




今日任务:
- 不平衡数据集的处理策略:过采样、修改权重、修改阈值
- 交叉验证代码
- 尝试改进训练效果:组合策略;超参数调整等
一、不平衡数据问题
大多数机器学习算法默认假设数据是平衡的,并追求总体准确率。对于分类问题,可能存在标签分类不均匀的问题。如果不进行处理,可能会出现预测结果偏向多数类,而忽略少数类,导致评估失真。因此对于这类不平衡数据的处理显得十分必要。
首先,对信贷数据集进行预处理操作(标签编码、独热编码、缺失值补全,可回顾Day10内容),完成后进行数据集的划分:
from sklearn.model_selection import train_test_split
X = data.drop(['Credit Default'], axis=1) # 特征,axis=1表示按列删除
y = data['Credit Default'] # 标签
# 按照8:2划分训练集和测试集,调参函数自带交叉验证,故只划分一次
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 80%训练集,20%测试集通过对标签的分布进行查看后,发现违约:不违约 = 1:2.5,分布较为不平衡:
data['Credit Default'].value_counts()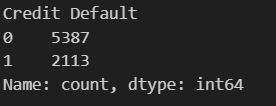
二、处理方法
对于不平衡数据的处理方法,主要分为数据层面和算法层面。
- 数据层面:改变训练数据的分布来平衡数据集。常见的方法有欠采样、过采样。
- 算法层面:不改变数据本身,而是通过调整算法或其目标来适应不平衡性。常用的方法有修改类别权重与调整分类阈值。
2.1 数据层面
主要包括过采样与欠采样。欠采样(多的减少到少的数量)的核心思想是从多数类中随机移除一部分样本,使其数量与少数类接近。而过采样(少的增加到多的数量)则是随机复制少数类样本,增加其数量,但容易过拟合。
一般情况是缺数据,因而欠采样用得不多。下面主要学习过采样的两种方法:随机过采样和smote过采样。
2.1.1 随机过采样ROS
ROS是通过随机复制原始训练集中的少数类样本来增加其数量,从而达到平衡数据集的目的。
它的主要步骤如下:
- 识别类别:确定少数类与多数类
- 确定少数类的目标样本数量
- 从少数类中有放回地随机抽取样本,并复制
- 将复制的样本添加到训练集
ROS的优点是简单易实现,通过增加少数类的样本数从而提高模型的泛化能力。而它的缺点是没有提供信息,过拟合风险高。
ROS的实现可以调用imblearn库中的RandomOverSampler:
#ROS过采样
from imblearn.over_sampling import RandomOverSampler
ros = RandomOverSampler(random_state=42) #实例化
X_ros,y_ros = ros.fit_resample(X_train,y_train) #训练2.1.2 Smote过采样
SMOTE((Synthetic Minority Over-sampling Technique)是通过在已有的少数类样本之间进行线性插值来合成新的少数类样本。
它的主要步骤如下:
- 对于少数类中的每个样本,计算它与少数类中其他样本的距离,得到其k近邻(一般k取5或其他合适的值)。(某样本:A(1,2))
- 从k近邻中随机选择一个样本。(B(5,6))
- 计算选定的近邻样本与原始样本之间的差值。(差值=(4,4))
- 生成一个在0到1之间的随机数。(假设为0.5,[0,1]的范围保证在线段AB上随机取点)
- 将差值乘以随机数,然后加到原始样本上,得到一个新的合成样本。(new=(1+0.5*4,2+0.5*4)= (3,4))
- 重复上述步骤,直到合成出足够数量的少数类样本,使得少数类和多数类样本数量达到某种平衡。
- 使用过采样后的数据集训练模型并评估模型性能。
SMOTE的优点是能有效增加少数类多样性,缓解过拟合风险。缺点是可能生成“嘈杂”的样本,特别是在类别重叠的区域,因为它没有考虑邻近的多数类样本。
SMOTE的实现可以调用imblearn库中的SMOTE:
#SMOTE过采样
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_smote,y_smote = smote.fit_resample(X_train,y_train)
2.2 算法层面
对于不平衡问题的处理,不能盲目相信准确率(模型可能‘偷懒’,若数据集中95%是A类,5%是B类,那么模型只要把所有样本都预测成A类,就能获得95%的准确率。),可以通过调整算法本身(权重或阈值) 来迫使模型去关心我们真正在意的少数类,并使用(如F1、AUC-PR)来衡量成功与否。
