








目录
大模型中的常用推理优化技术,详细介绍下低比特量化,分布式优化,算子优化,访存优化,服务并发优化,lookahead decoding,投机采样,美杜莎头等。下面分别对这些常用的大模型推理优化技术进行介绍。
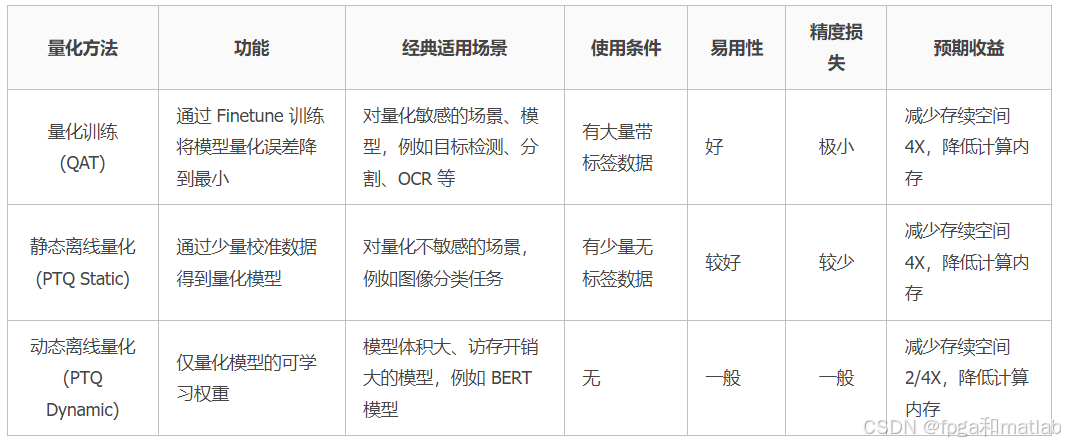
1.低比特量化
部署网络模型时,我们希望网络越小越好,来降低部署成本,于是就需要模型量化等压缩手段。低比特量化是一种通过减少模型参数和中间激活值的表示比特数来优化推理的技术。将模型参数从fp32/fp16压缩到更低的比特位宽表达,在不影响模型输出准确性和参数量的情况下,降低模型体积,从而减少缓存对于数据读写的压力,实现空间节省与推理加速,为模型优化与性能提升提供有力支持。通过降低模型权重和中间层变量的表示精度目前模型量化方法可以分为以下三种:
1.1 QAT
训练时量化(QAT)虽需模型重新训练,但其效果通常更佳。尽管成本较高,但因其卓越表现,QAT在微调(fintune)阶段应用广泛。通过精确调整模型参数,QAT确保量化后的模型性能损失最小化,满足高效部署需求。其结构如下图所示:

1.2 PTQ
训练后量化(PTQ)高效量化预训练模型,无需重新训练。该技术针对模型权重与激活值实施INT8/INT4量化,轻松提升模型部署效率,降低存储与计算成本,为AI应用加速提供强大支持。
PTQ可以分为静态和动态两种。其结构如下图所示:


因此针对大模型的量化技术往往只会针对关键的权重参数进行量化 (WeightOnly),而不对输入数据进行量化,在到达理想的压缩比的同时,尽可能保证输出结果,实现最高的量化性能。
1.3 量化方法对比
一般来讲,QAT精度较高,但需要较多的量化训练时间,成本较高。PTQ的量化效率较高,只需要少量数据集来校准,但量化精度损失较大。
2.分布式优化
在大规模深度学习模型的推理过程中,分布式计算是应对计算资源和内存限制的有效手段。然而,通信开销往往成为性能瓶颈。因此,通信层面的优化至关重要,其目标是在多个计算节点之间高效地传输数据和梯度,以最小化通信延迟和带宽消耗。
分布式训练的核心在于将大规模的数据集和计算任务分散到多个计算节点上,每个节点负责处理一部分数据和模型参数,通过高效的通信机制实现节点间的数据交换和参数同步。这种并行化的处理方式能够显著缩短训练时间,提升模型训练效率。
分布式优化,可以分为数据并行分布式优化和模型分布式优化。
2.1 数据并行分布式

