




epoch、Batch-size 、iteration
首先,在训练模型的时候,数据会被分成很多批次来处理。这里的批次应该就是batch吧,而batch size应该是指每个批次里的样本数量。比如,如果我有1000个训练样本,设置batch size为100,那么每个batch就有100个样本。这样的话,全部数据过一遍需要10个batch,也就是10次迭代(iteration),这样每个epoch完成一次所有数据的训练。每个epoch代表整个数据集被训练一次,而iteration是完成一个batch的前向和后向传播的次数。那如果我的数据集有1000个样本,batch size是100,那么一个epoch会有10个iteration,对吗?这样的话,完成一个epoch需要10次iteration,也就是每次iteration处理一个batch的数据,直到处理完整个数据集。那如果训练过程中,比如进行了5个epoch,每个epoch有10个iteration,那么总共有50次iteration,这时候模型总共看了5次整个数据集的数据,每次分10个batch处理。
另外,batch size的大小会影响训练效果。大的batch size可能会让训练速度更快,因为每次处理的数据更多,但可能会占用更多的内存。而小的batch size虽然每次更新更频繁,但可能需要更多的iteration来完成一个epoch,也可能带来更好的泛化能力,因为参数更新的次数更多,引入的噪声更多,可能避免陷入局部极小值。
torchvision
torchvision是PyTorch的扩展库,用于计算机视觉任务。主要功能模块有:datasets模块,里面包含常用的数据集,像MNIST、CIFAR、ImageNet等,还有预训练的模型,比如ResNet、VGG等。然后transforms模块,用于数据预处理,常见的操作如调整大小、标准化、数据增强等。接着utils模块,用于将多个图像合成一张图,方便可视化等等
Tensorboard
TensorBoard 是 深度学习实验的可视化工具包,它通过将训练过程中的各种数据转化为直观的图表,帮助开发者更好地理解、调试和优化模型,可在模型训练时进行训练过程的监控。
SummaryWriter是 与 TensorBoard 交互的核心类,用于将训练过程中的各种数据(标量、图像、模型结构等)写入日志文件,供 TensorBoard 可视化。
writer.add_scalar(tag,scalar_value,global_step=None,walltime=None )是 PyTorch 中记录标量数据的核心方法,用于将训练过程中的关键指标(如损失、准确率等)实时写入 TensorBoard 日志。
| 参数 | 类型 | 作用 | 示例值 |
|---|---|---|---|
tag | string | 数据标识符(层级式命名推荐用 / 分隔) | 'Loss/Train' |
scalar_value | float | 要记录的标量值 | 0.23 |
global_step | int | 记录的步数/轮数(x轴坐标) | epoch |
walltime | float | 可选,覆盖默认的时间戳(Unix时间) |
time.time() |
from torch.utils.tensorboard import SummaryWriter #导入SummaryWriter类
import numpy as np
from PIL import Image
#创建写入器(日志保存到logs文件夹)
writer = SummaryWriter("logs")
image_path = "dataset/train/ants/0013035.jpg"
img_PIL = Image.open(image_path)
img_array = np.array(img_PIL)
writer.add_image("test",img_array,1,dataformats='HWC')
for i in range(100):
writer.add_scalar("y=2x",2*i,i) #终端即可打开,tensorboard --logdir=logs --port=6007
#关闭写入器
writer.close() # 确保所有数据写入磁盘
transforms
transforms就是一个工具箱,里面有工具(类),图片可通过这些工具进行变换,得到想要的结果
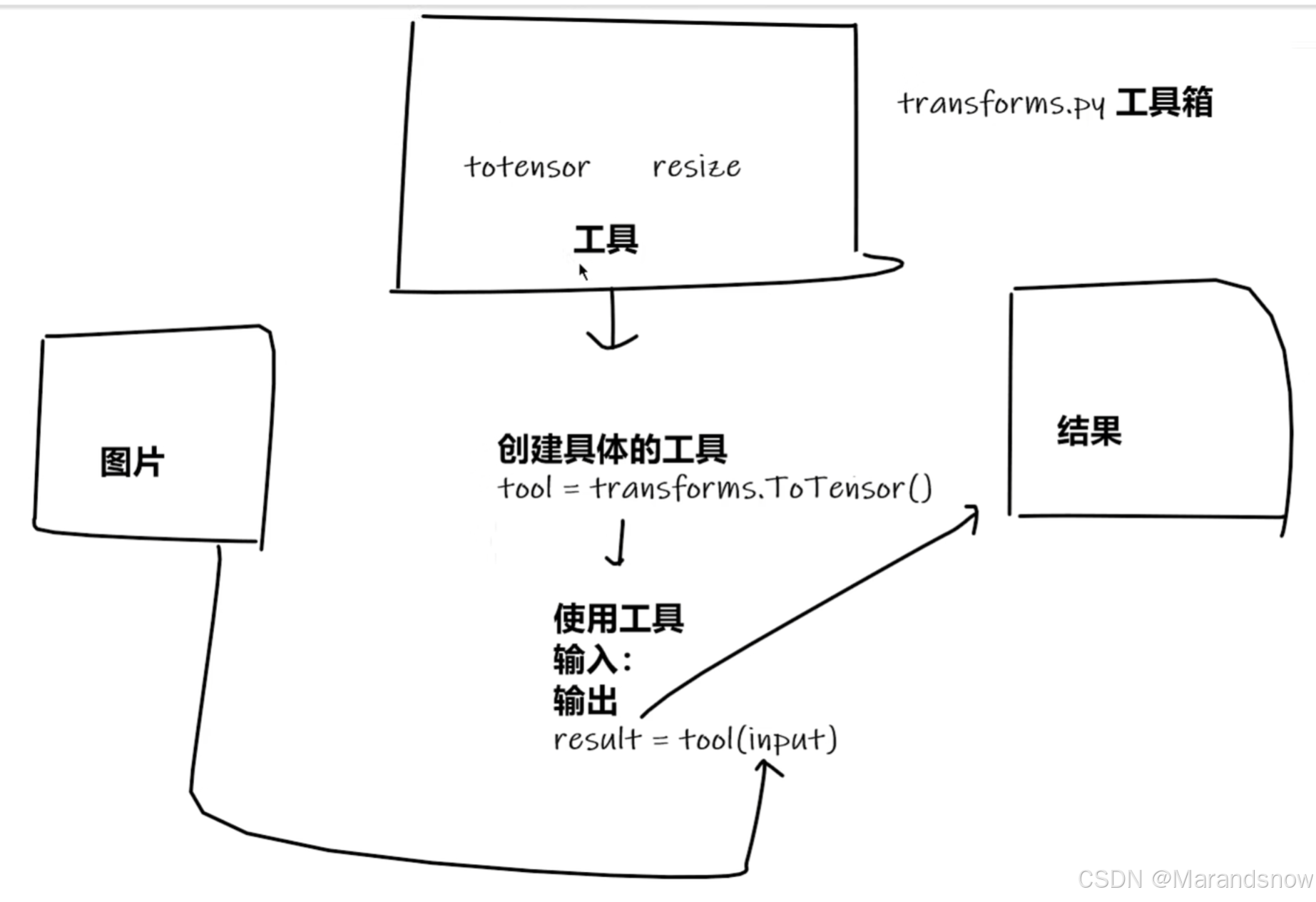
from PIL import Image