2.2.1 修改类别权重(Cost-Sensitive Learning)
模型训练时使用,旨在训练一个更好的模型。该方法的核心思想是为不同类别的错误分类分配不同的“代价”或“权重”。通常,将少数类样本错分为多数类的代价设置得远高于反过来的情况。比如,将病人误判为建康人的代价(100),远高于将健康人误判为病人(代价为1)。在这样的情形下,学习算法在优化参数时会更加关注少数类,找到一个能更好区分少数类的决策边界。
这个方法的作用机制是修改模型的损失函数。当模型错误分类一个具有高权重的少数类样本时,会受到更大的惩罚(更高的损失值)。
比如在RandomForestClassifier中通过对class_weight的设定来根本性调整、实现代价敏感学习,从而得到泛化能力更强的模型:
- None:默认值,所有类别的权重均相同,在不平衡数据中偏向多数类
- balanced:自动根据标签中各类别的频率调整权重(weight = n_samples / (n_classes * np.bincount(y))),可以放大少数类的重要性
- {dict}:手动为每个类别定义权重
2.2.2 调整分类阈值
在完成模型训练后使用,旨在已有的模型上调整表现。核心思想是改变将模型输出的概率(或得分)映射到最终类别标签的门槛。
它的作用机制是,模型通常输出一个样本属于正类(通常设为少数类)的概率 p。默认情况下,如果 p > 0.5,则预测为正类。修改阈值意味着改变这个 0.5,例如,如果要求更高的召回率(但可能牺牲精确率),可以将阈值降低(如 p > 0.3 就预测为正类)。
该方法的优点是由于通过调整阈值来调整分类结果,不需要重新训练模型,适合任何输出概率或分数的模型。缺点就是只改变如何解释模型的输出,若模型本身没有学习好区分少数类,单纯降低阈值反而效果不好(治标不治本)。
三、交叉验证
交叉验证是一种统计方法,用于评估机器学习模型在未知数据上的泛化能力。基本思想是将数据集多次分割为训练集和验证集,从而获得更可靠的性能估计。
常见的交叉验证方法有:标准K折交叉验证和分层K折交叉验证(不平衡数据)。
#定义带权重的模型
rf_weighted_model = RandomForestClassifier(random_state=42,class_weight='balanced') # 自动根据类别频率调整权重
#交叉验证策略,使用 StratifiedKFold 保证每折类别比例相似
cv_strategy = StratifiedKFold(n_splits=5,shuffle=True,random_state=42)
#自定义用于交叉验证的评估指标,make_scorer(): 将指标函数转换为交叉验证可用的评分器
#特别关注少数类的指标,使用 make_scorer 指定 pos_label
scoring = {
'accuracy':'accuracy',
'precision':make_scorer(precision_score,pos_label=minor_label,zero_division=0),
'recall':make_scorer(recall_score,pos_label=minor_label),
'f1_score':make_scorer(f1_score,pos_label=minor_label)
}
#交叉验证,cross_validate 会自动完成训练和评估过程
cv_results = cross_validate(
estimator=rf_weighted_model,
X=X_weighted_smote,
y=y_weighted_smote,
cv=cv_strategy,
scoring=scoring,
n_jobs=-1,
return_train_score=False,#不返回训练折的得分
) #返回字典形式
# 打印交叉验证结果的平均值
print("\n带权重随机森林 交叉验证平均性能 (基于训练集划分):")
for metric_name, scores in cv_results.items():
if metric_name.startswith('test_'): # 我们关心的是在验证折上的表现
# 提取指标名称(去掉 'test_' 前缀)
clean_metric_name = metric_name.split('test_')[1]
print(f" 平均 {clean_metric_name}: {np.mean(scores):.4f} (+/- {np.std(scores):.4f})")四、作业:改进训练效果
那么,对于上述的不平衡数据处理方法,在实际中,应该如何选择?
