




Finite Element Method (FEM, 有限元方法) 时一种将物体看作许多有体积的微小单元来进行仿真的方法。比如将二维图形拆分成若干三角形,将三维体拆分成若干四面体。这种方法能够很好的模拟弹性体的形变等特点,能够在数学上证明其仿真方法一定收敛到解析解,比MPM等使用粒子模拟的方法更加准确,但同时也更加复杂,运算更慢。
本文将先从弹性体相关的物理量基础定义开始,再讲述各种弹性体的能量函数模型,最后阐述如何用有限元方法离散化进行仿真。
本文主要参考FEM simulation of 3D deformable solids Siggraph 2012 Course,并修正了一些不明确的可能错误的地方
弹性体基础
弹性体指的是能够自己恢复初始状态的材料
超弹性体(hyperelasticity)是一种特殊的弹性体,指的是弹力与压缩(拉伸)的路径没有关系,只与压缩后的状态有关系。
本文只考虑超弹性体。
形变与能量
定义弹性体的区域为 Ω \Omega Ω,弹性体上初始时每个点的位置为 X X X。弹性体发生平移、形变等变化后,弹性体上每一个点都将移动到另一个位置 x \textbf{x} x,可以用一个形变映射(deformation map)来表示弹性体的这一个变换 x = ϕ ( X ) \textbf{x} = \phi (X) x=ϕ(X),如下图
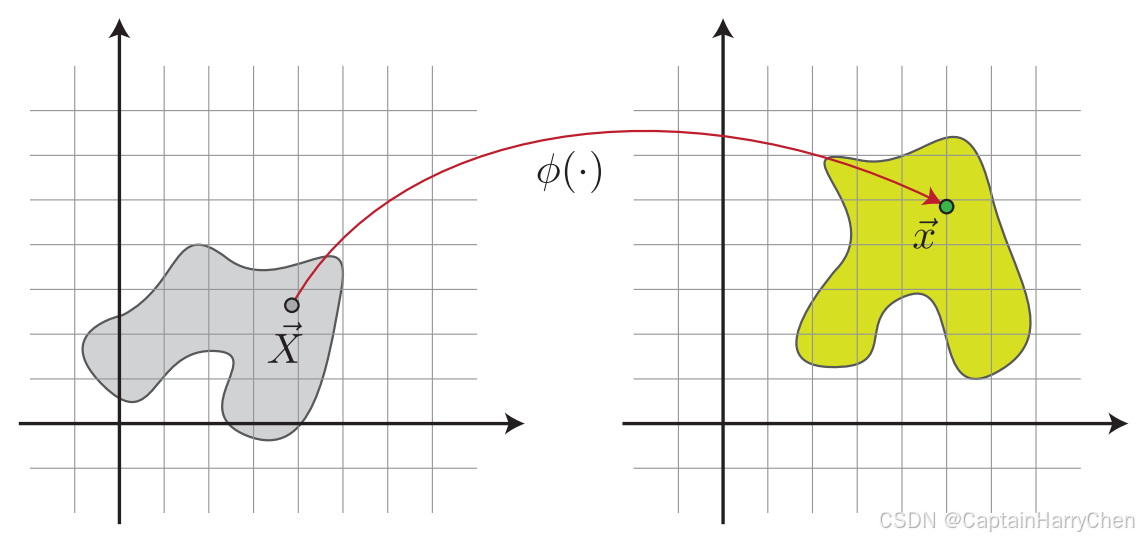
ϕ
(
X
)
\phi(X)
ϕ(X)并不能表示形变,因为弹性体整体的移动不产生形变,而相近的点移动的区别产生形变,则可以使用形变映射函数到初始位置的导数作为表示形变的量:
F
=
∂
ϕ
(
X
)
∂
X
=
∂
x
∂
X
F = \frac {\partial \phi (X)} {\partial X} = \frac {\partial \textbf{x}} {\partial X}
F=∂X∂ϕ(X)=∂X∂x
在三维情况下,这是一个3×3的矩阵,即雅可比矩阵,
F
F
F被称为形变梯度(deformation gradient)
F F F形变梯度表示某一点 X X X相对其邻域的形变,形变产生弹性势能,所以需要定义针对这一点的能量密度 Ψ ( ϕ , X ) \Psi(\phi, X) Ψ(ϕ,X),弹性体的总能量即为 E ( ϕ ) = ∫ Ω Ψ ( ϕ , X ) d X E(\phi) = \int_{\Omega} \Psi(\phi, X) \mathrm{d} X E(ϕ)=∫ΩΨ(ϕ,X)dX. 一般情况下,能量密度只与形变梯度有关,可写为 Φ ( F ) \Phi(F) Φ(F).
注意到 det ( F ) = J = V 变换后 V 初始 \text{det}(F) = J = \frac {V_{变换后}} {V_{初始}} det(F)=J=V初始V变换后,即 F F F的行列式可以表示体积的变化
弹性内力
接下来计算弹性内力,在数学上需要区分内部力和边界力
对于体积内部,令 f ( X ) f(X) f(X)表示位置 X X X处的力密度(单位 N / m 3 N/m^3 N/m3),则一个体积 A ⊂ Ω A \sub \Omega A⊂Ω内的受力为 f a g g ( A ) = ∫ A f ( X ) d X \textbf{f}_{agg}(A) = \int_A f(X) \mathrm{d}X fagg(A)=∫Af(X)dX
对于边界上,令 τ ( X ) \tau(X) τ(X)表示边界位置 X X X处的力密度(单位 N / m 2 N/m^2 N/m2),则一块三维体表面 B ⊂ ∂ Ω B \sub \partial \Omega B⊂∂Ω的受力为 f a g g ( B ) = ∮ B τ ( X ) d X \textbf{f}_{agg}(B) = \oint_B \tau(X) \mathrm{d}X fagg(B)=∮Bτ(X)dX
内力即为弹性势能梯度的相反方向,因为内力总是往使得势能减小最快的方向进行,所以内力可以为 f = − ∂ E ∂ x \textbf{f} = - \frac {\partial E} {\partial \textbf{x}} f=−∂x∂E,注意这里是变换后的位置
PK1数
因为内力是势能的梯度相反方向,所以我们试图用总势能对位置求梯度,看看能得到什么
δ
E
=
δ
[
∫
Ω
Ψ
(
F
)
d
X
]
=
∫
Ω
δ
[
Ψ
(
F
)
]
d
X
=
∫
Ω
[
∂
Ψ
∂
F
:
δ
F
]
d
X
\begin{align} \delta E & = \delta \left[ \int_\Omega \Psi(F) \mathrm{d}X \right] \\ & = \int_\Omega \delta \left[ \Psi(F) \right] \mathrm{d}X \\ & = \int_\Omega \left[ \frac {\partial \Psi} {\partial F} : \delta F\right] \mathrm{d}X \end{align}
δE=δ[∫ΩΨ(F)dX]=∫Ωδ[Ψ(F)]dX=∫Ω[∂F∂Ψ:δF]dX
注意公式中的 [ A : B ] \left[A : B\right ] [A:B]表示矩阵 A , B A, B A,B按位点乘,上述公式是微分链式法则用到了点乘
之后 [ : ] [ : ] [:]均表示按位点乘,有时候还需要按位点乘后再将每个元素加起来,请根据上下文判断
令 P = ∂ Ψ ∂ F P = \frac {\partial \Psi} {\partial F} P=∂F∂Ψ,被称为PK1数(The first Piola-Kirchhoff stress tensor),下面将推导 P P P的几何意义
继续推导能量的微分:
δ
E
=
∫
Ω
[
P
:
δ
F
]
d
X
=
∫
Ω
[
P
:
∂
∂
X
δ
ϕ
(
X
)
]
d
X
\begin{align} \delta E & = \int_\Omega \left[ P : \delta F\right] \mathrm{d}X \\ & = \int_\Omega \left[ P : \frac {\partial} {\partial X} \delta \phi(X) \right] \mathrm{d}X \\ \end{align}
δE=∫Ω[P:δF]dX=∫Ω[P:∂X∂δϕ(X)]dX
由高维分步积分拆开可以得到:
δ
E
=
−
∫
Ω
div
P
⋅
δ
x
⋅
d
X
+
∮
Ω
P
⋅
δ
x
⋅
d
S
=
−
∫
Ω
div
P
⋅
δ
x
⋅
d
X
+
∮
Ω
(
P
⋅
N
)
⋅
δ
x
⋅
d
X
\begin{align} \delta E & = -\int_\Omega \textbf{div} P \cdot \delta \textbf{x}\cdot \mathrm{d}X + \oint_\Omega P \cdot \delta \textbf{x} \cdot \mathrm{d}S \\ & = -\int_\Omega \textbf{div} P \cdot \delta \textbf{x}\cdot \mathrm{d}X + \oint_\Omega (P \cdot N) \cdot \delta \textbf{x} \cdot \mathrm{d}X \\ \end{align}
δE=−∫ΩdivP⋅δx⋅dX+∮ΩP⋅δx⋅dS=−∫ΩdivP⋅δx⋅dX+∮Ω(P⋅N)⋅δx⋅dX
因为出现了对于当前位置
x
\textbf{x}
x的微分
δ
x
\delta \textbf{x}
δx,根据力的定义,可以把积分前半部分视为力密度
即 f ( x ) = div P f(\textbf{x}) = \textbf{div} P f(x)=divP, τ ( x ) = − P ⋅ N \tau(\textbf{x}) = - P\cdot N τ(x)=−P⋅N