from torch.utils.tensorboard import SummaryWriter
from torchvision import transforms
writer = SummaryWriter("logs")
img_path = "dataset/train/ants/0013035.jpg"
img = Image.open(img_path)
print(img)
#ToTensor
trans_totensor = transforms.ToTensor()
img_tensor = trans_totensor(img)
writer.add_image("Tensor_img",img_tensor)
#Normalize 归一化
print(img_tensor[0][0][0])
trans_norm = transforms.Normalize([6,3,2],[9,3,5])
img_norm = trans_norm(img_tensor)
print(img_norm[0][0][0])
writer.add_image("Normalize",img_norm,2)
writer.close()
#终端即可打开,tensorboard --logdir=logs --port=6007
import torchvision
from torch.utils.tensorboard import SummaryWriter
dataset_new_transform = torchvision.transforms.Compose([
torchvision.transforms.ToPILImage()
])
train_set = torchvision.datasets.CIFAR10(root = "./dataset_new",train=True,transform=dataset_new_transform,download=True)
test_set = torchvision.datasets.CIFAR10(root = "./dataset_new",train=False,transform=dataset_new_transform,download=True)
# print(test_set[0])
# print(test_set.classes)
#
# img,target = test_set[0]
# print(img)
# print(target)
# print(test_set.classes[target])
# img.show()
#
# print(test_set[0])
writer = SummaryWriter("p10")
for i in range(10):
img, target = test_set[i]
writer.add_image("test_set",img,i)
writer.close()
Dataset、Dataloader
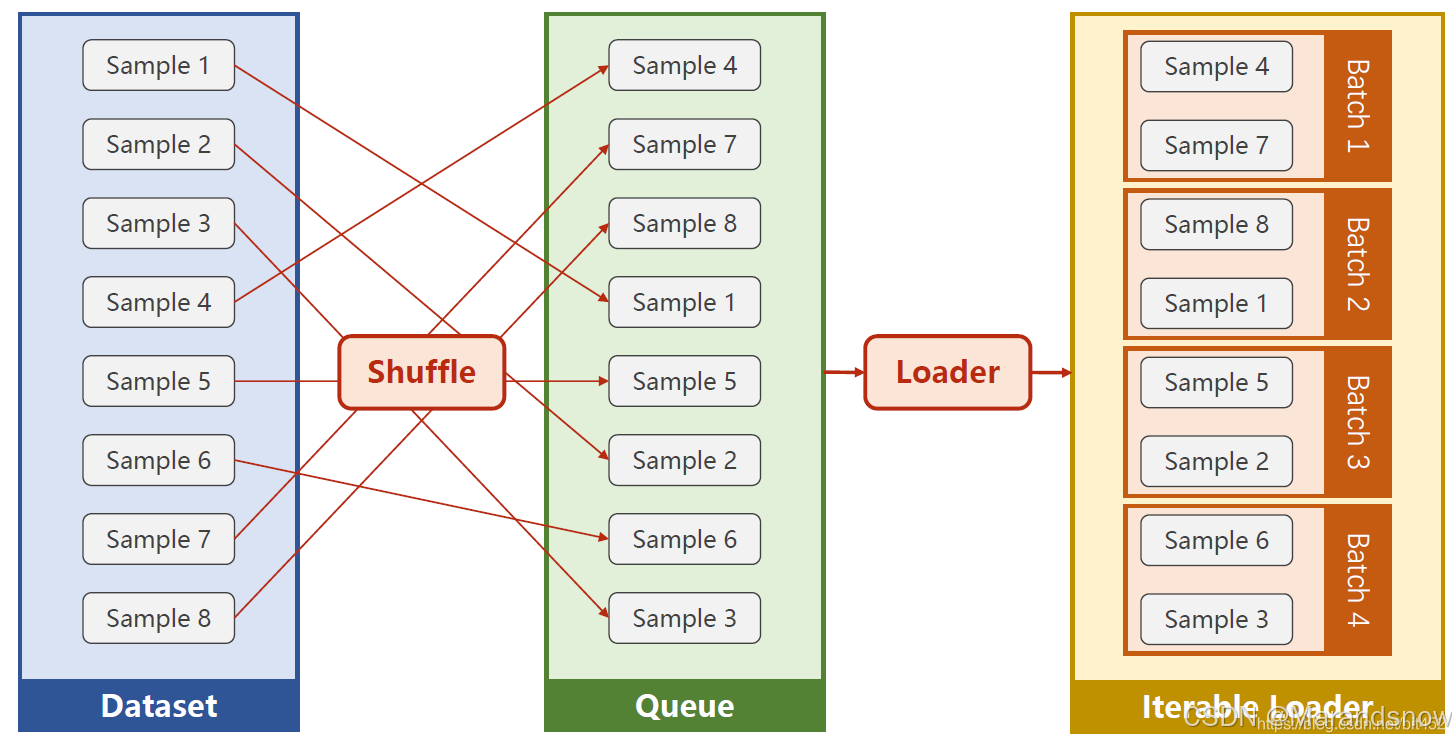
1. Dataset:数据容器
-
作用:存储样本数据和对应标签(类似字典,这样可以给每个数据都标上号,方便索引),提供统一的索引接口。Dataset是用来封装数据和标签的,用户需要继承这个类并实现__len__和__getitem__方法。继承Dataset的话,必须实现__getitem__和__len__这两个方法,否则在使用DataLoader的时候会出错。
-
实现方式:
-
继承
torch.utils.data.Dataset -
必须重写
__len__(返回数据集大小)和__getitem__(通过索引获取样本) -
Dataset 是一个抽象类,不能实例化对象,主要是用于构造我们的数据集。使用时必须进行重写,from 在torch.utils.data Dataset
#(1)重写时,需要根据数据来进行构造__init__(self,filepath)
#(2)__getitem__(self,index)用来让数据可以进行索引操作
