 SHAP图绘制与维度分析
SHAP图绘制与维度分析





- 参考上述文档补全剩余的几个图
- 尝试确定一下shap各个绘图函数对于每一个参数的尺寸要求,如shap.force_plot力图中的数据需要满足什么形状?
- 确定分类问题和回归问题的数据如何才能满足尺寸,分类采取信贷数据集,回归采取单车数据集。
SHAP (SHapley Additive exPlanations) 的核心原理基于 博弈论中的Shapley值 ,用于公平分配每个特征对模型预测的贡献。
1. 理论基础:Shapley值
Shapley值原本是解决合作博弈问题的数学工具,用于确定每个参与者对最终结果的贡献。在机器学习中:
- 模型预测看作"总收益"
- 每个特征看作"参与者"
- Shapley值量化每个特征对预测结果的"贡献度"
2. 核心思想
SHAP通过计算 所有可能特征子集的边际贡献 来确定单个特征的重要性:
- 考虑特征的所有可能组合(子集)
- 计算加入某特征后预测结果的变化(边际贡献)
- 对所有组合的边际贡献进行加权平均,得到该特征的SHAP值
3. 关键特性
- 公平性 :每个特征的贡献基于所有可能的特征组合计算,确保无偏
- 一致性 :若模型对某特征的依赖增强,其SHAP值也会单调增加
- 加和性 :对于线性模型,SHAP值之和等于模型预测与基准值的差值
4. 实现方式
SHAP针对不同模型类型优化计算效率:
- TreeExplainer :利用树模型结构特性快速计算(适用于随机森林、XGBoost等)
- LinearExplainer :直接利用线性模型系数和特征协方差计算
- KernelExplainer :通过核函数近似计算,适用于任何模型
- DeepExplainer :结合深度学习模型的梯度信息计算
简单来说,SHAP通过数学严谨的方式,将模型的复杂决策过程拆解为每个特征的独立贡献,帮助我们"打开黑盒",理解模型为什么做出某个预测。
做的是事后解释
shap的维度要求需要特别注意:
针对分类问题: shap_values.shape=(n_samples,n_features,n_classes)样本数,特征数,类别数
针对回归问题: shap_values.shape=(n_samples,n_features)
shap_values行代表一个样本,列代表一个特征,值代表特征对预测结果的影响,正值为正面影响,负值为负面影响。
常见的11种图
1. 摘要图(Summary Plot):展示每个特征对模型输出的影响分布。
2. 力图(Force Plot):展示单个样本的预测结果及其特征贡献。
3. 依赖图(Dependence Plot):展示一个特征与SHAP值之间的关系。
4. 决策图(Decision Plot):展示模型决策路径和特征贡献累积。
5. 交互图(Interaction Plot):展示两个特征之间的交互作用对SHAP值的影响。