可以理解为PK1数表示的是对该点某一方向微平面的压强
弹性能量模型
本节将探讨不同的弹性模型如何从形变梯度定义能量密度,计算出内力
应变量度
为了计算出能量,我们需要一个衡量形变程度的度量方式, F F F只是一个表示形变的量,并不能衡量形变程度。
注意到形变梯度
F
F
F实际上仅包含变换的旋转和拉伸,矩阵一定可以分解为
F
=
R
S
F=RS
F=RS,其中
R
R
R为旋转矩阵,满足
R
T
R
=
I
R^T R=I
RTR=I;
S
S
S为拉伸矩阵,一定为对称的。形变的量度可以仅与拉伸有关:
E
=
1
2
(
S
2
−
I
)
=
1
2
(
F
T
F
−
I
)
E=\frac 1 2 (S^2-I) = \frac 1 2 (F^T F - I)
E=21(S2−I)=21(FTF−I)
注意这里的
E
E
E不是能量,这被称为格林应变张量(Green strain tensor),是一个3×3的矩阵,用于衡量各个方向的形变程度。这是一个与旋转、平移无关的量度,但它是非线性的。
尝试简化,我们对
E
E
E在
F
=
I
F=I
F=I进行泰勒展开:
E
(
F
)
≈
E
(
I
)
+
∂
E
∂
F
∣
F
=
I
:
(
F
−
I
)
=
E
(
I
)
+
1
2
[
(
F
−
I
)
T
I
+
I
T
(
F
−
I
)
]
=
1
2
(
F
+
F
T
)
−
I
\begin{align} E(F) & ≈ E(I) + \frac {\partial E} {\partial F}\bigg |_{F=I} : (F-I) \\ & = E(I) +\frac 1 2 \left[ (F-I)^T I + I^T (F-I) \right] \\ & = \frac 1 2 (F+F^T) - I \end{align}
E(F)≈E(I)+∂F∂E
F=I:(F−I)=E(I)+21[(F−I)TI+IT(F−I)]=21(F+FT)−I
其中第一行到第二行的求法是使用微分
∂
E
∂
F
:
δ
F
=
δ
E
=
1
2
(
δ
F
T
F
+
F
T
δ
F
)
\frac {\partial E} {\partial F} : \delta F = \delta E = \frac 1 2 (\delta F^T F + F^T \delta F)
∂F∂E:δF=δE=21(δFTF+FTδF)
我们由此定义了另一个量度:
ϵ
=
1
2
(
F
+
F
T
)
−
I
\epsilon = \frac 1 2 (F+F^T) - I
ϵ=21(F+FT)−I
称为微小应变张量(small strain tensor, infinitesimal strain tensor),是一个线性的应变张量,但其却是与旋转有关的,弹性体在不形变的情况下发生旋转也会改变
ϵ
\epsilon
ϵ
注意到 ϵ \epsilon ϵ一定为对称矩阵,其点乘一个反对称矩阵一定为 0 \textbf{0} 0
线性弹性模型 Linear elasticity
定义:
Ψ
(
F
)
=
μ
tr
(
ϵ
2
)
+
λ
2
tr
2
(
ϵ
)
\Psi(F) = \mu \text{tr}(\epsilon^2) + \frac \lambda 2 \text{tr}^2(\epsilon)
Ψ(F)=μtr(ϵ2)+2λtr2(ϵ)
这是线性弹性模型的能量密度,其中
μ
=
k
2
(
1
+
ν
)
\mu = \frac {k} {2(1+\nu)}
μ=2(1+ν)k,
λ
=
k
ν
(
1
+
ν
)
(
1
−
2
ν
)
\lambda = \frac {k \nu} {(1 + \nu) ( 1-2 \nu)}
λ=(1+ν)(1−2ν)kν被称为拉梅系数 (Lamé coefficients) 。其中的
k
k
k为杨氏模量 (Young’s modulus) ,一般表示拉伸抵抗性。
ν
\nu
ν为泊松比,一般表示不可压缩性。
通过对
Ψ
\Psi
Ψ微分来求
P
P
P
δ
Ψ
=
μ
⋅
tr
(
δ
ϵ
⋅
ϵ
+
ϵ
δ
ϵ
)
+
λ
tr
(
ϵ
)
tr
(
δ
ϵ
)
δ
ϵ
=
1
2
(
δ
F
+
δ
F
T
)
≐
Sym
(
δ
F
)
\begin{align} \delta \Psi & = \mu \cdot \text{tr}(\delta \epsilon \cdot \epsilon +\epsilon \delta \epsilon) + \lambda \text{tr}(\epsilon ) \text{tr}(\delta \epsilon) \\ \delta \epsilon & = \frac 1 2 \left( \delta F + \delta F^T \right) \doteq \text{Sym}(\delta F) \ \end{align}
δΨδϵ=μ⋅tr(δϵ⋅ϵ+ϵδϵ)+λtr(ϵ)tr(δϵ)=21(δF+δFT)≐Sym(δF)
注:任意矩阵都可以拆分为一个对称矩阵和反对称矩阵之和 A = Sym ( A ) + Anti-Sym ( A ) A = \text{Sym}(A) + \text{Anti-Sym}(A) A=Sym(A)+Anti-Sym(A)
对称矩阵点乘一个矩阵: ϵ : A = ϵ : Sym ( A ) \epsilon : A = \epsilon : \text{Sym}(A) ϵ:A=ϵ:Sym(A)
注2:矩阵的迹中两矩阵相乘是可以交换的: tr ( A B ) = tr ( B A ) \text{tr}(AB) = \text{tr}(BA) tr(AB)=tr(BA),可以展开对角线元素计算证明。还可以是可转置的 tr ( A ) = tr ( A T ) \text{tr} (A) = \text{tr} (A^T) tr(A)=tr(AT)
注3:矩阵的迹的微分可以视为矩阵对角元素的微分,其余为0,则可以写为 δ tr ( ϵ ) = tr ( δ ϵ ) = I : δ ϵ \delta \text{tr}(\epsilon) = \text{tr}(\delta \epsilon) = I : \delta \epsilon δtr(ϵ)=tr(δϵ)=I:δϵ
δ Ψ = 2 μ ⋅ tr ( δ ϵ ⋅ ϵ ) + λ tr ( ϵ ) ( I : Sym ( δ F ) ) = 2 μ ⋅ ( I : Sym ( δ F ) ϵ ) + λ tr ( ϵ ) ( I : Sym ( δ F ) ) = 2 μ ⋅ ( ϵ : Sym ( δ F ) T ) + λ tr ( ϵ ) ( I : Sym ( δ F ) ) = ( 2 μ ϵ + λ tr ( ϵ ) I ) : Sym ( δ F ) = ( 2 μ ϵ + λ tr ( ϵ ) I ) : δ F ⇒ P = 2 μ ϵ + λ tr ( ϵ ) I = μ ( F + F T − 2 I ) + λ tr ( F − I ) I \begin{align} \delta \Psi & = 2\mu \cdot \text{tr}(\delta \epsilon \cdot \epsilon ) + \lambda \text{tr} (\epsilon) \left( I : \text{Sym}(\delta F) \right) \\ & = 2\mu \cdot (I : \text{Sym}(\delta F)\epsilon) + \lambda \text{tr} (\epsilon) \left( I : \text{Sym}(\delta F) \right) \\ & = 2\mu \cdot (\epsilon : \text{Sym}(\delta F)^T) + \lambda \text{tr} (\epsilon) \left( I : \text{Sym}(\delta F) \right) \\ & = (2\mu \epsilon + \lambda \text{tr} (\epsilon) I) : \text{Sym}(\delta F) \\ & = (2\mu \epsilon + \lambda \text{tr} (\epsilon) I) : \delta F \\ \Rightarrow P & = 2\mu \epsilon + \lambda \text{tr} (\epsilon) I \\ & = \mu (F + F^T - 2I) + \lambda \text{tr} (F - I) I \end{align} δΨ⇒P=2μ⋅tr(δϵ⋅ϵ)+λtr(ϵ)(I:Sym(δF))=2μ⋅(I:Sym(δF)ϵ)+λtr(ϵ)(I:Sym(δF))=2μ⋅(ϵ:Sym(δF)T)+λtr(ϵ)(I:Sym(δF))=(2μϵ+λtr(ϵ)I):Sym(δF)=(2μϵ+λtr(ϵ)I):δF=2μϵ+λtr(ϵ)I=μ(F+FT−2I)+λtr(F−I)I
