




注:本文主要参考自https://blog.youkuaiyun.com/chaishen10000/article/details/128319250。
1 引子
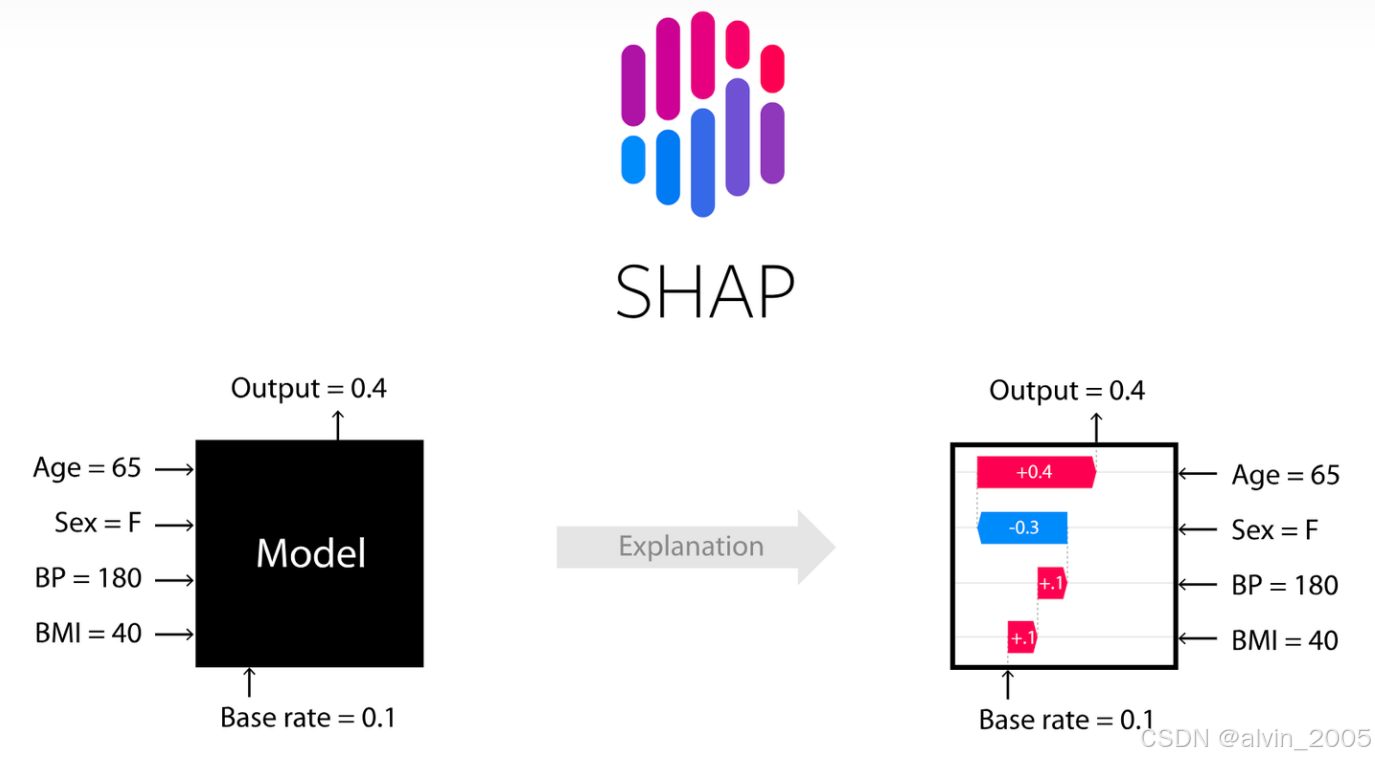
图1 SHAP概念图
通常情况下,我们都会把机器学习模型看作一个黑盒。比如某个模型要进行一些预测任务,首先对模型输入一些已知条件(Age=65,Sex=F,BP=180,BMI=40),然后模型根据输入进行训练,最终训练完的模型可以对该条件输出预测结果(Output=0.4)。
我们所能作的只是通过输入数据,然后得到最终的结果,至于模型内部是怎么计算的,输入的已知条件(Age=65,Sex=F,BP=180,BMI=40)是怎么对预测结果(Output=0.4)影响的,都没法知道。
而SHAP模型就可以让我们知道这些已知条件到底对最终预测结果起到哪些影响(这种影响可能是正向的,也可能是负向的)。当然,除了SHAP模型,其实也有其他方法可以进行特征重要性的计算,如下表所示。我们可以根据各种方法的优点选择适合的进行特征重要性计算。
表1 常用的模型解释方法
| 方法 | 原理 | 优点 | 缺点 | 适用范围 | 库 |
|---|---|---|---|---|---|
| Mean Decrease Inourity |
一个特征的重要性等于特征形成的分支节点的不纯度下降之和 | 1.计算效率高,对大规模数据有利 | 计算整体特征重要性 | 计算整体特征重要性 | RandomForest.XGBoost.GBM默认的特征重要性计算方法 |
