



基于深度强化学习的混合动力汽车能量管理策略 ,混动汽车能量管理模型,混合动力汽车能量管理 1.利用DQN算法控制电池和发动机发电机组的功率分配 2.状态量为需求功率和SOC,控制量为EGS功率t91 3.奖励函数设置为等效油耗和SOC维持 4.可以将DQN换成DDPG或者TD3
嘿,各位汽车技术爱好者们!今天咱们来聊聊超火的混合动力汽车能量管理。混动汽车可是当下汽车领域的热门,它结合了燃油发动机和电池电机的优势,能在不同工况下灵活切换动力源,既能减少油耗又能降低排放。不过,要让混动汽车的性能达到最佳,能量管理策略就显得尤为重要啦。
混动汽车能量管理模型
想象一下,混动汽车就像一个小王国,电池和发动机发电机组就是这个王国里的两位“大将”,它们各自有着不同的“战斗力”(功率)。能量管理模型的任务,就是合理地指挥这两位“大将”,让它们在不同的战斗场景(行驶工况)下发挥出最大的优势。
在这个模型里,我们把需求功率和电池的荷电状态(SOC)作为状态量。需求功率就像是战场上的敌人强度,告诉我们当前需要多大的能量来应对;SOC 则像是电池这位“大将”的体力值,我们得时刻关注它,不能让它过度劳累(SOC 过低),也不能让它太闲(SOC 过高)。而控制量呢,就是发动机发电机组(EGS)的功率 t91,我们通过调整这个功率,来实现电池和 EGS 之间的功率分配。
深度强化学习算法登场
深度强化学习是解决混动汽车能量管理问题的一把利器。这里我们先以 DQN(Deep Q-Network)算法为例。
DQN 算法控制功率分配
DQN 算法的核心思想是让智能体(就像我们派去指挥“大将”的军师)在环境(混动汽车的行驶工况)中不断尝试不同的行动(调整 EGS 功率 t91),通过与环境的交互获得奖励(反馈),从而学习到最优的行动策略。
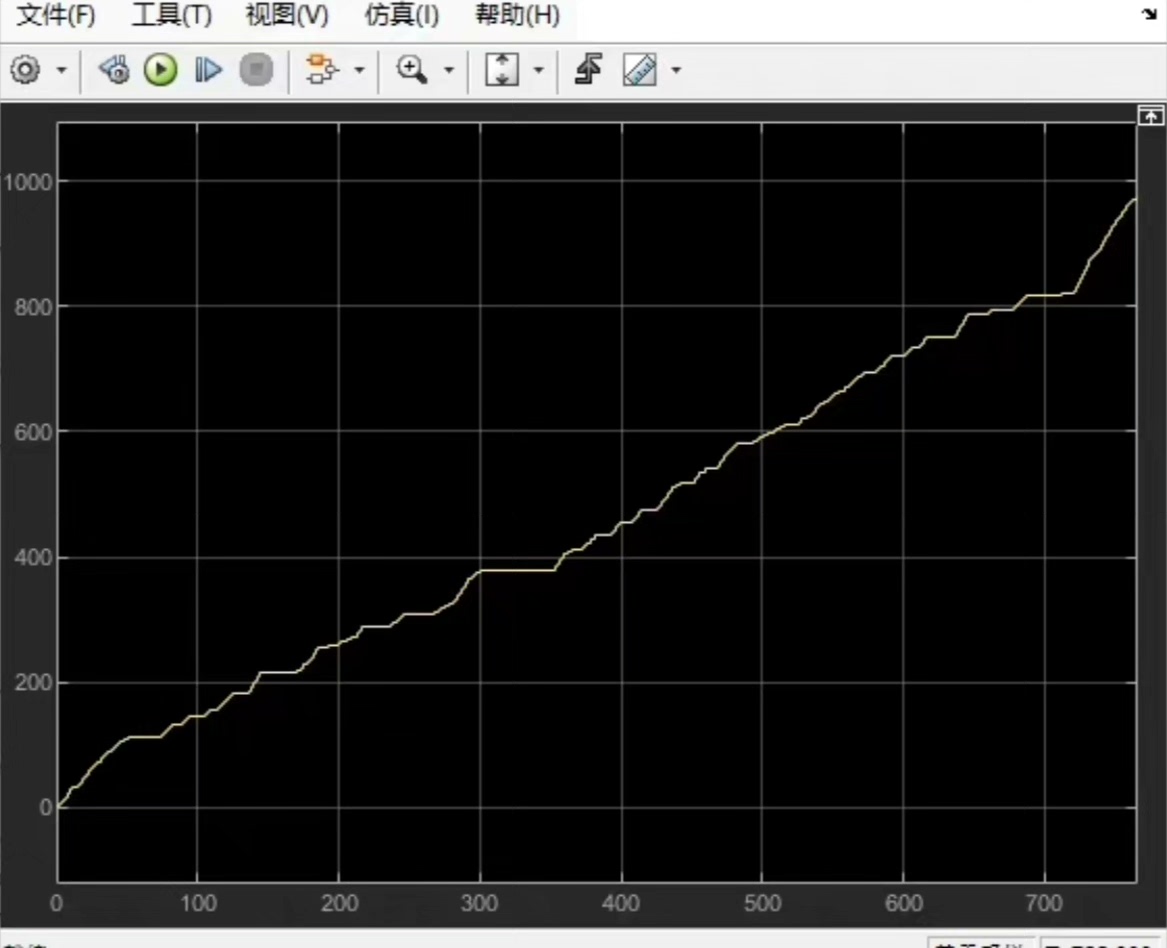
下面是一段简单的伪代码,来展示 DQN 算法在混动汽车能量管理中的基本流程:
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
# 定义 DQN 网络
class DQN(nn.Module):
def __init__(self, input_dim, output_dim):
super(DQN, self).__init__()
self.fc1 = nn.Linear(input_dim, 64)
self.fc2 = nn.Linear(64, 64)
self.fc3 = nn.Linear(64, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
return self.fc3(x)
# 初始化参数
input_dim = 2 # 需求功率和 SOC 作为输入
output_dim = 10 # 离散的 EGS 功率动作空间
dqn = DQN(input_dim, output_dim)
optimizer = optim.Adam(dqn.parameters(), lr=0.001)
gamma = 0.9 # 折扣因子
# 训练循环
for episode in range(1000):
# 初始化状态:需求功率和 SOC
state = np.random.rand(2)
state = torch.FloatTensor(state).unsqueeze(0)
total_reward = 0
for step in range(200):
# 根据 DQN 网络选择动作
q_values = dqn(state)
action = torch.argmax(q_values).item()
# 执行动作,得到下一个状态和奖励
next_state, reward = perform_action(action, state)
next_state = torch.FloatTensor(next_state).unsqueeze(0)
# 计算目标 Q 值
target_q = reward + gamma * torch.max(dqn(next_state)).item()
# 计算当前 Q 值
current_q = q_values[0][action]
# 计算损失
loss = nn.MSELoss()(current_q, target_q)
# 反向传播和优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
state = next_state
total_reward += reward
print(f"Episode {episode}: Total Reward = {total_reward}")代码分析
这段代码实现了一个简单的 DQN 训练过程。首先,我们定义了一个 DQN 网络,它有三层全连接层。输入维度是 2,对应需求功率和 SOC;输出维度是 10,表示离散的 EGS 功率动作空间。
在训练循环中,我们每次初始化一个随机的状态,然后根据 DQN 网络输出的 Q 值选择动作。执行动作后,我们得到下一个状态和奖励。接着,我们计算目标 Q 值和当前 Q 值,并计算它们之间的损失。最后,通过反向传播和优化更新 DQN 网络的参数。
奖励函数的设置
奖励函数就像是给智能体的“成绩单”,告诉它哪些行动是好的,哪些是不好的。在混动汽车能量管理中,我们的奖励函数主要考虑等效油耗和 SOC 维持。
等效油耗是指把电池的电能消耗也换算成燃油消耗,这样就能综合衡量整个能量系统的效率。我们希望等效油耗越低越好,所以在奖励函数中,等效油耗越低,奖励值就越高。
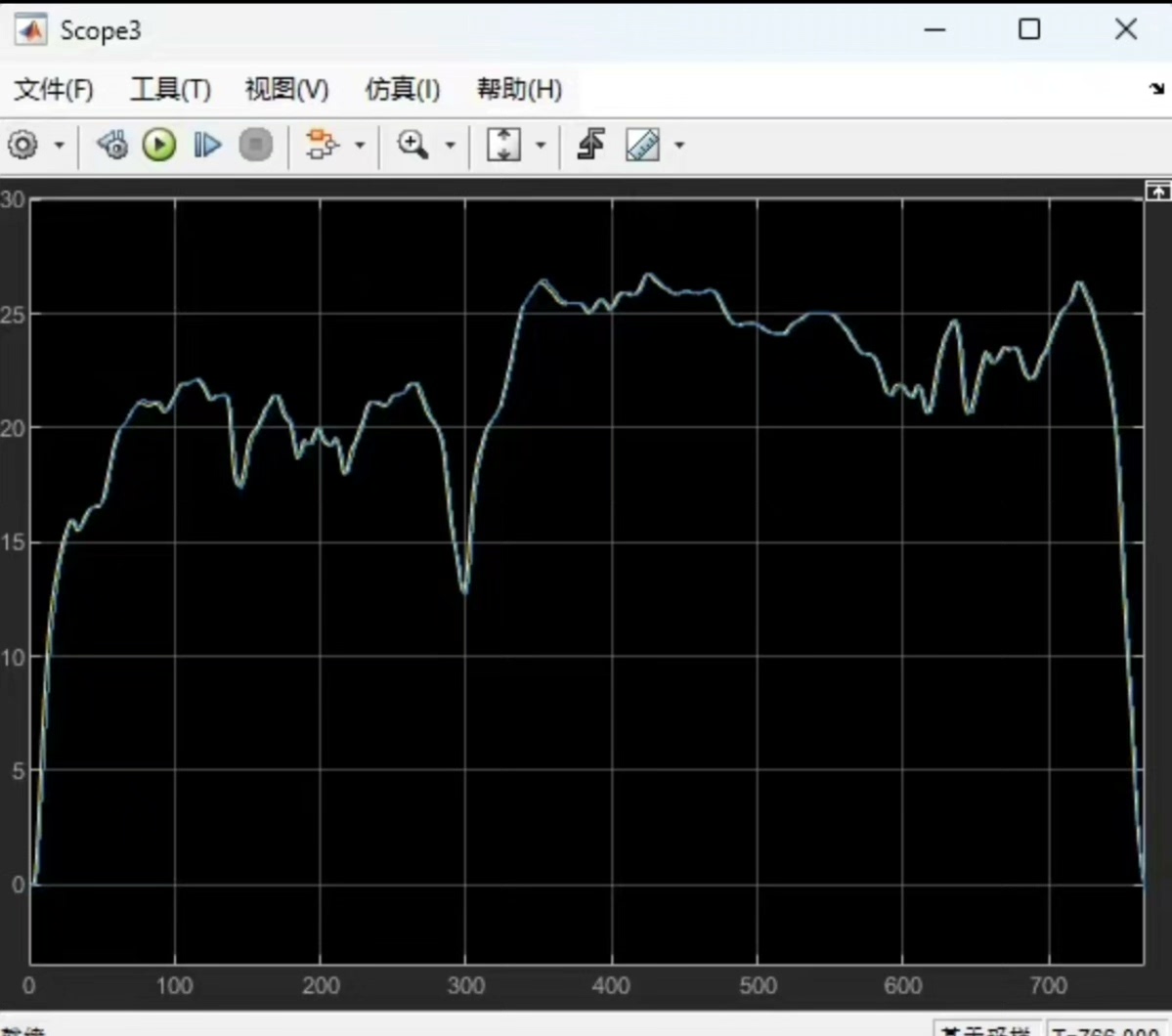
SOC 维持也很重要,我们希望电池的 SOC 能保持在一个合理的范围内,既不能过高也不能过低。如果 SOC 偏离了这个范围,奖励值就会降低。
下面是一个简单的奖励函数示例:
def reward_function(equivalent_fuel_consumption, soc):
# 等效油耗权重
fuel_weight = 0.8
# SOC 权重
soc_weight = 0.2
# 目标 SOC
target_soc = 0.5
# 计算等效油耗奖励
fuel_reward = -equivalent_fuel_consumption
# 计算 SOC 奖励
soc_error = abs(soc - target_soc)
soc_reward = -soc_error
# 综合奖励
reward = fuel_weight * fuel_reward + soc_weight * soc_reward
return reward其他深度强化学习算法
除了 DQN 算法,我们还可以使用 DDPG(Deep Deterministic Policy Gradient)或者 TD3(Twin Delayed Deep Deterministic Policy Gradient)算法。这些算法在处理连续动作空间时表现更好,因为 EGS 功率是一个连续的变量,使用这些算法可以更精确地控制功率分配。
总之,基于深度强化学习的混合动力汽车能量管理策略为我们提供了一种智能、高效的能量管理方法。通过合理设置状态量、控制量和奖励函数,结合不同的深度强化学习算法,我们可以让混动汽车的性能更上一层楼。未来,随着技术的不断发展,相信深度强化学习在汽车领域会有更广泛的应用。
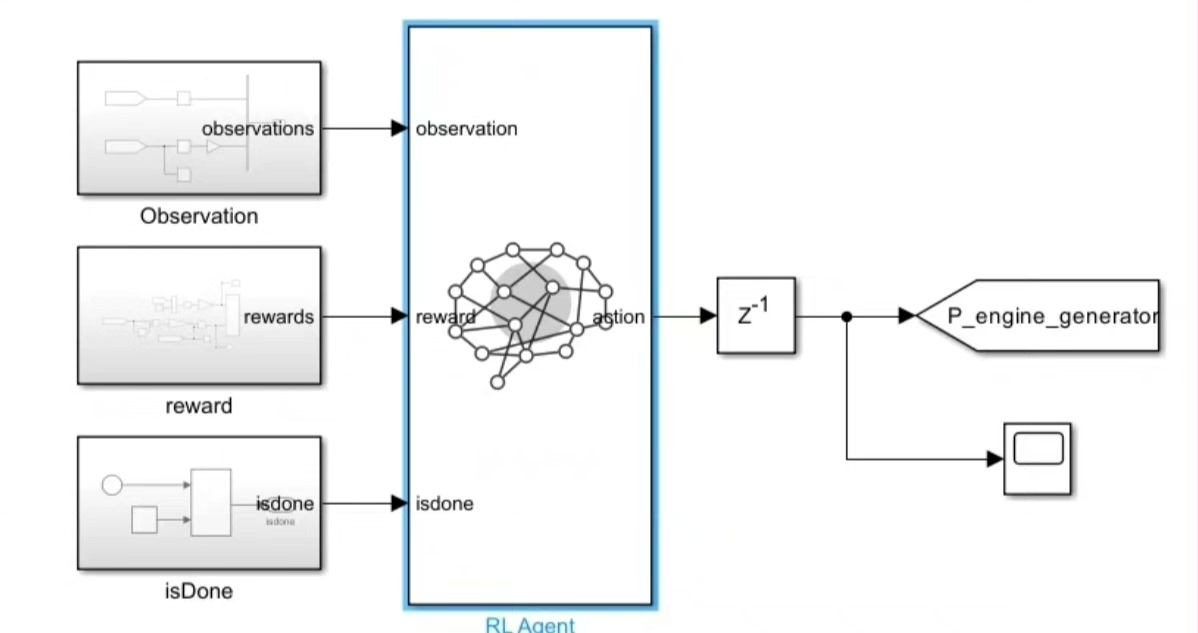
好啦,今天的分享就到这里,希望大家对混动汽车能量管理有了更深入的了解!如果你有任何想法或者问题,欢迎在评论区留言讨论。

















 54
54

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