我们得出了线性弹性模型的PK1数: P = μ ( F + F T − 2 I ) + λ tr ( F − I ) I P = \mu (F + F^T - 2I) + \lambda \text{tr} (F - I) I P=μ(F+FT−2I)+λtr(F−I)I
这个模型是线性的,容易计算,但是其与旋转相关
圣维南-基尔霍夫模型 St. Venant-Kirchhoff model (STVK)
使用格林应变张量(
E
=
1
2
(
F
T
F
−
I
)
E = \frac 1 2 (F^T F - I)
E=21(FTF−I))定义的非线性模型:(注意到
E
E
E为对称矩阵)
Ψ
(
F
)
=
μ
tr
(
E
2
)
+
λ
2
tr
2
(
E
)
\Psi (F) = \mu \text{tr}(E^2) + \frac \lambda 2 \text{tr}^2(E)
Ψ(F)=μtr(E2)+2λtr2(E)
同样,对其微分来求
P
P
P:
δ
Ψ
(
F
)
=
2
μ
⋅
tr
(
E
δ
E
)
+
λ
tr
(
E
)
tr
(
δ
E
)
δ
E
=
1
2
(
δ
F
T
F
+
F
T
δ
F
)
=
Sym
(
F
T
δ
F
)
tr
(
E
δ
E
)
=
I
:
E
⋅
Sym
(
F
T
δ
F
)
=
E
:
Sym
(
F
T
δ
F
)
T
=
E
:
F
T
δ
F
=
F
E
:
δ
F
tr
(
δ
E
)
=
I
:
Sym
(
F
T
δ
F
)
=
I
:
F
T
δ
F
=
F
:
δ
F
⇒
δ
Ψ
(
F
)
=
2
μ
F
E
:
δ
F
+
λ
tr
(
E
)
F
:
δ
F
=
(
2
μ
F
E
+
λ
tr
(
E
)
F
)
:
δ
F
⇒
P
=
2
μ
F
E
+
λ
tr
(
E
)
F
=
F
(
2
μ
E
+
λ
tr
(
E
)
I
)
\begin{align} \delta \Psi (F) & = 2\mu \cdot \text{tr} (E\delta E) + \lambda \text{tr}(E) \text{tr}(\delta E) \\ \delta E & = \frac 1 2 (\delta F^TF + F^T \delta F) = \text{Sym}(F^T \delta F) \\ \text{tr} (E\delta E) & = I: E\cdot \text{Sym} (F^T \delta F) = E : \text{Sym} (F^T \delta F)^T = E: F^T \delta F = FE : \delta F \\ \text{tr} (\delta E) & = I: \text{Sym}(F^T \delta F) = I:F^T \delta F = F : \delta F \\ \Rightarrow \delta \Psi(F) & = 2 \mu FE : \delta F + \lambda \text{tr}(E) F:\delta F \\ & = (2\mu FE + \lambda \text{tr}(E) F):\delta F \\ \Rightarrow P &= 2\mu FE + \lambda \text{tr} (E) F = F(2 \mu E + \lambda \text{tr}(E) I) \end{align}
δΨ(F)δEtr(EδE)tr(δE)⇒δΨ(F)⇒P=2μ⋅tr(EδE)+λtr(E)tr(δE)=21(δFTF+FTδF)=Sym(FTδF)=I:E⋅Sym(FTδF)=E:Sym(FTδF)T=E:FTδF=FE:δF=I:Sym(FTδF)=I:FTδF=F:δF=2μFE:δF+λtr(E)F:δF=(2μFE+λtr(E)F):δF=2μFE+λtr(E)F=F(2μE+λtr(E)I)
注:上面第三行用了性质 A : B T C = B A : C A : B^T C = BA : C A:BTC=BA:C,可以通过展开点乘和矩阵乘法证明
注2:点乘易错点 A ( B : C ) ≠ ( A B ) : C A(B:C) \neq (AB) : C A(B:C)=(AB):C
于是我们得到了StVK模型的PK1数: P = F ( 2 μ E + λ tr ( E ) I ) P = F(2 \mu E + \lambda \text{tr}(E) I) P=F(2μE+λtr(E)I)
这其实是一个关于 F F F的三次式,十分复杂,运算复杂度高,优势在于他是一个旋转无关的模型,更符合现实。其仍有仿真缺陷,当弹性体被压缩到一定程度后,其抵抗压缩的力会突然减小(?),导致弹性体更容易被压缩到一个质点
共旋转线性模型 (Corotated Linear Elasticity)
线性模型没有旋转无关性,StVK效率很低,于是Corotated Linear Elasticity试图折衷考虑两者。
比较复杂,不细讲
Ψ
(
F
)
=
μ
∥
S
−
I
∥
F
2
+
λ
2
tr
2
(
S
−
I
)
\Psi (F) = \mu \| S - I \| ^2_F +\frac \lambda 2 \text{tr}^2(S-I)
Ψ(F)=μ∥S−I∥F2+2λtr2(S−I)
其中
S
S
S为包含在
F
F
F中的拉伸矩阵
F
=
R
S
F = RS
F=RS
P
=
2
μ
(
F
−
R
)
+
λ
tr
(
R
T
F
−
I
)
R
P = 2 \mu (F - R) + \lambda \text{tr} (R^T F - I) R
P=2μ(F−R)+λtr(RTF−I)R
相比于线性模型,直观的理解是这个模型手动减去
R
R
R直接去除旋转的影响
旋转无关、各向同性与NeoHookean模型
旋转无关,指弹性体整体旋转不会改变每个位置的能量密度,可以写为 Ψ ( R F ) = Ψ ( F ) \Psi(RF)=\Psi(F) Ψ(RF)=Ψ(F),即先变换后,再进行旋转不会影响能量。
各向同性,弹性体从任意方向进行相同的变换(拉伸旋转平移等)不会影响每个位置的能量密度,可以写为 Ψ ( F Q ) = Ψ ( F ) \Psi(FQ) = \Psi(F) Ψ(FQ)=Ψ(F),即先旋转再进行相同的变换不影响能量。
若模型既是旋转无关也是各向同性的,则能量密度函数满足: Ψ ( R F Q ) = Ψ ( F ) \Psi (RFQ) = \Psi (F) Ψ(RFQ)=Ψ(F)
根据这个形式,自然想到将 F F F进行奇异值分解(SVD) : F = U Σ V T F = U \Sigma V^T F=UΣVT,其中 U U U和 V V V一定为酉矩阵,即 U T U = V T V = I U^T U =V^T V=I UTU=VTV=I,与旋转矩阵一致。而 Σ \Sigma Σ为对角矩阵,在3维情况下自由度仅为3.
