




今日任务:
- 参考文档补全剩余的几个图
- 尝试确定一下shap各个绘图函数对于每一个参数的尺寸要求,如shap.force_plot力图中的数据需要满足什么形状
- 确定分类问题和回归问题的数据如何才能满足尺寸,分类采取信贷数据集,回归采取单车数据集
参考文档:SHAP 可视化解释机器学习模型简介
可解释分析
在机器学习模型中,输入数据后给出预测,但在这个过程中的内部决策逻辑是看不见的,就像一个‘黑箱’。而可解释性分析就是打开这个黑箱,理解模型“为什么会做出这样的预测”。
常见的可解释性分析方法可分为内在可解释模型和事后可解释方法。
- 内在可解释性模型:模型本身的结构简单,天然具备可解释性。如线性回归、决策树等。
- 事后可解释方法:在训练好的(通常是复杂的)“黑箱”模型之上,使用另一种方法来解释它。
这里主要说明事后可解释方法(解释任何模型),包括全局可解释性方法和局部可解释性方法。全局可解释方法理解模型的整体行为逻辑,即“模型在所有数据上平均来看,是依赖什么规律进行预测的”。而局部可解释方法理解模型对单个特定样本的预测结果,即“为什么模型给这个样本做出了这样的预测?”
| 方法 | 范围 | 核心思想 | 输出 | 优点 |
|---|---|---|---|---|
| 特征重要性 | 全局 | 衡量特征对模型性能的贡献 | 特征排名 | 快速、直观、可用于特征选择 |
| 部分依赖图 | 全局 | 特征对预测的平均边际效应 | 特征值与预测值的关系曲线 | 展示宏观趋势,易于理解 |
| LIME | 局部 | 用简单模型局部拟合黑箱 | 单个预测的特征权重 | 非常灵活,模型无关,适用多种数据类型 |
| SHAP | 局部&全局 | 基于博弈论公平分配预测贡献值 | 单个预测的特征贡献值 | 理论扎实,一致性强,统一了局部与全局 |
| 反事实解释 | 局部 | 寻找最小改变以翻转决策 | “如果…那么…”的陈述 | 极其直观,可操作性强,用户友好 |
SHAP的原理
SHAP属于事后可解释方法。它基于博弈论数学基础(Shapley值),核心思想是将模型的最终预测值视为所有特征“合作”的结果,公平地分配每个特征对这个最终预测值的贡献度。
对于SHAP的工作原理:
- 对于一个预测 f(x),SHAP会计算所有可能的特征组合(子集)的预测值。
- 通过比较包含某个特征和不包含该特征时预测值的差异(’边际贡献‘),Shapley值是该特征在所有可能的特征组合中边际贡献的加权平均值来公平地分配该特征的贡献。
