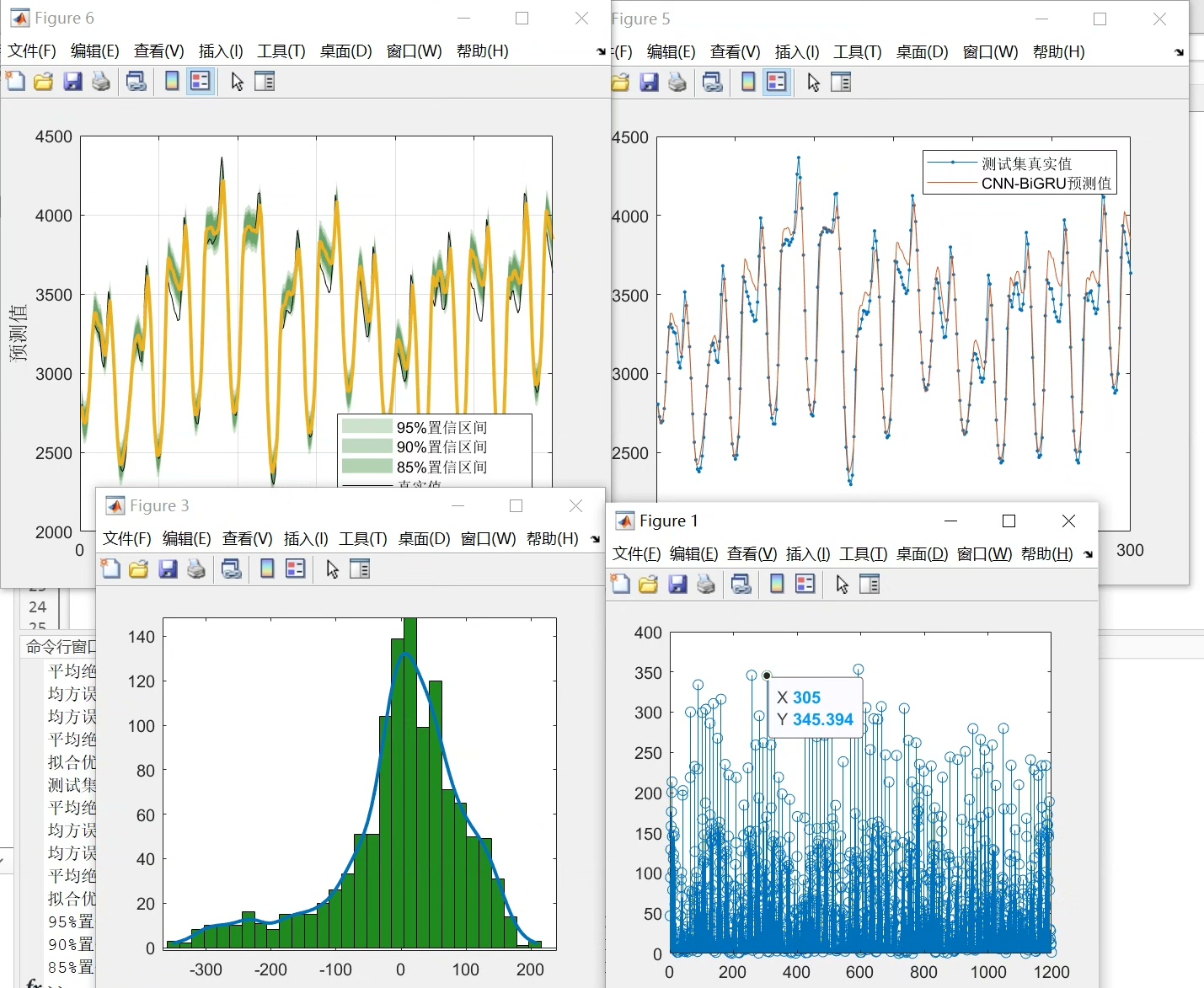
总之,CNN - BIGRU - KDE这种结合了强大模型结构与有效评估方法的组合,为我们在相关领域的预测任务中提供了一种新的思路和有力工具。

















 530
530

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