故一个满足旋转无关且各向同性的模型,一定满足 Ψ ( F ) = Ψ ( Σ ) \Psi (F) = \Psi (\Sigma) Ψ(F)=Ψ(Σ),并且一定存在某种定义方式,只需要自由度为3的变量,就能定义能量密度函数 Ψ \Psi Ψ。使用 F F F的特征值当然是一种办法,但其非常不方便,所以这里定义了另外3个线性无关的变量,被称作各向同性不变量(isotropic invariants):
注:没有下标的 I I I均表示单位矩阵,有下标的表示各向同性不变量
I
1
(
F
)
=
tr
(
Σ
2
)
=
tr
(
F
T
F
)
I
2
(
F
)
=
tr
(
Σ
4
)
=
tr
[
(
F
T
F
)
2
]
I
3
(
F
)
=
det
(
Σ
2
)
=
(
det
F
)
2
\begin{align} I_1(F) &= \text{tr}(\Sigma ^2) = \text{tr}(F^T F) \\ I_2(F) &= \text{tr}(\Sigma ^4) = \text{tr}\left[(F^T F)^2\right] \\ I_3(F) &= \text{det}(\Sigma ^2) = (\text{det}F)^2 \\ \end{align}
I1(F)I2(F)I3(F)=tr(Σ2)=tr(FTF)=tr(Σ4)=tr[(FTF)2]=det(Σ2)=(detF)2
对这3个变量求微分可以得到:
δ
I
1
=
2
(
I
:
F
:
δ
F
)
=
2
F
:
δ
F
δ
I
2
=
4
tr
(
F
T
F
F
T
δ
F
)
=
4
I
:
F
T
F
F
T
δ
F
=
F
F
T
F
:
δ
F
δ
I
3
=
2
det
(
F
)
δ
[
det
F
]
=
2
(
det
F
)
2
(
F
T
)
−
1
:
δ
F
\begin{align} \delta I_1 & = 2(I:F:\delta F) = 2F : \delta F \\ \delta I_2 & = 4\text{tr} \left( F^TFF^T\delta F \right) = 4 I: F^TFF^T\delta F = FF^TF:\delta F \\ \delta I_3 & = 2\text{det}(F)\delta [\text{det} F] = 2 (\text{det}F)^2(F^T)^{-1} : \delta F \end{align}
δI1δI2δI3=2(I:F:δF)=2F:δF=4tr(FTFFTδF)=4I:FTFFTδF=FFTF:δF=2det(F)δ[detF]=2(detF)2(FT)−1:δF
其中
I
3
I_3
I3用了行列式微分
现在可以定义Neohookean模型了:
Ψ
(
I
1
,
I
3
)
=
μ
2
[
I
1
−
log
(
I
3
)
−
3
]
+
λ
8
log
2
(
I
3
)
\Psi(I_1, I_3) = \frac \mu 2 \left[I_1-\log(I_3) - 3\right] + \frac \lambda 8 \log^2(I_3)
Ψ(I1,I3)=2μ[I1−log(I3)−3]+8λlog2(I3)
此时PK1数很好求:
P
=
∂
Ψ
∂
F
=
μ
2
(
∂
I
1
∂
F
−
1
I
3
∂
I
3
∂
F
)
+
λ
log
(
I
3
)
4
I
3
∂
I
3
∂
F
=
μ
(
F
−
F
−
T
)
+
λ
2
log
(
I
3
)
F
−
T
\begin{align} P & = \frac {\partial \Psi} {\partial F} \\ & = \frac \mu 2 \left( \frac {\partial I_1} {\partial F} - \frac 1 {I_3} \frac {\partial I_3} {\partial F} \right) + \frac {\lambda \log(I_3)} {4 I_3} \frac {\partial I_3} {\partial F} \\ & = \mu \left( F- F^{-T} \right) + \frac \lambda 2 \log(I_3) F^{-T} \end{align}
P=∂F∂Ψ=2μ(∂F∂I1−I31∂F∂I3)+4I3λlog(I3)∂F∂I3=μ(F−F−T)+2λlog(I3)F−T
Neohookean模型保证了旋转无关,各向同性,其能处理强压缩,虽然容易数值爆炸,因为
I
3
=
J
2
I_3 = J^2
I3=J2,当压缩力很大时,体积变化分数
J
→
0
J \rightarrow 0
J→0,会导致能量中的
log
\log
log趋于无穷大,能量也非常大。
各种弹性能量模型对比
借用课程上的一张表
| 名称 | Ψ \Psi Ψ | P P P | 效率 | 旋转无关 | 各向同性 | 能处理强压缩 |
|---|---|---|---|---|---|---|
| 线性模型 | μ tr ( ϵ 2 ) + λ 2 tr 2 ( ϵ ) \mu \text{tr}(\epsilon^2) + \frac \lambda 2 \text{tr}^2(\epsilon) μtr(ϵ2)+2λtr2(ϵ) | μ ( F + F T − 2 I ) + λ tr ( F − I ) I \mu (F + F^T - 2I) + \lambda \text{tr} (F - I) I μ(F+FT−2I)+λtr(F−I)I | 高 | 否 | 否 | 否 |
| StVK | μ tr ( E 2 ) + λ 2 tr 2 ( E ) \mu \text{tr}(E^2) + \frac \lambda 2 \text{tr}^2(E) μtr(E2)+2λtr2(E) | F ( 2 μ E + λ tr ( E ) I ) F(2 \mu E + \lambda \text{tr}(E) I) F(2μE+λtr(E)I) | 低 | 是 | 是 | 否 |
| Corotated | μ ∣ S − I ∣ F 2 + λ 2 tr 2 ( S − I ) \mu |S - I |^2_F +\frac \lambda 2 \text{tr}^2(S-I) μ∣S−I∣F2+2λtr2(S−I) | 2 μ ( F − R ) + λ tr ( R T F − I ) R 2 \mu (F - R) + \lambda \text{tr} (R^T F - I) R 2μ(F−R)+λtr(RTF−I)R | 中 | 是 | 是 | 否 |
| Neohookean | μ 2 [ I 1 − log ( I 3 ) − 3 ] + λ 8 log 2 ( I 3 ) \frac \mu 2 \left[I_1-\log(I_3) - 3\right] + \frac \lambda 8 \log^2(I_3) 2μ[I1−log(I3)−3]+8λlog2(I3) | μ ( F − F − T ) + λ 2 log ( I 3 ) F − T \mu \left( F- F^{-T} \right) + \frac \lambda 2 \log(I_3) F^{-T} μ(F−F−T)+2λlog(I3)F−T | 低 | 是 | 是 | 是 |
有限元方法离散化
在前面有关弹性体的所有推导中,都是将弹性体视为一个拥有无限点的三维区域,这使得计算机无法进行仿真。有限元方法的目的就是用有限的元素去拟合一个无穷的区域,在这里,我们将三维弹性体视为若干个四面体元素:
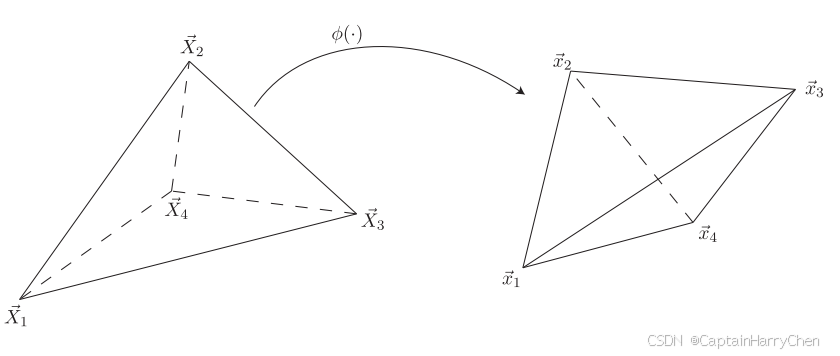
在四面体内部,变换函数将变成线性函数:
ϕ
^
(
X
)
=
A
X
+
b
\hat{\phi}(X) = AX+b
ϕ^(X)=AX+b,因此变换梯度也变得简单:
F
=
A
F = A
F=A. 并且
F
F
F可以使用四面体上的四个点解方程解出来:
[
x
1
−
x
4
x
2
−
x
4
x
3
−
x
4
]
=
F
⋅
[
X
1
−
X
4
X
2
−
X
4
X
3
−
X
4
]
D
s
=
F
⋅
D
m
⇒
F
=
D
s
D
m
−
1
\begin{align} \left[\begin{matrix} \textbf{x}_1-\textbf{x}_4 & \textbf{x}_2-\textbf{x}_4 & \textbf{x}_3-\textbf{x}_4 \end{matrix}\right] & = F\cdot \left[\begin{matrix} X_1-X_4 & X_2-X_4 & X_3-X_4 \end{matrix}\right] \\ D_s & = F \cdot D_m \\ \Rightarrow F & = D_s D_m^{-1} \end{align}
