




 本文介绍了海森矩阵的概念及其在数学优化中的应用。海森矩阵是由实值函数的二阶偏导数组成的方块矩阵,用于判断临界点是局部极小点、局部极大点还是鞍点。此外还讨论了海森矩阵的对称性和其在高维情况下的推广。
本文介绍了海森矩阵的概念及其在数学优化中的应用。海森矩阵是由实值函数的二阶偏导数组成的方块矩阵,用于判断临界点是局部极小点、局部极大点还是鞍点。此外还讨论了海森矩阵的对称性和其在高维情况下的推广。
在数学中,海森矩阵(Hessian matrix 或 Hessian)是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵,此函数如下:
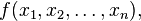
如果 f 所有的二阶导数都存在,那么 f 的海森矩阵即:
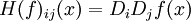
其中 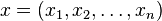 ,即
,即

(也有人把海森定义为以上矩阵的行列式) 海森矩阵被应用于牛顿法解决的大规模优化问题。
混合偏导数和海森矩阵的对称性[编辑]
海森矩阵的混合偏导数是海森矩阵非主对角线上的元素。假如他们是连续的,那么求导顺序没有区别,即
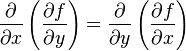
上式也可写为

在正式写法中,如果 f 函数在区域 D 内连续并处处存在二阶导数,那么 f的海森矩阵在 D 区域内为对称矩阵。
在  →
→ 的函数的应用[编辑]
的函数的应用[编辑]
给定二阶导数连续的函数 ,海森矩阵的行列式,可用于分辨
,海森矩阵的行列式,可用于分辨  的临界点是属于鞍点还是极值点。
的临界点是属于鞍点还是极值点。
对于 的临界点 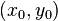 一点,有
一点,有 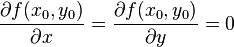 ,然而凭一阶导数不能判断它是鞍点、局部极大点还是局部极小点。海森矩阵可能解答这个问题。
,然而凭一阶导数不能判断它是鞍点、局部极大点还是局部极小点。海森矩阵可能解答这个问题。

- H > 0 :若
 ,则是局部极小点;若
,则是局部极小点;若 ,则是局部极大点。
,则是局部极大点。 - H < 0 :是鞍点。
- H = 0 :二阶导数无法判断该临界点的性质,得从更高阶的导数以泰勒公式考虑。
在高维情况下的推广[编辑]
当函数 二阶连续可导时,Hessian矩阵H在临界点
二阶连续可导时,Hessian矩阵H在临界点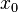 上是一个
上是一个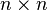 阶的对称矩阵。
阶的对称矩阵。


















 1782
1782

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