2.2 模型分布式优化
当模型规模过大,单个计算设备无法存储整个模型时,采用模型并行。将模型的不同层或者同一层的不同部分划分到不同的计算节点。例如,对于一个深度神经网络,将前半部分层放在节点A,后半部分层放在节点B。在推理过程中,数据从节点A的输入层开始前向传播,经过节点A处理后,将中间结果传递给节点B继续处理。
3.算子优化
在 GPU 上进行深度学习计算时,CUDA 算子(如卷积、矩阵乘法等)的计算效率直接影响模型的推理速度。算子优化旨在通过改进算子的实现算法和利用 GPU 的硬件特性,最大限度地提高计算效率。
3.1卷积算子优化之Im2col + GEMM

3.2 卷积算子优化之Winograd 卷积算法

3.3 矩阵乘法算子优化

4.访存优化
GPU的高带宽内存(HBM)访问速度相对较慢,频繁访问 HBM 会成为性能瓶颈。访存优化的目标是通过合理的数据布局和访问策略,减少对 HBM 的访问次数,提高显存利用率,从而加速模型推理。
5.服务并发优化
服务并发优化主要考虑的是系统同时为多个用户服务时如何尽可能地提升资源利用率。Continuous Batching和Dynamic Batching主要围绕提高可并发的Batchsize来提高吞吐量,异步Tokenize/Detokenize则通过多线程方式将Tokenize/Detokenize执行与模型推理过程时间交叠,从而实现降低时延目的。
Continuous Batching可以将传统batch粒度的任务调度细化为step级别的调度,这解决了不同长短序列无法合并到同一个batch的问题,大幅提升推理效率和用户体验,目前已在HuggingFace TGI、vLLM、TensorRT-LLM等多个推理框架中实现。
6.lookahead decoding
Lookahead Decoding 是一种在序列生成任务(如机器翻译、文本生成等)中优化解码过程的技术。在传统的自回归解码中,生成每个单词只考虑之前已经生成的单词。
在训练过程中,对模型进行特殊的训练,使它能够学习利用未来信息来调整当前生成的概率。或者在推理过程中,通过缓存未来单词的概率分布或者生成候选序列来利用未来信息,从而提高生成的准确性和连贯性。
7.投机采样
在生成式模型(如语言模型)的推理过程中,传统的采样方法可能会比较耗时,尤其是在生成较长序列时。投机采样的目标是通过预测可能的生成路径,提前进行采样和验证,从而加速生成过程。
投机采样作为一种独特的方法,能够从根源上对计算访存比进行解码,并且确保与原始模型的采样分布毫无二致。在这一方法中,涉及到两个关键模型:一个是原始的目标模型,另一个则是相较于原始模型规模小很多的近似模型。