[x1−x4x2−x4x3−x4]Ds⇒F=F⋅[X1−X4X2−X4X3−X4]=F⋅Dm=DsDm−1
令
W
W
W为四面体的体积,可以计算得到
W
=
1
6
∣
det
D
m
∣
W = \frac 1 6 \left | \text{det} D_m \right |
W=61∣detDm∣
则四面体内部
T
i
T_i
Ti的弹性势能为:
E
i
=
∫
T
i
Ψ
(
F
i
)
d
X
=
W
i
Ψ
(
F
i
)
E_i = \int_{T_i} \Psi (F_i) \mathrm{d}X = W_i \Psi (F_i)
Ei=∫TiΨ(Fi)dX=WiΨ(Fi)
每一个四面体都会对它的4个顶点施加弹力,对每一个顶点需要计算它相关的所有四面体对它贡献的弹力,第
i
i
i个四面体对其第
j
j
j个顶点的贡献为
f
i
j
=
−
∂
E
i
∂
x
j
f_i^j = - \frac {\partial E_i} {\partial \textbf{x}_j}
fij=−∂xj∂Ei
令
H
i
=
[
f
i
1
f
i
2
f
i
3
]
H_i = [ f_i^1\ \ f_i^2\ \ f_i^3]
Hi=[fi1 fi2 fi3],则:
f
i
j
=
−
∂
E
i
∂
x
j
=
−
∂
E
i
∂
Ψ
∂
Ψ
∂
F
i
∂
F
i
∂
x
j
=
[
−
W
i
P
(
F
i
)
D
m
−
T
]
j
i
⇒
H
i
=
−
W
i
P
(
F
i
)
D
m
−
T
\begin{align} f_i^j & = - \frac {\partial E_i} {\partial \textbf{x}_j} \\ & = -\frac {\partial E_i} {\partial \Psi} \frac {\partial \Psi} {\partial F_i} \frac {\partial F_i} {\partial \textbf{x}_j} \\ & = \left[-W_i P(F_i)D_m^{-T}\right]_{ji} \\ \Rightarrow H_i & = -W_i P(F_i)D_m^{-T} \end{align}
fij⇒Hi=−∂xj∂Ei=−∂Ψ∂Ei∂Fi∂Ψ∂xj∂Fi=[−WiP(Fi)Dm−T]ji=−WiP(Fi)Dm−T
对于四面体第四个顶点:
f
i
4
=
−
f
i
1
−
f
i
2
−
f
i
3
f_i^4 = -f_i^1 -f_i^2 -f_i^3
fi4=−fi1−fi2−fi3,因为弹性内力要保证整个四面体合力为零
由此可以算出弹性体分成四面体元素后,内部每一个顶点的受力
时间积分
前文已经详细讲述了如何计算通过将弹性体视为四面体后计算每个顶点的受力,知道受力后就可以很方便的使用显示时间积分进行仿真,但隐式时间积分仍然比较困难。本节介绍弹性体仿真时间积分的处理方式,以及一些算法实践上的具体处理。
显示时间积分
以下符号,向量都代表整个弹性体所有点,即 m m m个点,如 x \textbf{x} x为 3 m 3m 3m维
对每一个节点进行如下操作:
x
n
+
1
=
x
n
+
v
n
+
1
Δ
t
v
n
+
1
=
v
n
+
M
−
1
[
f
i
n
t
(
x
n
)
+
f
d
a
m
p
(
v
n
)
+
f
e
x
t
]
Δ
t
\begin{align} \textbf{x}_{n+1} & = \textbf{x}_n + \textbf{v}_{n+1} \Delta t \\ \textbf{v}_{n+1} & = \textbf{v}_n + M^{-1} \left[f_{int} (\textbf{x}_n)+f_{damp}(\textbf{v}_n) + f_{ext}\right] \Delta t \end{align}
xn+1vn+1=xn+vn+1Δt=vn+M−1[fint(xn)+fdamp(vn)+fext]Δt
其中
f
i
n
t
f_{int}
fint表示内力,就是弹性体内部的弹力,需要用前文所述的各种能量计算出来
f d a m p f_{damp} fdamp表示阻尼力,与速度有关,用于能量损耗
f e x t f_{ext} fext为外力,一般与弹性体形态无关,很容易计算,如重力
隐式时间积分
需要计算如下方程:
x
n
+
1
=
x
n
+
v
n
+
1
Δ
t
v
n
+
1
=
v
n
+
M
−
1
[
f
i
n
t
(
x
n
+
1
)
+
f
d
a
m
p
(
v
n
+
1
)
+
f
e
x
t
]
Δ
t
\begin{align} \textbf{x}_{n+1} & = \textbf{x}_n + \textbf{v}_{n+1} \Delta t \\ \textbf{v}_{n+1} & = \textbf{v}_n + M^{-1} \left[f_{int} (\textbf{x}_{n+1}) + f_{damp}(\textbf{v}_{n+1}) + f_{ext}\right] \Delta t \end{align}
xn+1vn+1=xn+vn+1Δt=vn+M−1[fint(xn+1)+fdamp(vn+1)+fext]Δt
对于阻尼力
f
d
a
m
p
f_{damp}
fdamp,如果难以处理,也可以使用
f
d
a
m
p
(
v
n
)
f_{damp} (\textbf{v}_n )
fdamp(vn)做半隐式积分。
对于内力
f
i
n
t
(
x
n
+
1
)
f_{int} (\textbf{x}_{n+1})
fint(xn+1),一般采用泰勒展开近似:(省略了下标)
f
(
x
n
+
1
)
≈
f
(
x
n
)
+
∂
f
∂
x
∣
x
n
(
x
n
+
1
−
x
n
)
f (\textbf{x}_{n+1}) ≈ f (\textbf{x}_n) + \frac {\partial f} {\partial \textbf{x}} \bigg |_{\textbf{x}_n}(\textbf{x}_{n+1} - \textbf{x}_n)
f(xn+1)≈f(xn)+∂x∂f
xn(xn+1−xn)
为此我们需要求解刚度矩阵:
K
(
x
n
)
=
−
∂
f
∂
x
∣
x
n
K(\textbf{x}_n) = - \frac {\partial f} {\partial \textbf{x}} \bigg |_{\textbf{x}_n}
K(xn)=−∂x∂f
xn,这个刚度矩阵是一个
3
m
×
3
m
3m \times 3m
3m×3m的矩阵,但我们计算时一般只考虑一个四面体,一个四面体至少需要考虑到3个顶点,那么算法运行时需要用到一个
3
×
3
×
3
×
3
3 \times 3 \times 3 \times 3
3×3×3×3的矩阵,这依然是一个比较大的运算量。实现时,可以直接将这个巨型矩阵直接算出来(比如VegaFEM);也可以用隐式计算的方法,直接计算
K
⋅
w
K \cdot w
K⋅w,只需要在求微分
δ
K
\delta K
δK之后,把里面的所有
δ
x
\delta \textbf{x}
δx换成
w
w
w即可。
现在来考察一下
K
K
K,通过对力
f
f
f求微分来推导:
K
(
x
n
)
δ
x
=
∂
f
∂
x
δ
x
=
δ
f
δ
H
=
[
δ
f
1
δ
f
2
δ
f
3
]
=
−
W
δ
P
(
F
)
D
m
−
T
δ
P
(
F
)
=
{
δ
F
[
2
μ
E
+
λ
tr
(
E
)
I
]
+
F
[
2
μ
δ
E
+
λ
tr
(
δ
E
)
I
]
if using StVK model
μ
δ
F
+
[
μ
−
λ
log
(
J
)
]
F
−
T
δ
F
T
F
−
T
+
λ
tr
(
F
−
1
δ
F
)
F
−
T
if using Neohookean model
δ
F
=
(
δ
D
s
)
D
m
−
1
δ
D
s
=
[
δ
x
1
−
δ
x
4
δ
x
2
−
δ
x
4
δ
x
3
−
δ
x
4
]