#(3)__len__(self)用来获取数据集的大小from torch.utils.data import Dataset #导入Dataset类 from PIL import Image import os class MyData(Dataset): #继承Dataset类 def __init__(self,root_dir,label_dir): #初始化,为后面方法提供全局变量 self.root_dir = root_dir #数据集根目录(如"data/train") self.label_dir = label_dir #标签对应子目录名(如"ants或bees") self.path =os.path.join(self.root_dir,self.label_dir) #拼接完整路径(如"data/train/ants") self.img_path = os.listdir(self.path) #获取该类别下所有图片文件名列表 def __getitem__(self, index): img_name = self.img_path[index] #根据索引获取单个文件名 img_item_path =os.path.join(self.root_dir,self.label_dir,img_name) #拼接图片完整路径 img = Image.open(img_item_path) #用PIL读取图片 label = self.label_dir #直接使用子目录名作为标签(如"ants") return img,label #返回图像和标签 def __len__(self): return len(self.img_path) #返回该类别下的图片总数 self.root_dir = root_dir #数据集根目录(如"data/train") self.label_dir = label_dir #标签对应子目录名(如"ants或bees") self.path =os.path.join(self.root_dir,self.label_dir) #拼接完整路径(如"data/train/ants") self.img_path = os.listdir(self.path) #获取该类别下所有图片文件名列表 def __getitem__(self, index): img_name = self.img_path[index] #根据索引获取单个文件名 img_item_path =os.path.join(self.root_dir,self.label_dir,img_name) #拼接图片完整路径 img = Image.open(img_item_path) #用PIL读取图片 label = self.label_dir #直接使用子目录名作为标签(如"ants") return img,label #返回图像和标签 def __len__(self): return len(self.img_path) #返回该类别下的图片总数 root_dir = "dataset/train" ants_label_dir = "ants" bees_label_dir = "bees" ants_dataset = MyData(root_dir,ants_label_dir) bees_dataset = MyData(root_dir,ants_label_dir) img,label = ants_dataset[23] img.show()
-
2. DataLoader:数据加载器
-
作用:Dataloader负责把Dataset里的数据批量加载,可能还包含打乱顺序、多线程加载等功能。将Dataset包装为可迭代对象,支持:
-
批量加载(Batching):
batch_size -
乱序(Shuffling):
shuffle=True -
多进程加速:
num_workers -
内存优化:
pin_memory=True(GPU加速时)import torchvision from torch.utils.data import DataLoader from torch.utils.tensorboard import SummaryWriter #准备的测试数据集 test_data = torchvision.datasets.CIFAR10("./dataset_new",train = False,transform=torchvision.transforms.ToTensor()) test_loader = DataLoader(dataset=test_data,batch_size=4,shuffle=True,num_workers=0,drop_last=False) #测试数据集中第一张图片及target img,target = test_data[0] print(img.shape) print(target) writer = SummaryWriter("dataloader") for epoch in range(2): step = 0 for data in test_loader: imgs,targets = data print(imgs.shape) print(targets) writer.add_images("Epoch:{}".format(epoch),imgs,step) step = step + 1 writer.close()