6. 蜂群图(Swarm Plot):类似摘要图,但以点的形式展示每个样本的特征值和SHAP值。
7. 热图(Heatmap):展示多个样本的特征SHAP值的热力分布。
8. 小提琴图(Violin Plot):在摘要图中使用小提琴形状展示分布。
9. 条形图(Bar Plot):展示特征的平均绝对SHAP值,即特征重要性。
10. waterfall图:展示单个样本的特征贡献分解,从基准值到预测值的过程。
11. 密度散点图(Density Scatter Plot):结合密度估计的散点图,展示特征值与SHAP值的关系。
今天的生成图的过程出现了一些奇怪的问题,示例的随机森林和我在心脏病里使用的逻辑回归有一些区别,明日再研究研究什么情况,图乱飞。
工厂女工明天一定补上。。。加油小饼干
给大家欣赏一下我的奇怪图吧
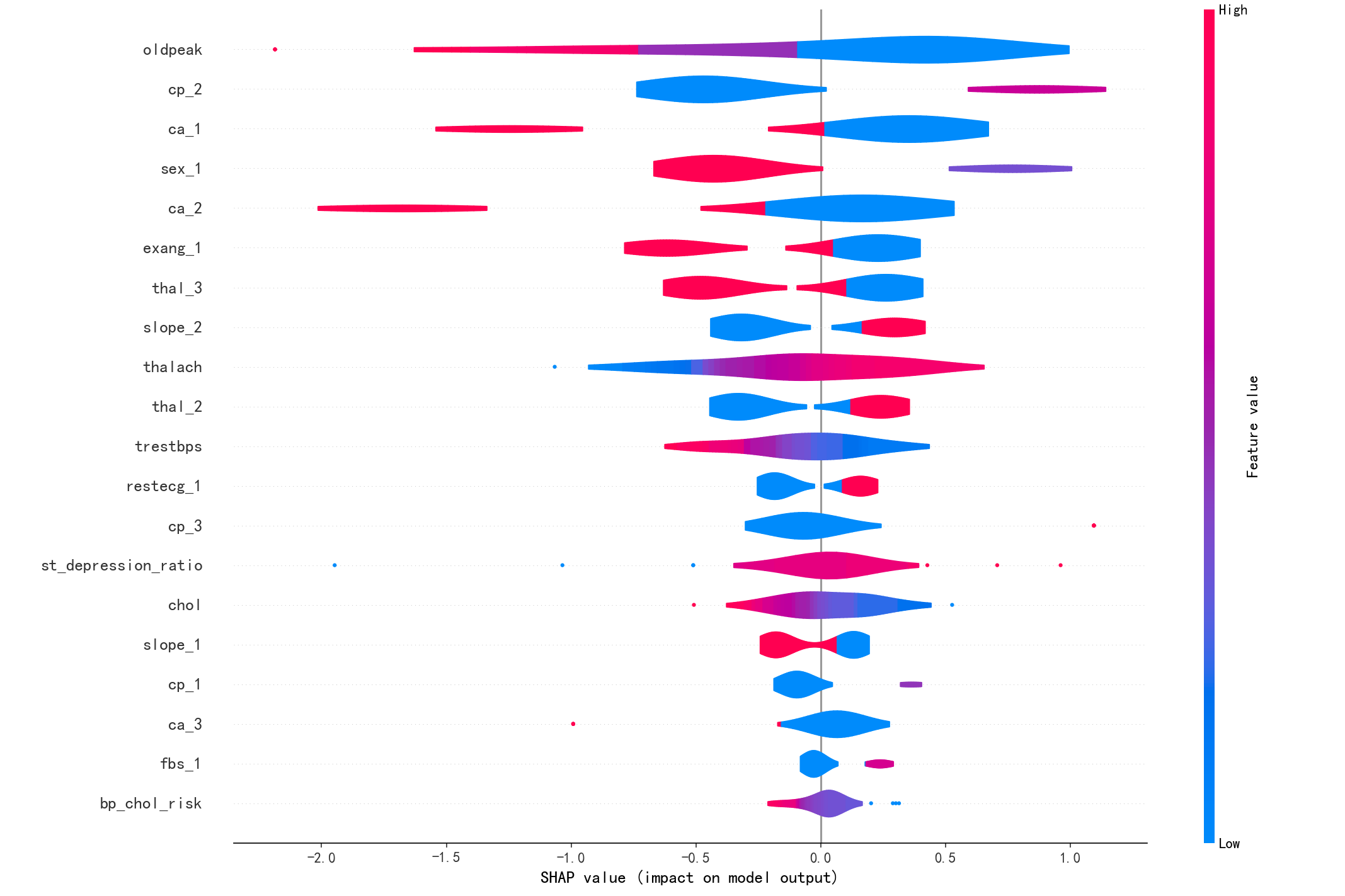
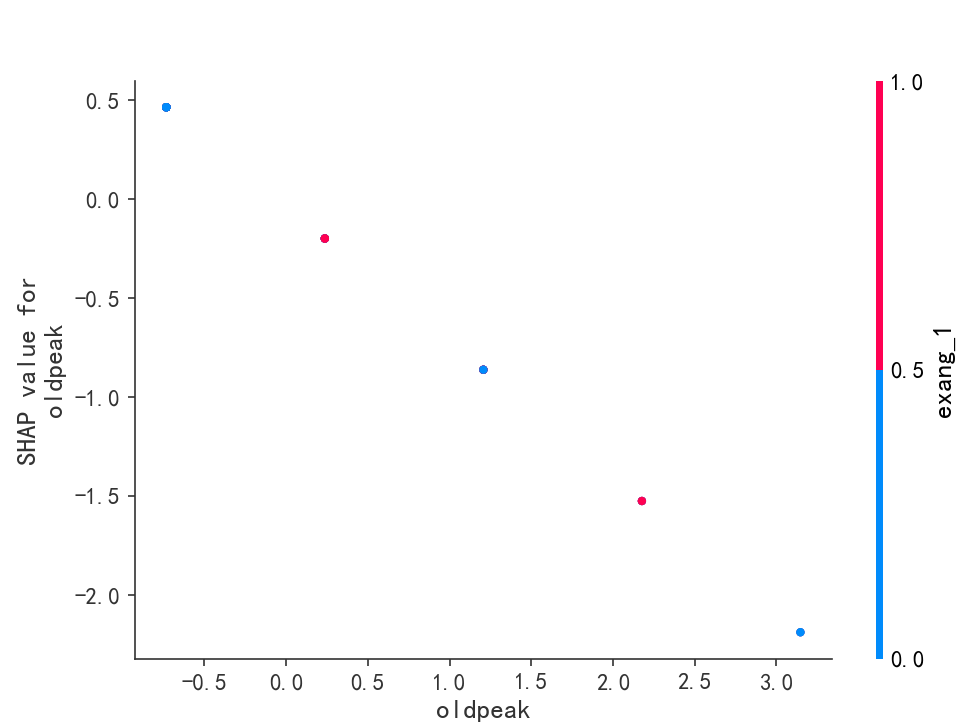

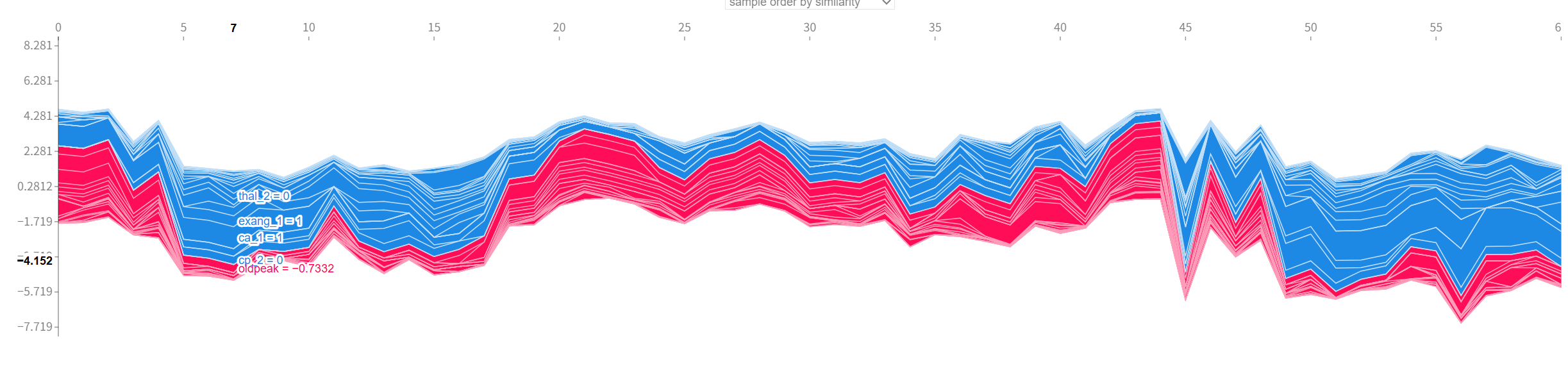
失踪系列,
我得去拜读一下之前的项目代码,ok,今天就先到这里吧

















 2500
2500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









