




题目:Multi-body sensor based drowsiness detection using convolutional programmed transfer VGG-16 neural network with automatic driving mode conversion基于多体传感器的睡意检测,使用具有自动驾驶模式转换功能的卷积程序传输 VGG-16 神经网络
期刊:Scientific Reports
原文链接:Multi-body sensor based drowsiness detection using convolutional programmed transfer VGG-16 neural network with automatic driving mode conversion Meenakshi Malik1, Preeti Sharma
代码链接:GitHub - supreetldh2/Drowsiness(基于PyTorch库,相对简单)
摘要
如今,许多交通事故的发生都是由于驾驶员不够注意或警惕造成的。我们称之为驾驶员困倦。这导致了许多不利的情况,对人们的生活产生负面影响。识别驾驶员疲劳并适当处理此类信息是本研究的主要目标。ADAS(高级驾驶员辅助系统)中 AI(人工智能)和 ML(机器学习)的持续发展使得物联网 (IoT) 技术在驾驶员动作识别中的应用变得必要。这些进步正在极大地改变驾驶体验。这项研究提出了一种基于机器学习的自动驾驶基于变化的睡意检测的新方法。在这种情况下,多体传感器检测驾驶员的脑电信号并收集信息进行大脑活动分析。小波时频变换模型已用于检查该信号,以便对大脑活动的模式进行分类。然后使用多层卷积程序传输 VGG-16 神经网络对这种检查模式进行分类。这个分类信号会导致自动驾驶模式发生变化。在预测准确性、灵敏度、特异性、RMSE、ROC 方面,已经对各种脑电信号数据集进行了实验分析。这项工作的目标是降低疲劳驾驶带来的风险,这将提高道路安全并减少与疲劳相关的事故。
与现有研究之间的区别
目前的驾驶员睡意检测系统有许多缺点,例如误报率高、识别微睡眠的挑战、需要校准或个性化定制。此外,驾驶员可能会觉得某些设备很突兀或不舒服,环境条件可能会影响他们的成功程度。目前检测睡意的方法涉及复杂的程序和昂贵的机器,例如跟踪大脑活动的脑电图 (EEG)。某些技术采用 68 个面部点进行面部检测,将坐标存储在动态存储系统中。然而,由于所有坐标都是关联的,因此在画面中看不到整个面部的情况下,这些方法无法识别精确的目标区域。卷积神经网络 (CNN) 提供更高的准确性,但在某些情况下表现不佳,包括角度变化、昏暗的光线和透明眼镜。失败的主要原因是 CNN 的过程,因为它需要从三个不同的角度(0、+ 200 和 − 200)分析项目。角度问题在所有基于驱动程序的方法中都存在,因为它们都专注于提高隐藏层的数量,这会导致大量的数据丢失。
解决思路
1.🧐利用小波时频模型WTFT(wavelet time frequency transform)分析脑电图
小波变换(Wavelet Transform)是一种将信号分解为不同频率成分,并对每个成分在时间上进行局部化的数学工具。与傅里叶变换不同,小波变换能够在不同尺度(分辨率)上分析信号,适用于非平稳信号的分析。(具体知识背景见波的时频分析方法——小波变换详解_小波变换对地震波的分析-优快云博客)
WTFT 的非平稳特性使其成为生物信号(尤其是脑电图信号)时频分析的流行工具。
2.🧐利用基于多层卷积设计转移 VGG-16 神经网络 (MLCDTVGG-16) 进行脑信号分类
CNN 模型使用以下参数进行训练:学习率、动量、正则化。为了获得最佳性能,可以根据数据集调整这些参数。动量有助于数据收敛,而学习率调节网络在训练期间的学习速度。用试错法确定这些参数。三种不同的层类型构成了 CNN 架构:全连接层、池化层、卷积层。
- 卷积层:它由在 EEG 信号(脑电图)上移动的滤波器或内核组成。矩阵与输入 EEG 信号进行卷积称为内核,滤波器的步幅决定了它卷积的输入信号量。
- 池化层/下采样层:为了降低计算强度并避免过拟合,池化过程最小化了卷积层输出神经元的维度。通过仅从每个特征图中选择最大值,减少了输出神经元的总数。
- 全连接层:层中在连接到该层之前都会被激活。将输出映射到一组输入的作称为激活函数。
- 整流线性激活单元:增加非线性,对输入中的噪声等微小变化具有弹性。
- softmax:k 个输出类的概率分布由此函数计算。sigmoid函数作为最后一个激活层来获得二元分类结果。
VGG 架构采用微小的 3 × 3 个过滤器使特定网络更密集。结构简单,只需将层池化和一个完全链接的层作为额外组件即可。代码中卷积核大小参数为(3,3)体现了VGG框架的应用。
卷积核计算公式: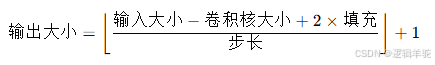

代码框架
先读取数据:load_physionet_data()、load_emotiv_data()、load_kaggle_data()分别从PhysioNet、Emotiv EPOC、Kaggle读取数据,返回数据及标签,并在主函数中将所有数据和标签合并成all_signals、all_labels。

然后用函数preprocess_data(signals)对EEG信号进行预处理以提取分类所需的特征
create_vgg16_model用于构建训练框架,框架采用Sequential模型结构,优化器为Adam,损失计算为binary_crossentropy(二元交叉熵),评价指标为准确率。Sequential模型是简单的线性结构的堆栈,是多个网络层的堆叠,这边主要添加了三层:
- 第一个卷积层有32个过滤器,每个过滤器的大小为3×3,激活函数为ReLU,最大池化层池化窗口为2×2,Dropout用于防止过拟合,置零25%神经元。
- 第二个卷积层基本和第一层一样,但是过滤器数量翻倍了。
- 第三层先用Flatten将多维输入一维化,再用Dense对输入进行加权求和,将前面的特征进行组合,第一层Dense包含128个神经元,使用Relu作为激活函数,然后置零50%神经元,最后使用一个sigmoid激活函数,做一个二分类输出。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