| Permutation Inportance |
一个特征的重要性等于把这个特征变成随机数之后,整个模型因此造成的精确性下降程度。 | 1.面对类别很多的分类变量不会产生明显的bias 2.比Drop Column Importance计算效率高 |
1.会受到多重共线性的影响 2.比Mean Drease Impurity计算效率低 3.不能处理有缺失值的数据 |
计算整体特征重要性 | Eli5、rfpimp |
| Drop Column Importance |
一个特征的重要性等于去除这个特征的新模型的accuracy/R^2与原模型的差值 | 比Permutatin Importance的测算精度高 | 1.计算效率特别差,很消耗资源 2.对多重共线性的敏感度高3.只能用在随机森林模型上 |
计算整体特征重要性 | rfpimo |
| Shapley value |
一个特征的shapleyvalue是该特征在所有的特征序列中的平均边际贡献 | 1.解决了多重共线性问题 2.不仅考虑单个变量的影响而且考虑变量组的影响,变量之间可能存在协同效应 |
计算效率低 | 1.计算个体的特征Shapley value 2.所有个体的每个特征的Shapley value的绝对值求和或求平均即为整体的特征重要性 |
SHAP |
2 SHAP
本文主要介绍的SHAP属于模型事后解释的方法,它的核心思想是通过计算特征对模型输出的边际贡献,从全局和局部两个层面对“黑盒模型”进行解释。SHAP构建一个加性的解释模型,即:所有的特征都视为“贡献者”。
SHAP的全称是SHapley Additive exPlanation,SHAP是由Shapley value启发的可加性解释模型。而Shapley value起源于合作博弈论,那什么是合作博弈呢?举例说明:甲乙丙丁四个工人一起打工,甲和乙完成了价值100元的工件,甲、乙、丙完成了价值120元的工件,乙、丙、丁完成了价值150元的工件,甲、丁完成了价值90元的工件,那么该如何公平、合理地分配这四个人的工钱呢?Shapley提出了一个合理的计算方法,我们称每个参与者分配到的数额为Shapley value。
结合文章一开始提到的预测任务,就是已知条件(Age=65,Sex=F,BP=180,BMI=40)一起完成了预测结果(Output=0.4),那么该如何公平、合理地分配这四个已知条件对预测结果的贡献呢?此时SHAP模型就会给这四个已知条件都分配一个Shapley value值,根据这个值我们就可以很好的进行理解。
SHAP可以具体解决的任务
-
调试模型用
-
指导工程师做特征工程
-
指导数据采集的方向
-
指导人们做决策
-
建立模型和人之间的信任
SHAP库可用的explainers
在SHAP中进行模型解释需要先创建一个explainer,SHAP支持很多类型的explainer。