- 最终,将预测值 f(x)表示为基准值(所有预测的平均值)与所有特征SHAP值之和的形式:f(x) = 基准值 +
,其中
就是特征 i 的SHAP值。
应用及绘图说明
解释器初始化
使用SHAP库绘图之前,先选择解释器进行初始化,然后计算shap值。
对于解释器的选择,下列为常用的三种:
- TreeExplainer:基于树模型,快速准确
- GradientExplainer:深度学习模型
- KernelExplainer:通用但速度慢
import shap
#初始化解释器
explainer = shap.TreeExplainer(rf_model)
#计算shap值
shap_values = explainer.shap_values(X_test) #计算耗时,返回Numpy数组调用解释器中的shap_values()计算后,返回的是一个numpy数组。对于回归问题,模型只有一个输出,故而返回的是二维数组(n_samples,n_features)。而对于分类问题,模型通常为每个类别输出一个分数或概率,故而返回的是三维数组(n_samples,n_features,n_classes)。对于多维数组的查看,方式类似列表的切片和索引方式。
绘图
Summary Plot(bar、dot、violin)
Bar
可以用来快速查看特征重要性排名,使用shap库中的summary_plot()函数:
- shap_values[:, :, 0]:shap值数组
- X_test:特征数据,提供特征名称和实际数值,用于在图上显示特征标签,尺寸与SHAP数组匹配
- plot_type="bar":指定绘图类型,bar/dot/violin
- show=False:True or False,是否立即显示,选择False便于自定义
- max_display:显示前n个特征数量,默认为20
import matplotlib.pyplot as plt
shap.summary_plot(shap_values[:, :, 0], X_test, plot_type="bar",show=False) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Bar Plot)")
plt.show()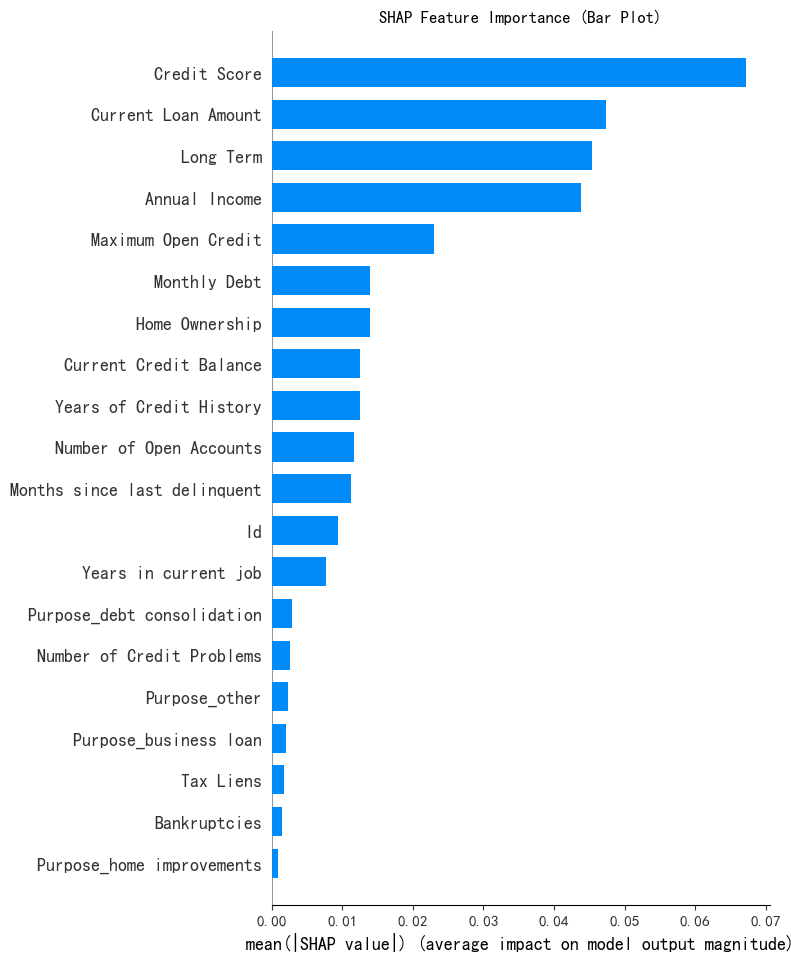
Dot