\begin{align} K(\textbf{x}_n) \delta \textbf{x} & = \frac {\partial f} {\partial \textbf{x}} \delta \textbf{x} = \delta f \\ \delta H & = \left[ \begin{matrix} \delta f_1 & \delta f_2 & \delta f_3 \end{matrix} \right] \\ & = - W \delta P (F) D_m^{-T} \\ \delta P(F) & = \begin{cases} \delta F \left[ 2 \mu E + \lambda \text{tr}(E) I \right] + F \left[ 2 \mu \delta E + \lambda \text{tr}(\delta E) I \right] &\text{if using StVK model} \\ \mu \delta F + \left[ \mu - \lambda \log (J) \right] F^{-T} \delta F^T F^{-T} + \lambda \text{tr}(F^{-1} \delta F) F^{-T} & \text{if using Neohookean model} \\ \end{cases} \\ \delta F & = (\delta D_s) D_m^{-1} \\ \delta D_s & = \left[ \begin{matrix} \delta \textbf{x}_1 - \delta \textbf{x}_4 & \delta \textbf{x}_2 - \delta \textbf{x}_4 & \delta \textbf{x}_3 - \delta \textbf{x}_4 \end{matrix} \right] \end{align}
K(xn)δxδHδP(F)δFδDs=∂x∂fδx=δf=[δf1δf2δf3]=−WδP(F)Dm−T={δF[2μE+λtr(E)I]+F[2μδE+λtr(δE)I]μδF+[μ−λlog(J)]F−TδFTF−T+λtr(F−1δF)F−Tif using StVK modelif using Neohookean model=(δDs)Dm−1=[δx1−δx4δx2−δx4δx3−δx4]
注: J = I 3 = det F J = \sqrt {I_3} = \text{det} F J=I3=detF是体积变化分数
根据以上公式可以对任意弹性模型计算 K ( x n ) ⋅ w K(\textbf{x}_n)\cdot w K(xn)⋅w,只需要最终在 δ D s \delta D_s δDs中,把 δ x \delta \textbf{x} δx替换为对应位置的 w w w即可。在Siggraph 2012的FEM course中推荐的就是这个计算 K K K的方法。
VegaFEM的实现方法
令 Δ x = x n + 1 − x n , Δ v = v n + 1 − v n \Delta \textbf{x} = \textbf{x}_{n+1} - \textbf{x}_n,\Delta \textbf{v} = \textbf{v}_{n+1} - \textbf{v}_n Δx=xn+1−xn,Δv=vn+1−vn
对于阻尼力,令 f d a m p ( v n + 1 ) = ( α 1 ⋅ ( − K ( x n ) ) + α 2 ⋅ M ) ⋅ v n + 1 = − D ⋅ v n + 1 f_{damp} (\textbf{v}_{n+1}) = (\alpha_1 \cdot (-K(\textbf{x}_n)) + \alpha_2 \cdot M) \cdot \textbf{v}_{n+1} = -D \cdot \textbf{v}_{n+1} fdamp(vn+1)=(α1⋅(−K(xn))+α2⋅M)⋅vn+1=−D⋅vn+1
则
Δ
v
=
Δ
t
M
−
1
[
f
i
n
t
(
x
n
)
−
K
(
x
n
)
⋅
Δ
x
−
D
⋅
v
n
+
1
]
M
⋅
Δ
v
=
Δ
t
f
i
n
t
(
x
n
)
−
Δ
t
2
K
(
x
n
)
⋅
Δ
v
−
Δ
t
D
(
v
n
+
Δ
v
)
[
Δ
t
2
K
(
x
n
)
+
Δ
t
D
+
M
]
⋅
Δ
v
=
Δ
t
[
f
i
n
t
(
x
n
)
−
(
Δ
t
K
(
x
n
)
+
D
)
v
n
]
\begin{align} \Delta \textbf{v} & = \Delta t M^{-1}\left[ f_{int}(\textbf{x}_n) - K(\textbf{x}_n) \cdot \Delta \textbf{x} - D \cdot \textbf{v}_{n+1} \right] \\ M \cdot \Delta \textbf{v} & = \Delta t f_{int} (\textbf{x}_n) - \Delta t^2 K(\textbf{x}_n) \cdot \Delta \textbf{v} - \Delta t D (\textbf{v}_n + \Delta \textbf{v}) \\ \left[\Delta t^2 K(\textbf{x}_n) + \Delta t D + M \right] \cdot \Delta \textbf{v} & = \Delta t \left[f_{int}(\textbf{x}_n) - (\Delta t K(\textbf{x}_n) + D) \textbf{v}_n\right] \end{align}
ΔvM⋅Δv[Δt2K(xn)+ΔtD+M]⋅Δv=ΔtM−1[fint(xn)−K(xn)⋅Δx−D⋅vn+1]=Δtfint(xn)−Δt2K(xn)⋅Δv−ΔtD(vn+Δv)=Δt[fint(xn)−(ΔtK(xn)+D)vn]
方程已经变成了
A
X
=
b
AX=b
AX=b的形式,可以使用各种方式迭代解出
Δ
v
\Delta \textbf{v}
Δv,比如下面Projective Dynamics将会详细讲的一种雅可比迭代法(Jacobi)
注: Siggraph 2012的FEM course中的方法与此类似,只不过公式的推导过程变成了求解 Δ x \Delta \textbf{x} Δx而不是 Δ v \Delta \textbf{v} Δv,与下面的Projective Dynamics也很类似。
Projective Dynamics (PD) 方法
PD算法的主要思路是,对每一个非线性约束,用投影的方式找到满足约束的位置,然后将约束视为到投影位置的某种距离(是个二次式),从而将整个非线性问题转化为一个二次优化问题。
比如弹性体中,四面体网格的弹性内力可以视为约束力,通过投影到最近的零势能位置(rest position),就可以转化为二次优化问题。
但是,仔细考虑就可以发现,这种投影方式本质上就是之前提到过的:将非线性的弹力计算函数用一阶泰勒展开近似。
下面来推导一下:
x
n
+
1
=
x
n
+
v
n
+
1
Δ
t
v
n
+
1
=
v
n
+
M
−
1
[
f
i
n
t
(
x
n
+
1
)
+
f
e
x
t
]
Δ
t
⇒
x
n
+
1
=
x
n
+
Δ
t
v
n
+
Δ
t
2
M
−
1
[
f
i
n
t
(
x
n
+
1
)
+
f
e
x
t
]
1
Δ
t
2
M
(
x
n
+
1
−
x
n
−
Δ
t
v
n
−
Δ
t
2
M
−
1
f
e
x
t
)
=
f
i
n
t
(
x
n
+
1
)
令
x
^
n
=
x
n
+
Δ
t
v
n
+
Δ
t
2
M
−
1
f
e
x
t
1
Δ
t
2
M
(
x
n
+
1
−
x
^
n
)
=
f
i
n
t
(
x
n
+
1
)
≈
K
(
x
(
k
)
)
⋅
(
x
n
+
1
−
x
(
k
)
)
+
f
i
n
t
(
x
^
n
)
