




今日任务:
- 读取数据
- 找到所有离散特征
- 选择一个离散特征进行独热编码
- 采取循环对所有离散特征进行独热编码
- 处理所有缺失值(回顾day4)
读取数据
#读取数据,查看基本信息
import pandas as pd
data = pd.read_csv(r"D:\机器学习\Python训练营代码【2025.7.30版本】\data.csv")
data.info()离散特征的识别
特征分为连续特征与离散特征,以下为区别:
- 连续特征(Continuous):取值为无限的、不可数的,可在某个区间取任意值。在pandas中的数据类型常为int64、float64等数值类型。
- 离散特征(Discrete):取值是有限的、可数的,包括分类数据(无序)、有序数据。在pandas中的数据类型通常是object 或category。
- 但是通过数据类型不是绝对的判断标准,需要根据具体情况进行分析
在信贷数据集中识别离散特征,采用的方法与day 4中处理缺失值类似——遍历列名,判断列的数据类型。
#离散特征的识别
discrete_features = [] #创建空列表存放离散特征
for column in data.columns: #遍历列名
if data[column].dtype == 'object': #判断
discrete_features.append(column) #添加
print(discrete_features)找到离散特征后,可使用value_counts()方法对某列的离散变量分布情况有一定了解,具体来说该方法会,返回该列中每个唯一值及其对应的出现次数,按频数降序(默认)排列。参数如下:
- ascending:False为降序(默认),True为升序
- dropna:True为排除NaN(默认),False为包含NaN
- normalize:显示相对频率(百分比)
data[discrete_features[0]].value_counts(ascending=True)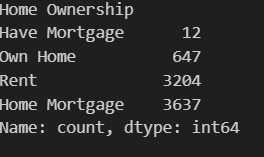
独热编码One-Hot(单列)
对于无序的离散特征且类别数量较少时,一般采用独热编码进行处理,它会将分类变量转换为二进制向量。而对于有序变量,一般采用标签编码。
进行独热编码时,使用pandas中的get_dummies()函数,具体步骤如下:
- 离散变量识别,编码方法选择
- 编码:get_dummies()。主要参数有:data(指定数据,必选);columns(指定编码列,列表形式;若data为Series形式则不选);drop_first(是否删除第一个类别,默认False)
- 新特征名寻找:为类型转换步骤作铺垫。由于独热编码后会根据分类变量将原列进行拆分,即增加新的特征名。可通过对比编码前后的列名,找到新特征名。
- 类型转换:astype()。由于编码后的值为bool型,不方便后续处理,故而使用astype()方法进行转换为数值型int。
#单列离散特征独热编码
df = pd.get_dummies(data,columns=[discrete_features[1]]) #某列编码
df.columns #查看列
df.dtypes #查看类型#寻找新特征名
new_features = []
for i in df.columns:
if i not in data.columns:
new_features.append(i)
print(new_features)
# df.columns.difference(data.columns)
#类型转换
for j in new_features:
df[j] = df[j].astype(int) #返回新列
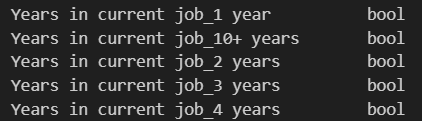
df.dtypes转换前新列均为bool型:
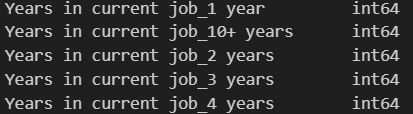
转换后,为int64:
注:找新特征名时,可选择嵌套语句实现,也可使用data.columns.difference(other:要排除的列名列表或数组,sort=True)可实现,返回当前列名中不在 other 参数中的列名,即计算差集。
所有离散特征进行编码(多列循环)
此处处理方法与Day 4缺失值处理方法基本类似。
由于get_dummies方法中columns参数接受的是list形式,因此采用for循环将离散特征提取至list中,然后直接独热编码、类型转换即可。
#离散特征的识别
discrete_features = []
for column in data.columns:
if data[column].dtype == 'object':
discrete_features.append(column)
print(discrete_features)
#多列循环处理
df = pd.get_dummies(data,columns=discrete_features,drop_first=True) #去除第一个类别列,减少维度
df.columns
new_features = df.columns.difference(data.columns) #新列寻找
for j in new_features:
df[j] = df[j].astype(int) #类型转换,返回新列
df.dtypes #检查缺失值处理
此处回顾Day 4处理缺失值的步骤:
- 找存在缺失值的列
- 计算均值(均值填充为例)
- fillna()填充
- 检查
#缺失值处理
df.isnull().sum() #查看整体情况
#使用均值处理
for column in df.columns.tolist():
if df[column].isnull().sum() > 0:
mean_filled = df[column].mean() #计算
df[column] = df[column].fillna(mean_filled) #填充
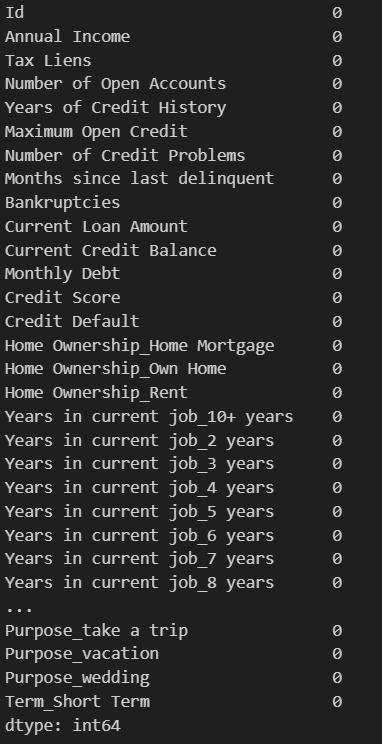
df.isnull().sum() #检查最终经过独热编码和缺失值处理的结果如下:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