- 评价指标:使用适合不平衡数据的指标(Recall, F1-Score, AUC-PR, Balanced Accuracy, MCC)来评估模型。
- 根本方法优先(源头):修改权重class_weight或者数据采样
- 交叉验证评估:在使用 class_weight`或采样方法时,务必使用分层交叉验证 (Stratified K-Fold,适合不平衡数据)来获得对模型性能的可靠估计
- 阈值调整作为补充:作为微调手段
- 组合策略:smote + class_weight + 阈值调整
使用SMOTE+ROS+权重调整后,发现相较于单纯使用权重方法处理,这种组合策略提升了召回率(0.29到0.35),但是精确率显著下降(0.79到0.64)。单一的权重调整方法增加了准确率(由0.79到0.81),召回率下降(0.29到0.27)。
#权重调整+SMOTE+ROS
from sklearn.model_selection import StratifiedKFold,cross_validate
from sklearn.metrics import make_scorer, accuracy_score, precision_score, recall_score, f1_score, confusion_matrix, classification_report
from imblearn.over_sampling import SMOTE,RandomOverSampler
#确定少数列标签
counts = np.bincount(y_train) #返回一个数组,索引代表类别标签,值代表出现次数
minor_label = np.argmin(counts) # 找到计数最少的类别的标签
max_label = np.argmax(counts)
#SMOTE采样
smote_weighted = SMOTE(random_state=42,sampling_strategy=0.8) #80%SMOTE
X_smoted,y_smoted = smote_weighted.fit_resample(X_train,y_train)
#ROS
ros_weighted = RandomOverSampler(random_state=42)
X_weighted_smote,y_weighted_smote = ros_weighted.fit_resample(X_smoted,y_smoted)
#训练
rf_weighted_model_final = RandomForestClassifier(random_state=42,class_weight='balanced')
rf_weighted_model_final.fit(X_weighted_smote,y_weighted_smote)
rf_weighted_final_pred = rf_weighted_model_final.predict(X_test)
print('模型的分类报告:')
print(classification_report(y_test,rf_weighted_final_pred))
print('模型的混淆矩阵:')
print(confusion_matrix(y_test,rf_weighted_final_pred))
# 对比总结
print("性能对比 (测试集上的少数类召回率 Recall):")
recall_default = recall_score(y_test,rf_pred,pos_label=minor_label)
recall_weighted = recall_score(y_test,rf_weighted_final_pred,pos_label=minor_label)
print(f" 默认模型: {recall_default:.4f}")
print(f" 带权重模型: {recall_weighted:.4f}")默认模型:
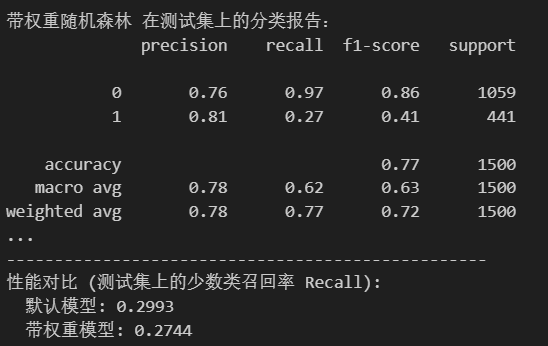
组合策略:
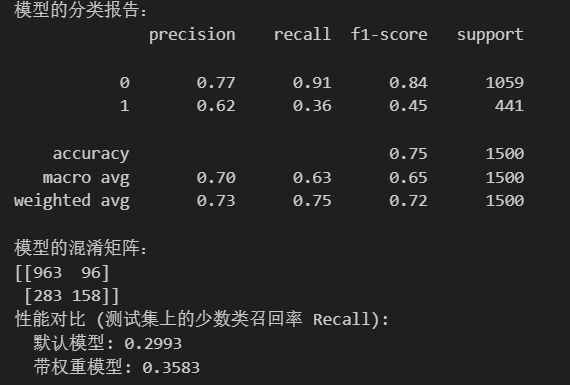

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