\begin{align} \textbf{x}_{n+1} & = \textbf{x}_n + \textbf{v}_{n+1} \Delta t \\ \textbf{v}_{n+1} & = \textbf{v}_n + M^{-1} \left[f_{int} (\textbf{x}_{n+1}) + f_{ext}\right] \Delta t \\ \Rightarrow \textbf{x}_{n+1} & = \textbf{x}_n + \Delta t \textbf{v}_n + \Delta t^2 M^{-1} \left[f_{int}(\textbf{x}_{n+1}) + f_{ext}\right] \\ \frac 1 {\Delta t^2} &M \left(\textbf{x}_{n+1} - \textbf{x}_n - \Delta t \textbf{v}_n - \Delta t^2 M^{-1} f_{ext} \right) = f_{int}(\textbf{x}_{n+1})\\ 令 \hat{\textbf{x}}_n & = \textbf{x}_n + \Delta t \textbf{v}_n + \Delta t^2 M^{-1} f_{ext} \\ \frac 1 {\Delta t^2} M \left(\textbf{x}_{n+1} - \hat{\textbf{x}}_n \right)& = f_{int}(\textbf{x}_{n+1}) \approx K(\textbf{x}^{(k)}) \cdot \left(\textbf{x}_{n+1} - \textbf{x}^{(k)} \right) + f_{int} (\hat{\textbf{x}}_n)\\ \end{align}
xn+1vn+1⇒xn+1Δt21令x^nΔt21M(xn+1−x^n)=xn+vn+1Δt=vn+M−1[fint(xn+1)+fext]Δt=xn+Δtvn+Δt2M−1[fint(xn+1)+fext]M(xn+1−xn−Δtvn−Δt2M−1fext)=fint(xn+1)=xn+Δtvn+Δt2M−1fext=fint(xn+1)≈K(x(k))⋅(xn+1−x(k))+fint(x^n)
假设我们有一个迭代求解序列 x ( 0 ) , . . . , x ( k ) \textbf{x}^{(0)}, ..., \textbf{x}^{(k)} x(0),...,x(k),使得其越来越逼近于 x n + 1 \textbf{x}_{n+1} xn+1,并且初始 x ( 0 ) = x ^ n \textbf{x}^{(0)}=\hat{\textbf{x}}_n x(0)=x^n
我们可以将方程写为:
( 1 Δ t 2 M − K ( x ( k ) ) ) ⋅ x ( k + 1 ) = 1 Δ t 2 M x ^ n + f i n t ( x ( k ) ) − K ( x ( k ) ) x ( k ) \left(\frac 1 {\Delta t^2} M - K(\textbf{x}^{(k)})\right) \cdot \textbf{x}^{(k+1)} = \frac 1 {\Delta t^2} M \hat{\textbf{x}}_n + f_{int}(\textbf{x}^{(k)}) - K(\textbf{x}^{(k)})\textbf{x}^{(k)} (Δt21M−K(x(k)))⋅x(k+1)=Δt21Mx^n+fint(x(k))−K(x(k))x(k)
此时求解 x ( k + 1 ) \textbf{x}^{(k+1)} x(k+1)已经是 A X = b AX=b AX=b的形式了,接下来讲一讲迭代求解。
令
A
=
B
−
C
A=B-C
A=B−C, 则
(
B
−
C
)
X
=
b
B
X
−
C
X
=
b
B
X
=
C
X
+
b
X
=
B
−
1
(
C
X
+
b
)
(B-C)X=b \\ BX - CX = b \\ BX = CX + b \\ X = B^{-1} (CX + b)
(B−C)X=bBX−CX=bBX=CX+bX=B−1(CX+b)
使用一个迭代序列
X
(
0
)
,
.
.
.
,
X
(
k
)
X^{(0)}, ..., X^{(k)}
X(0),...,X(k),令:
X
(
k
+
1
)
=
B
−
1
(
C
X
(
k
)
+
b
)
X^{(k+1)} = B^{-1} (CX^{(k)} + b)
X(k+1)=B−1(CX(k)+b)
一般我们取 B B B为 A A A的对角元素,因为往往物理方程上面 A A A的对角元素都比其他元素大,占主要部分,这样这个序列会更快收敛到方程的解。
我们计算一下
X
(
k
+
1
)
−
X
(
k
)
X^{(k+1)}-X^{(k)}
X(k+1)−X(k):
X
(
k
+
1
)
=
B
−
1
(
B
−
A
)
X
(
k
)
+
B
−
1
b
X
(
k
+
1
)
−
X
(
k
)
=
B
−
1
(
b
−
A
X
(
k
)
)
X^{(k+1)} = B^{-1}(B-A)X^{(k)} + B^{-1} b\\ X^{(k+1)}-X^{(k)}=B^{-1}(b-AX^{(k)})
X(k+1)=B−1(B−A)X(k)+B−1bX(k+1)−X(k)=B−1(b−AX(k))
现在我们代入到之前的隐式欧拉积分方程:
A
=
1
Δ
t
2
M
−
K
(
x
(
k
)
)
B
=
diag
{
A
}
X
(
k
)
=
x
(
k
)
b
=
1
Δ
t
2
M
x
^
n
+
f
i
n
t
(
x
(
k
)
)
−
K
(
x
(
k
)
)
x
(
k
)
x
(
k
+
1
)
−
x
(
k
)
=
B
−
1
(
1
Δ
t
2
M
x
n
^
+
f
i
n
t
(
x
(
k
)
)
−
K
(
x
(
k
)
)
x
(
k
)
−
1
Δ
t
2
M
x
(
k
)
+
K
(
x
(
k
)
)
x
(
k
)
)
x
(
k
+
1
)
−
x
(
k
)
=
B
−
1
(
1
Δ
t
2
M
(
x
n
^
−
x
(
k
)
)
+
f
i
n
t
(
x
(
k
)
)
)
\begin{align} A&=\frac 1 {\Delta t^2} M - K(\textbf{x}^{(k)})\\ B&=\text{diag}\{A\} \\ X^{(k)}&=\textbf{x}^{(k)}\\ b&=\frac 1 {\Delta t^2} M \hat{\textbf{x}}_n + f_{int}(\textbf{x}^{(k)}) - K(\textbf{x}^{(k)})\textbf{x}^{(k)} \end{align} \\ \begin{align} \textbf{x}^{(k+1)} - \textbf{x}^{(k)} &= B^{-1}\left( \frac 1 {\Delta t^2} M \hat{\textbf{x}_n} + f_{int} (\textbf{x}^{(k)})-K(\textbf{x}^{(k)})\textbf{x}^{(k)} - \frac 1 {\Delta t^2} M \textbf{x}^{(k)} + K(\textbf{x}^{(k)})\textbf{x}^{(k)}\right) \\ \textbf{x}^{(k+1)} - \textbf{x}^{(k)} &= B^{-1}\left( \frac 1 {\Delta t^2} M \left(\hat{\textbf{x}_n} - \textbf{x}^{(k)}\right) + f_{int} (\textbf{x}^{(k)}) \right) \end{align}
ABX(k)b=Δt21M−K(x(k))=diag{A}=x(k)=Δt21Mx^n+fint(x(k))−K(x(k))x(k)x(k+1)−x(k)x(k+1)−x(k)=B−1(Δt21Mxn^+fint(x(k))−K(x(k))x(k)−Δt21Mx(k)+K(x(k))x(k))=B−1(Δt21M(xn^−x(k))+fint(x(k)))
最终等式右边以全部是已知量,直接迭代求解即可。
还可以参考这篇文章使用切比雪夫多项式加速:A Chebyshev Semi-Iterative Approach for Accelerating Projective and Position-based Dynamic
计算出 x ( k + 1 ) − x ( k ) \textbf{x}^{(k+1)} - \textbf{x}^{(k)} x(k+1)−x(k)之后,还可以进一步使用线搜索(line search)算法来计算迭代步长,进一步优化收敛速度
在A Chebyshev Semi-Iterative Approach for Accelerating Projective and Position-based Dynamic的实现中,使用的能量模型并不是前文提到的3中模型之一,而是只用了共旋转线性模型(Corotated Linear Elasticity)的一半,即 Ψ ( F ) = μ ∥ S − I ∥ F 2 = μ ∥ F − R ∥ F 2 \Psi (F) = \mu \| S - I \| ^2_F = \mu \| F - R \| ^2_F Ψ(F)=μ∥S−I∥F2=μ∥F−R∥F2.