- deep:用于计算深度学习模型,基于DeepLIFT算法,支持TensorFlow / Keras。
- gradient:用于深度学习模型,综合了SHAP、集成梯度、和SmoothGrad等思想,形成单一期望值方程,但速度比DeepExplainer慢,并且做出了不同的假设。 此方法基于Integrated Gradient归因方法,并支持TensorFlow / Keras / PyTorch。
- kernel:模型无关,适用于任何模型
- linear:适用于特征独立不相关的线性模型
- tree:适用于树模型和基于树模型的集成算法,如XGBoost,LightGBM或CatBoost
3 实验
在网上找了几个相关的实验跑一下加深印象,SHAP模型输出的可视化图真的是挺美观的。如图2-3所示,红色特征使预测值更大(类似正相关),蓝色使预测值变小,紫色邻近均值。而颜色区域宽度越大,说明该特征的影响越大。
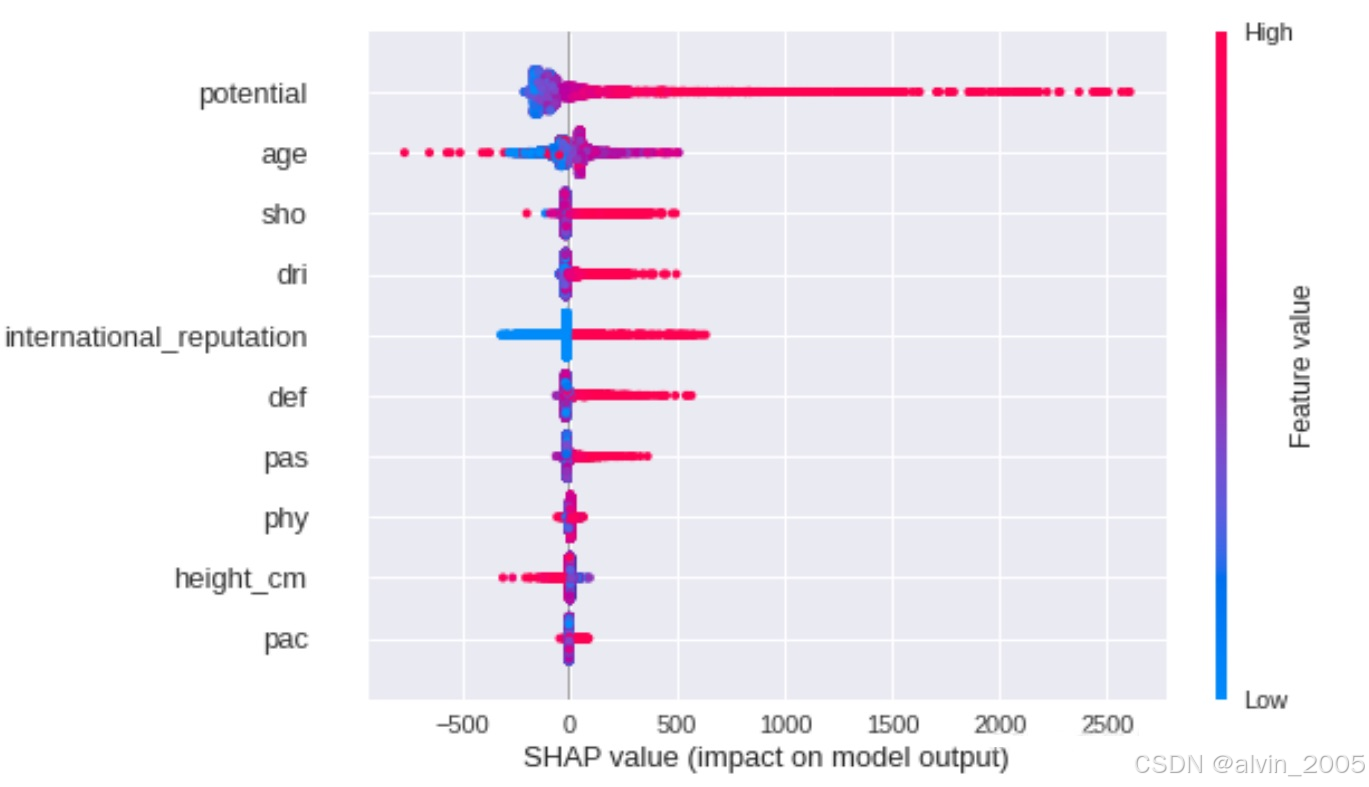
图2 蜂群图(Beesworm Plot)
 图3 使用力图(Force Plot)
图3 使用力图(Force Plot)
下图总结了用于解释任何机器学习模型的11种shap可视化图形:
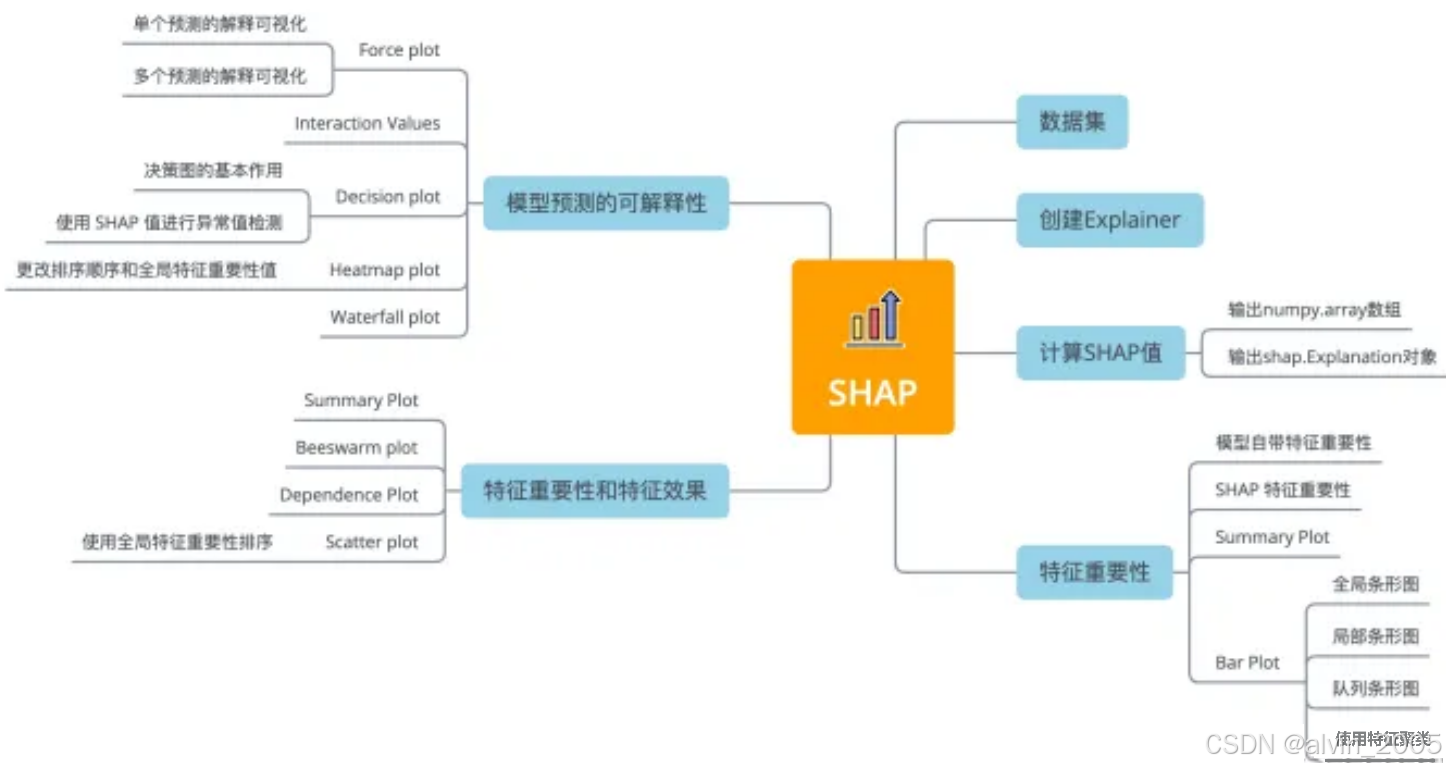
图4 shap可视化图形
数据集
使用标准的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