分析特征值与SHAP值的关系,显示的是所有样本的所有SHAP值。点的颜色表示特征值的大小(红色为高,蓝色为低),适合数据较少时使用。
shap.summary_plot(shap_values[:, :, 0], X_test,plot_type="dot",show=False,max_display=10) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()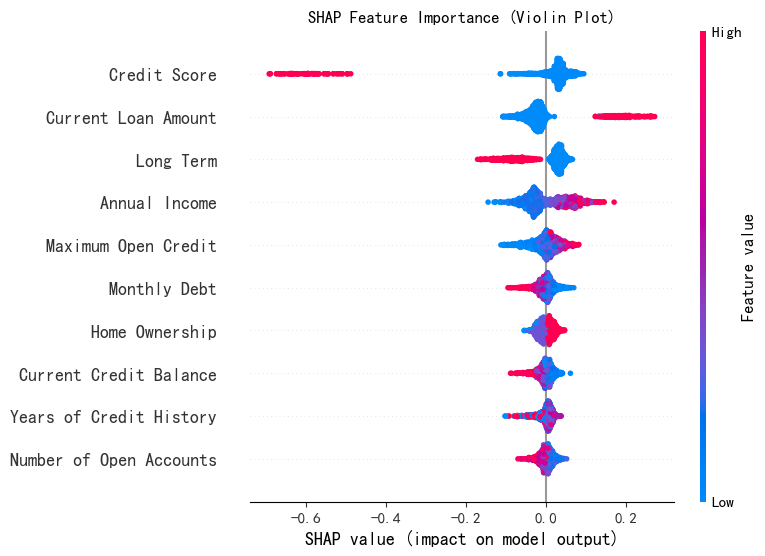
Violin
查看SHAP值的详细分布,是Dot图的平滑聚合,展示了SHAP值的概率密度分布。形状的宽度表示在特定SHAP值范围内样本的密度。一般,使用violin图。
shap.summary_plot(shap_values[:, :, 0], X_test,plot_type="violin",show=False,max_display=10) # 这里的show=False表示不直接显示图形,这样可以继续用plt来修改元素,不然就直接输出了
plt.title("SHAP Feature Importance (Violin Plot)")
plt.show()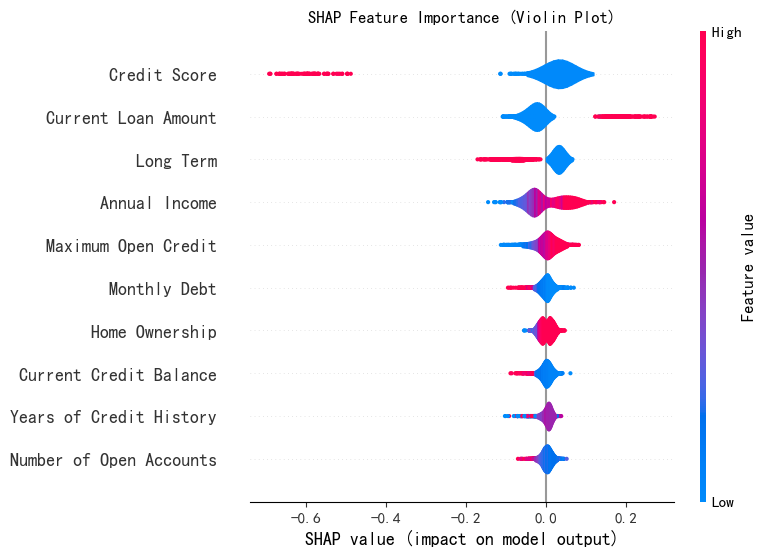
Dependence_plot 依赖图
展示一个目标特征在整个数据集上的值与其对应的SHAP值之间的关系。用途如下:
- 理解特征影响的非线性关系
- 检测和可视化特征交互效应
- 验证模型行为是否符合业务逻辑
在绘图时,使用dependence_plot()。可设置 interaction_index='auto'。SHAP会自动计算与目标特征有最强交互效应的特征,并用它来着色。
shap.dependence_plot(0, shap_values[:, :, 0], X_test, show=False)
# 参数0表示要绘制的特征索引,参考data.columns;shap_values[:, :, 0]表示SHAP值,X_test表示特征数据
# 也可以指定特征名称,例如:shap.dependence_plot("Loan Amount", shap_values[:, :, 0], X_test, show=False)
# interaction_index = 'auto',自动选择与主要特征交互性最强的特征来着色
plt.title("SHAP Dependence Plot")