此时 P ( F ) = 2 μ ( F − R ) P(F) = 2 \mu (F-R) P(F)=2μ(F−R)。
并且该文章的实现在计算 B − 1 B^{-1} B−1中的 K ( x ( k ) ) K(\textbf{x}^{(k)}) K(x(k))的对角元时,忽略了 P ( F ) P(F) P(F)中矩阵分解出来的 R R R,故 ∂ P ∂ F ≈ 2 μ ⋅ I \frac {\partial P} {\partial F} \approx 2 \mu \cdot I ∂F∂P≈2μ⋅I,可以推出 δ H ≈ − 2 μ W ⋅ δ D s ⋅ D m − 1 D m − T \delta H \approx - 2\mu W \cdot \delta D_s \cdot D_m^{-1} D_m^{-T} δH≈−2μW⋅δDs⋅Dm−1Dm−T.
这使得计算出来的 K ( x ( k ) ) K(\textbf{x}^{(k)}) K(x(k))与 x ( k ) \textbf{x}^{(k)} x(k)无关,故可以将其在读取模型的时候进行预处理,从而大幅加速求解速度。
文章的实验显示这种近似是可行的。
Incremental Potential Contact (IPC) 方法
x n + 1 = x n + v n + 1 Δ t v n + 1 = v n + M − 1 [ f i n t ( x n + 1 , v n + 1 ) + f e x t ] Δ t ⇒ x n + 1 = x n + Δ t v n + Δ t 2 M − 1 [ f i n t ( x n + 1 , v n + 1 ) + f e x t ] x n + 1 − ( x n + Δ t v n + Δ t 2 M − 1 f e x t ) − Δ t 2 M − 1 f i n t ( x n + 1 , v n + 1 ) = 0 令 x ^ n = x n + Δ t v n + Δ t 2 M − 1 f e x t M ( x n + 1 − x ^ n ) − Δ t 2 f i n t ( x n + 1 , v n + 1 ) = 0 \begin{align} \textbf{x}_{n+1} & = \textbf{x}_n + \textbf{v}_{n+1} \Delta t \\ \textbf{v}_{n+1} & = \textbf{v}_n + M^{-1} \left[f_{int} (\textbf{x}_{n+1}, \textbf{v}_{n+1}) + f_{ext}\right] \Delta t \\ \Rightarrow \textbf{x}_{n+1} & = \textbf{x}_n + \Delta t \textbf{v}_n + \Delta t^2 M^{-1} \left[f_{int}(\textbf{x}_{n+1}, \textbf{v}_{n+1}) + f_{ext}\right] \\ \textbf{x}_{n+1} & - \left( \textbf{x}_n + \Delta t \textbf{v}_n + \Delta t^2 M^{-1} f_{ext}\right) - \Delta t^2 M^{-1} f_{int}(\textbf{x}_{n+1}, \textbf{v}_{n+1}) = 0 \\ 令 \hat{\textbf{x}}_n & = \textbf{x}_n + \Delta t \textbf{v}_n + \Delta t^2 M^{-1} f_{ext} \\ M(\textbf{x}_{n+1} & - \hat{\textbf{x}}_n) - \Delta t^2 f_{int} (\textbf{x}_{n+1} , \textbf{v}_{n+1}) = 0 \end{align} xn+1vn+1⇒xn+1xn+1令x^nM(xn+1=xn+vn+1Δt=vn+M−1[fint(xn+1,vn+1)+fext]Δt=xn+Δtvn+Δt2M−1[fint(xn+1,vn+1)+fext]−(xn+Δtvn+Δt2M−1fext)−Δt2M−1fint(xn+1,vn+1)=0=xn+Δtvn+Δt2M−1fext−x^n)−Δt2fint(xn+1,vn+1)=0
我们将其转为一个优化问题,即最小化:
E
(
x
)
=
1
2
∥
x
−
x
^
n
∥
M
+
Δ
t
2
Ψ
(
x
)
因为
E
′
(
x
)
=
M
(
x
n
+
1
−
x
^
n
)
−
Δ
t
2
f
i
n
t
(
x
n
+
1
,
v
n
+
1
)
则只需求解
x
n
+
1
=
argmin
x
E
(
x
)
E(\textbf{x}) = \frac 1 2 \left \| \textbf{x} - \hat{\textbf{x}}_n \right \|_M + \Delta t^2 \Psi (\textbf{x}) \\ 因为 E'(\textbf{x}) = M(\textbf{x}_{n+1} - \hat{\textbf{x}}_n) - \Delta t^2 f_{int} (\textbf{x}_{n+1} , \textbf{v}_{n+1}) \\ 则只需求解 \textbf{x}_{n+1} = \text{argmin}_{\textbf{x}} E(\textbf{x})
E(x)=21∥x−x^n∥M+Δt2Ψ(x)因为E′(x)=M(xn+1−x^n)−Δt2fint(xn+1,vn+1)则只需求解xn+1=argminxE(x)
E
(
x
)
E(\textbf{x})
E(x)被称为 Increment Potential,可以看出
1
2
∥
x
−
x
^
n
∥
M
\frac 1 2 \left \| \textbf{x} - \hat{\textbf{x}}_n \right \|_M
21∥x−x^n∥M与惯性势能相关,
Δ
t
2
Ψ
(
x
)
\Delta t^2 \Psi(\textbf{x})
Δt2Ψ(x)与弹性势能有关。优化问题的目的就是找到一个势能最小的位置作为下一时间步的状态。注意到这个
E
(
x
)
E(\textbf{x})
E(x)还可以添加其他能量包括碰撞,摩擦等。
IPC使用牛顿-拉夫逊方法结合线搜索(line search)迭代优化
E
(
x
)
E(\textbf{x})
E(x),即
H
E
(
x
)
⋅
v
=
−
D
E
(
x
)
H_E(\textbf{x}) \cdot v = - D_E(\textbf{x})
HE(x)⋅v=−DE(x)
其中
H
E
(
x
)
H_E(\textbf{x})
HE(x)为
E
E
E的二阶导(海塞矩阵),
D
E
D_E
DE为一阶导,这里面涉及到对
Ψ
\Psi
Ψ求二阶导
求解出 v v v后作为搜索的方向,使用线搜索结合连续碰撞检测(CCD),找到最佳步长进行移动,重复这个步骤直到时间步长加起来达到一个仿真步。
参考资料
FEM simulation of 3D deformable solids Siggraph 2012 Course
A Chebyshev Semi-Iterative Approach for Accelerating Projective and Position-based Dynamic
Projective Dynamics: Fusing Constraint Projections for Fast Simulation


















 1331
1331

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











