




1.常用数据形式
此处所说的数据形式是指数据集中的数据加载到模型中的形式,常见数据形式包括全批次Batch、迷你批次Mini-Batch。全批次Batch处理是指在每次迭代中处理整个数据集,计算损失函数和参数梯度,然后更新模型参数。这种方法每次更新参数都需要遍历所有样本,导致计算量大、速度慢,不适合在线学习场景。但是如果数据输入变为串行,将无法充分利用GPU的并行计算优势。而迷你批次Mini-Batch处理通过每次仅处理一小部分数据来进行梯度计算,既能够利用GPU的并行处理能力,又能减轻处理大规模数据集时的计算负担,且在训练过程中可以动态调整模型参数,更好地适应在线学习的需求。
常见的一些参数:
-
Epoch(训练周期):指对整个训练数据集进行一次完整的前向传播和后向传播。在每个Epoch中,模型会遍历所有的训练样本。
-
Batch-Size(批次大小):指在一次前向传播和后向传播中处理的训练样本数量。批次大小决定了每次迭代中处理的数据量。
-
Iteration(迭代):指在一个Epoch中,模型进行的前向传播和后向传播的次数。迭代次数等于训练样本总数除以批次大小(即
total_samples / batch_size)。每次迭代处理一个批次的数据,进行一次参数更新。
例如,如果一个训练数据集有1000个样本,批次大小设置为100,那么在一个Epoch中,模型将进行10次迭代(1000 / 100 = 10),每次迭代处理100个样本。