plt.show()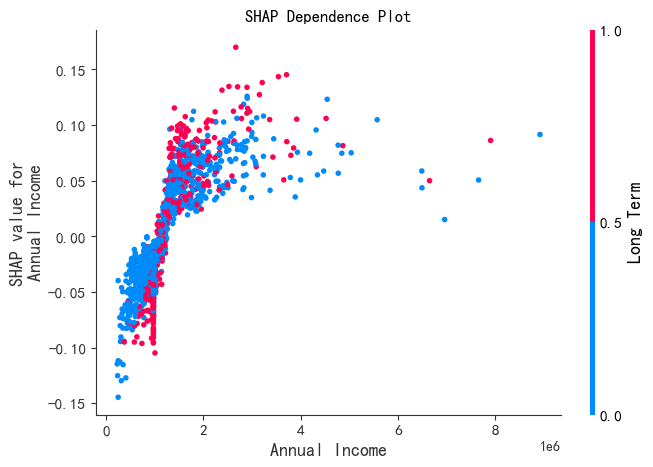
Force_plot 力导向图
用于单样本解释,将模型的单个预测值直观地分解为每个特征的贡献值之和。它生动地展示了所有特征是如何“合力”将模型的基准预测(所有训练样本预测的平均值)“推”或“拉”到最终的预测值的。
对于force_plot的解读关注以下几个方面:
- 基准值(Base Value):没有任何特征信息的特征预测,模型对所有训练样本的平均预测值
- 最终预测值f(x):综合所有信息后的预测值(实际)
- 特征贡献度:红色箭头(向右的推力,提高);蓝色箭头(向左的拉力,降低)
plt.figure(figsize=(15, 4))
shap.force_plot(explainer.expected_value[0],# 期望值,即模型的基线预测值
shap_values[0][:, 0],# shap_values[0]表示第一个类别的SHAP值,shap_values[0][:, 0]表示第一个样本的SHAP值
# 也可以指定其他样本,例如:shap_values[0][:, 1]表示第二个样本的SHAP值,X_test.iloc[1,:]表示第二个样本的特征值
X_test.iloc[0,:],# 表示第一个样本的特征值
matplotlib=True, # 使用matplotlib绘制图形
show=False, # 不直接显示图形
text_rotation=30) # text_rotation表示文本旋转角度
# 这里的shap_values[0][:, 0],X_test.iloc[0,:]
# 表示第一个样本的SHAP值和特征值,
# 也可以指定其他样本,例如:shap_values[0][:, 1]表示第二个样本的SHAP值,X_test.iloc[1,:]表示第二个样本的特征值
plt.title("SHAP Force Plot for Single Sample", pad=20)
plt.tight_layout()
plt.show()
Decision_plot 决策图
决策图展示了对于一个或多个样本,各个特征是如何通过其SHAP值累积起来,最终形成模型预测值的。可以看作force_plot的’纵向‘版本,适合同时分析和比较多个样本。
关于决策图的解读:
- X轴、Y轴:X轴为累计的SHAP值;Y轴为特征列表,通常按SHAP值的重要性排序
- 起点:最左侧的垂直线代表模型的