投机采样和正常的采样,其差别如下图所示:
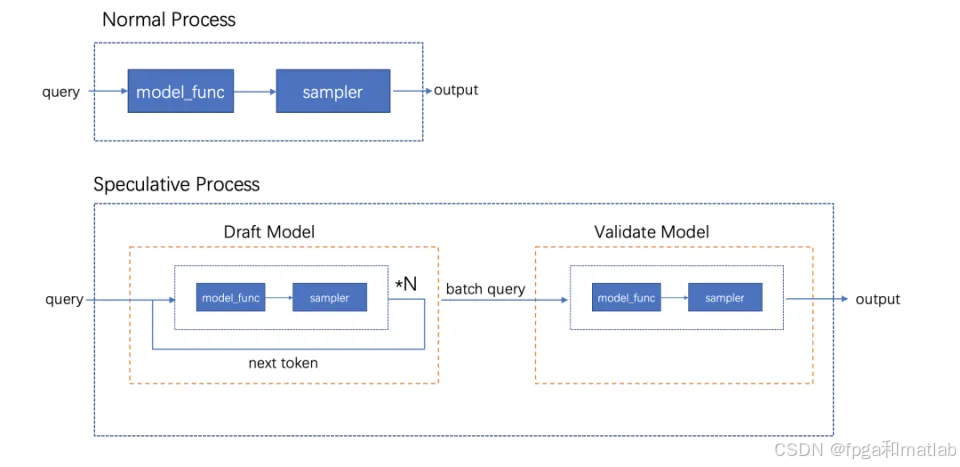
在实际操作中,近似模型主要承担自回归串行采样的任务,而大型的原始模型则负责对采样结果进行评估。在解码进程里,不同 token 的解码难度存在显著差异,有些 token 的解码较为轻松,而有些则极具挑战性。鉴于此,对于那些简单的 token 生成工作,可以放心地交由小型模型来完成,而复杂困难的 token 生成则由大型模型负责处理。
这里所提到的小型模型,其结构既可以与原始模型保持一致,只是在参数数量上有所精简,也可以直接采用 n - gram 模型。小型模型的优势不仅仅体现在计算量的大幅降低上,更为关键的是,它极大地减少了对内存访问的依赖,从而有效提升了整体的处理效率。
8.美杜莎头
在大型语言模型的运行逻辑中,随着模型规模的增加,语言生成的质量虽然会提升,但推理延迟也会显著增加。这主要是因为LLM推理主要受内存限制,主要延迟瓶颈源于加速器的内存带宽而非算术计算。具体来说,每次前向传递都需要将完整的模型参数从高带宽内存传输到加速器缓存,而该过程仅生成了单个token,没有充分利用现代加速器的算术计算潜力。
美杜莎头结构通过多头生成机制来实现这些目标,能够同时生成多个部分的序列,优化生成过程。美杜莎的整体流程如下图 1 所示。
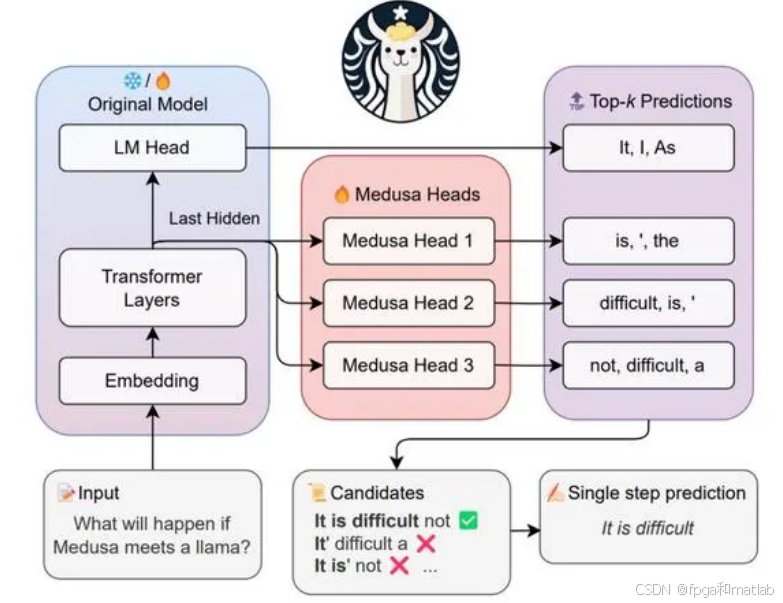
其中每个解码步骤主要由三个子步骤组成:(1) 生成候选者,(2) 处理候选者, (3) 接受候选者。对于 MEDUSA,(1) 是通过 MEDUSA 头(head)实现的,(2) 是通过树注意力(tree attention)实现的,并且由于 MEDUSA 头位于原始主干模型之上,因此 (2) 中计算的 logits 可以用于子步骤 (1) 的下一个解码步骤。最后一步 (3) 可以通过拒绝采样(rejection sampling)或典型接受(typical acceptance)来实现。
每个头可以专注于生成目标序列的不同部分或者具有不同的生成策略。例如,一个头可以侧重于生成高频词汇,另一个头可以侧重于生成低频但语义重要的词汇。这种结构可以提高生成的多样性和效率,尤其是在生成长序列时,可以并行地利用多个头进行生成,减少生成时间。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