Dataset是一个抽象类,定义了数据集的基本结构和操作方法,主要用于存储数据和标签,能够返回数据集中样本的数量,并能根据索引获取数据集中的一个样本及其对应的标签。直接import的Dataset是一个抽象类,不能被直接实例化,需要重新构造Dataset的子类,再去实例化,且该子类必须实现__init__、__getitem__、__len__这三个核心方法,直接使用PASS是不可以的,一定要准确定义该类应该如何访问和处理数据集。
DataLoader是一个迭代器,用于从 Dataset中加载数据,并提供更高级的数据加载功能,如批量加载、打乱数据、多线程加载、数据采样等。可直接使用DataLoader的API完成该任务:
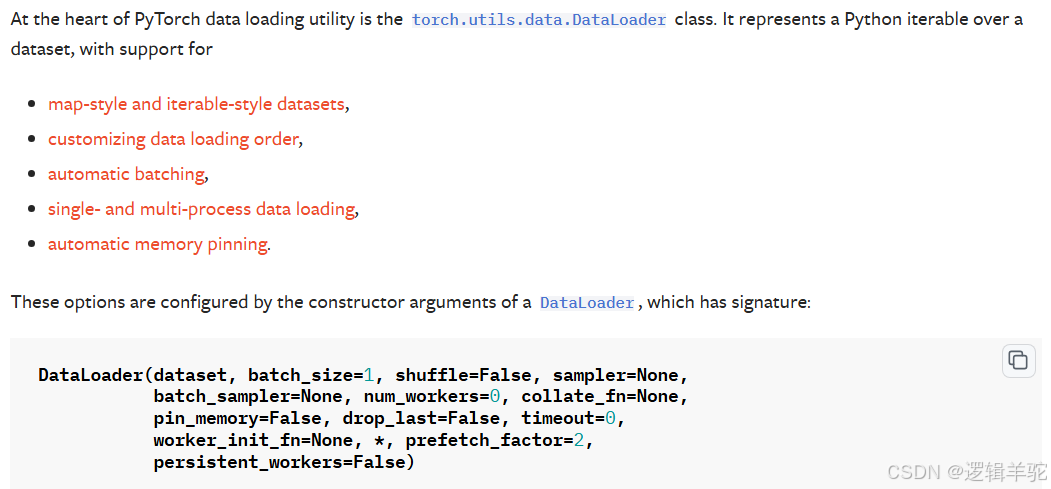
-
dataset:要加载的数据集,是一个实现了
__getitem__和__len__方法的Dataset对象。 -
batch_size:每个批次中的样本数量。如果设置为
None,则每个批次将包含所有数据集中的样本。 -
shuffle:如果设置为
True,则在每个epoch开始时打乱数据集,确保每个批次的样本都是随机选取的。如果不打乱数据可能导致模型学习到这种顺序偏差,而不是数据的真实特征。 -
sampler:定义从数据集中抽取样本的策略。如果指定了
sampler,则shuffle参数将被忽略。 -
batch_sampler:类似于
sampler,但用于生成批次的索引。如果指定了batch_sampler,则batch_size、shuffle、sampler和drop_last参数将被忽略。 -
num_workers:用于数据加载的工作进程数。如果设置为0,则数据加载将在主进程中进行。设置为大于0的值可以加速数据加载,但可能会增加内存消耗。
-
collate_fn:一个函数,用于在将多个样本数据合并成一个批次之前对它们进行处理。默认情况下,它简单地堆叠张量。
-
pin_memory:如果设置为
True,则数据加载器会在返回之前将数据固定到内存中,这可以加速CPU到GPU的数据传输。 -
drop_last:如果设置为
True,则如果数据集的大小不能被batch_size整除,则丢弃最后一个不完整的批次。 -
timeout:数据加载器等待工作进程完成加载的时间(以秒为单位)。如果设置为0,则不会等待。
-
worker_init_fn:一个函数,用于在工作进程启动时调用,可以用于设置一些特定的环境变量或种子。
-
prefetch_factor:(关键字参数)预取批次的数量,用于提高数据加载的效率。默认值为2。
-
persistent_workers:(关键字参数)如果设置为
True,则在迭代器耗尽后保持工作进程活跃,这可以加速后续迭代器的开始。默认值为False。
class DiabetesDataset(Dataset): #Dataset是抽象类,不能被实例化
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index): #魔法方法,可直接把类当函数使用
return self.x_data[index],self.y_data[index]
def __len__(self): #魔法方法,可直接把类当函数使用
return self.len
dataset=DiabetesDataset('diabetes.csv.gz')
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=2)
2.完整代码
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import numpy as np
import matplotlib.pyplot as plt
class DiabetesDataset(Dataset): #Dataset是抽象类,不能被实例化
def __init__(self,filepath):
xy=np.loadtxt(filepath,delimiter=',',dtype=np.float32)
self.len=xy.shape[0]
self.x_data=torch.from_numpy(xy[:,:-1])
self.y_data=torch.from_numpy(xy[:,[-1]])
def __getitem__(self,index): #魔法方法,可直接把类当函数使用
return self.x_data[index],self.y_data[index]
def __len__(self): #魔法方法,可直接把类当函数使用
return self.len
dataset=DiabetesDataset('diabetes.csv.gz')
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True)
class Model(torch.nn.Module):
def __init__(self):
super(Model,self).__init__()
self.linear1=torch.nn.Linear(8,6)
self.linear2=torch.nn.Linear(6,4)
self.linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
x=self.sigmoid(self.linear3(x))
return x
model=Model()
criterion=torch.nn.BCELoss(reduction='mean') #计算损失,括号内的参数是是否算平均值
optimizer=torch.optim.SGD(model.parameters(),lr=0.01)
loss_list=[]
for epoch in range(100):
for i,data in enumerate(train_loader,0):
inputs,labels=data
y_pred=model(inputs)
loss=criterion(y_pred,labels)
loss_list.append(loss.item())
print(epoch,i,loss.item())
optimizer.zero_grad()
loss.backward()
optimizer. Step()
输出结果如下所示,第一列表示第几轮,第二列表示这一轮第几个Batch,最后一列表示这一个Batch的平均误差。可以看到第二轮的时候,第4Batch的平均误差就明显下降了。



















 1607
1607

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