-
总结
Dataset负责数据存储和单样本处理,Dataloader负责批量处理和迭代。简单来说,Dataset 负责告诉 PyTorch 数据在哪里、数据是什么,而 DataLoader 负责将这些数据打包成适合训练和测试的批次,并按需喂给模型。
import torch
import numpy as np
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
#DataLoader 用来加载数据为mini-Batch ,支持Batch-size 的设置,shuffle支持数据的打乱顺序,#DataLoader 需要获取DataSet提供的索引[i]和len;用来帮助我们加载数据,比如说做shuffle(提高数据集#的随机性),batch_size,能拿出Mini-Batch进行训练。它帮我们自动完成这些工作。DataLoader可实例化对#象。
# prepare dataset
class DiabetesDataset(Dataset):
def __init__(self, filepath):
xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32)
self.len = xy.shape[0] # shape(多少行,多少列)
self.x_data = torch.from_numpy(xy[:, :-1])
self.y_data = torch.from_numpy(xy[:, [-1]])
def __getitem__(self, index):
return self.x_data[index], self.y_data[index]
def __len__(self):
return self.len
dataset = DiabetesDataset('diabetes.csv')
train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=0) #num_workers 多线程
# design model using class
class Model(torch.nn.Module):
def __init__(self):
super(Model, self).__init__()
self.linear1 = torch.nn.Linear(8, 6)
self.linear2 = torch.nn.Linear(6, 4)
self.linear3 = torch.nn.Linear(4, 1)
self.sigmoid = torch.nn.Sigmoid()
def forward(self, x):
x = self.sigmoid(self.linear1(x))
x = self.sigmoid(self.linear2(x))
x = self.sigmoid(self.linear3(x))
return x
model = Model()
# construct loss and optimizer
criterion = torch.nn.BCELoss(reduction='mean')
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# training cycle forward, backward, update
if __name__ == '__main__':
for epoch in range(100):
for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch
inputs, labels = data
y_pred = model(inputs)
loss = criterion(y_pred, labels)
print(epoch, i, loss.item())
optimizer.zero_grad()
loss.backward()
optimizer.step()

















 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