base_value。 - 路径:图中的线展示了模型的“决策旅程”。从基准值(通常为0)开始,随着每个特征的贡献而逐步“行走”。
- 终点:线条最右侧的终点就是模型对该样本的最终预测值
f(x) 对于多分类,观察多条线的整体走向后,通过线束分离、比较决策逻辑、异常样本等,得到进一步的信息。
shap.decision_plot(explainer.expected_value[0], # 期望值,即模型的基线预测值
shap_values[:, :, 0][:20], # 前20个样本的SHAP值
X_test.iloc[:20,:], # 取前20个样本的特征值
feature_order='hclust', # 特征排序方式,'hclust'表示层次聚类排序
show=False)
plt.title("SHAP Decision Plot")
plt.show()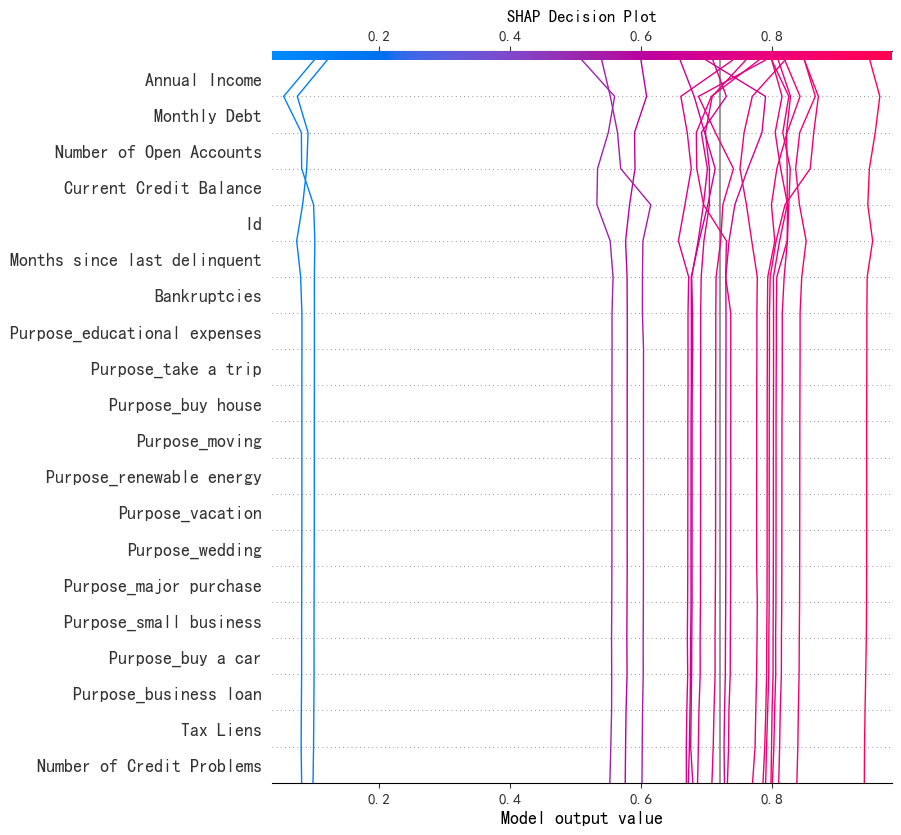
waterfall 瀑布图
瀑布图以阶梯式的方式,一步步展示每个特征如何将模型的预测值从基准值(所有训练样本预测的平均值)推动到最终的预测值,不适合多样本比较。
瀑布图的解读(自下而上):
- 起点:基准值,最底层
- 特征贡献:逐步演变,一系列增加(正向贡献)和减少(负向贡献)
- 终点:最终预测
#绘制瀑布图
shap_values_sample = explainer(X.iloc[:100]) #取前100个样本,减少用时
shap.plots.waterfall(shap_values_sample[5, :, 0]) #查看第5个样本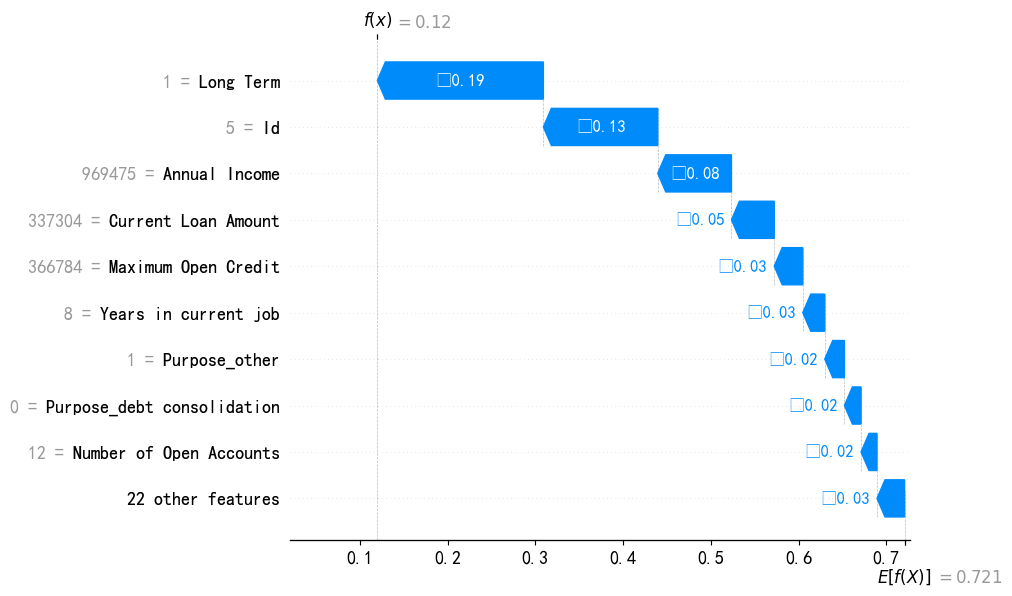
参数的尺寸要求
| 绘图函数 | base_value | shap_values | features | 输出范围 |
|---|---|---|---|---|
|
| 标量 | 1D | 1D | 单个预测 |
|
| 标量 | 2D | 2D | 多个预测 |
|
| (在Explanation内) | Explanation对象 | (在Explanation内) | 单个预测 |
|
| 标量 / 1D | 2D | 2D | 多个预测 |
|
| (可选) | 2D | 2D | 全局视图 |

















 1538
1538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









