




今日任务:
- GAN的思想:关注损失从何而来
- 生成器、判别器
- nn.sequential 容器:按顺序运算时使用,能简化前向传播写法
- leakyReLU:避免 relu 的神经元失活现象
作业:使用心脏病数据集,不平衡的病人样本用 GAN 学习并生成病人样本,对比使用 GAN 前后的F1-Score 差异。
对抗生成网络的思想
图片来自B站up主 @图通道

造假的人需要提高造假技术,达到以假乱真的水平;而验钞机也需要提高识别假币的能力。造假的人根据验钞机的结果,不断提高造假能力;验钞机根据真币和假币来分辨真假,根据判别结果,提高鉴别能力。这样“造假-鉴定-反馈-改进”的过程反复循环,两者相互对抗,最终达到一个理想的平衡状态。
根据上面的比喻,下面是一些术语:
- 生成器:造假者,将随机的噪声‘生成’为一个假数据——欺骗判别器
- 判别器:验钞机,”判别“接受的数据(真实或造假)的真假——不被生成器欺骗
- 训练数据集:真币
- 对抗训练:互相博弈、共同进步的过程
- 最终目标:让生成器能够生成与真实数据几乎无法区分的高质量数据(学习规律,以假乱真)
对于复杂的架构设计,核心点:损失的来源与定义。对于GAN的损失包括生成器的损失和判别器的损失两个部分:
- 判别器损失:分类问题的损失(输出概率),包括”真实数据判真“和”生成数据判假“
- 生成器损失:依靠判别器的损失,目标是让判别器对生成数据判真
- 两者优化交替进行:先训判别器,再训生成器(它依靠判别器的结果)
核心
数据准备:使用iris数据集
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, TensorDataset
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import warnings
warnings.filterwarnings("ignore")
# 设置中文字体支持
plt.rcParams["font.family"] = ["SimHei"]
plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题
# 检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
LATENT_DIM = 10 # 潜在空间的维度,这里根据任务复杂程度任选
EPOCHS = 10000 # 训练的回合数,一般需要比较长的时间
BATCH_SIZE = 32 # 每批次训练的样本数
LR = 0.0002 # 学习率
BETA1 = 0.5 # Adam优化器的参数
# 检查是否有可用的GPU,否则使用CPU
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"Using device: {device}")
# --- 2. 加载并预处理数据 ---
iris = load_iris()
X = iris.data
y = iris.target
# 只选择 'Setosa' (类别 0)
X_class0 = X[y == 0] # 一种简便写法
# 数据缩放到 [-1, 1]
scaler = MinMaxScaler(feature_range=(-1, 1))
X_scaled = scaler.fit_transform(X_class0)
# 转换为 PyTorch Tensor 并创建 DataLoader
# 注意需要将数据类型转为 float
real_data_tensor = torch.from_numpy(X_scaled).float() # 将numpy数组转换为张量(float)
dataset = TensorDataset(real_data_tensor) # 转换为Pytoch 数据集对象(dataset)
dataloader = DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=True)
print(f"成功加载并预处理数据。用于训练的样本数量: {len(X_scaled)}")
print(f"数据特征维度: {X_scaled.shape[1]}")生成器(Generator)
总体上看,生成器定义与普通的MLP相似,但是存在以下区别:
- 输入通道通常较大:LATENT_DIM=50-100,需要强大表示能力
- 输出激活函数
- 过程:生成器,噪声 → 生成器 → 逼真数据;分类器,数据 → 分类器 → 类别概率
此外,这里使用了nn.sequential容器,它是一个顺序容器,本质上与手动定义连接是等价的。Sequential 有以下特点:
- 按顺序执行:数据从第一层流到最后一层,依次经过每个模块
- 自动前向传播:可作为属性调用,不需要手动定义各层之间的连接
- 简洁清晰:适合线性堆叠(MLP、CNN的主体)的网络结构
- 包含复杂分支时手动编写forward:如残差连接、多分支、条件判断等无法使用该容器
# (A) 生成器 (Generator)
LATENT_DIM = 10 # 潜在空间的维度,这里根据任务复杂程度任选
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
self.model = nn.Sequential(
nn.Linear(LATENT_DIM, 16),
nn.ReLU(),
nn.Linear(16, 32),
nn.ReLU(),
nn.Linear(32, 4),# 最后的维度只要和目标数据对齐即可
nn.Tanh() # 保证输出范围是 [-1, 1]
)
def forward(self, x):
return self.model(x) # 因为没有像之前一样做定义x=某些东西,所以现在可以直接输出模型判别器(Discriminator)
# (B) 判别器 (Discriminator)
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator, self).__init__()
self.model = nn.Sequential(
nn.Linear(4, 32),
nn.LeakyReLU(0.2), # LeakyReLU 是 GAN 中的常用选择
nn.Linear(32, 16),
nn.LeakyReLU(0.2), # 负斜率参数为0.2
nn.Linear(16, 1), # 这里最后输出1个神经元,所以用sigmoid激活函数
nn.Sigmoid() # 输出 0 到 1 的概率
)
def forward(self, x):
return self.model(x)这里使用了LeakyReLU函数:
# 数学表达式
LeakyReLU(x) = {
x, if x > 0
α * x, if x ≤ 0 # α 一般在0.1 - 0.3
}
# 在PyTorch中的使用
nn.LeakyReLU(negative_slope=0.2)标准的ReLU函数会将负数输出为0,这样会出现大量“神经元死亡”的问题(梯度为0,参数不更新)。而LeakyReLU函数对于负数会保留微小梯度(negative_slope),从而保持负区域的信息流动,防止神经元死亡(确保判别器有足够强的学习能力,避免“败”给生成器)。
关于生成器可以选择ReLU,而判别器必须选择LeakyReLU的原因:
- 生成器的任务相对明确,并且输入分布良好,负激活相对少(梯度依赖判别器的反馈)
- 判别器任务更复杂(两种输入,可能存在生成器的异常输入),LeakyReLU可保持学习能力
- 生成器可以用ReLU或LeakyReLU: ReLU,计算简单,稀疏性可能有益;LeakyReLU,更稳定,现代GAN的默认选择
训练及可视化
训练
训练的逻辑核心:每个epoch,先训练判别器,再训练生成器
- 训练判别器:步骤与之前相同,梯度清零 → 前向传播 → 损失函数 → 反向传播 → 更新参数。包含真实数据和假数据训练两个部分,损失值由两者共同组成。
- 训练生成器:生成fake_data,剩下步骤同上
# 实例化模型并移动到指定设备
generator = Generator().to(device)
discriminator = Discriminator().to(device)
print(generator)
print(discriminator)
# --- 4. 定义损失函数和优化器 ---
criterion = nn.BCELoss() # 二元交叉熵损失
# 分别为生成器和判别器设置优化器
g_optimizer = optim.Adam(generator.parameters(), lr=LR, betas=(BETA1, 0.999))
d_optimizer = optim.Adam(discriminator.parameters(), lr=LR, betas=(BETA1, 0.999))
# --- 5. 执行训练循环 ---
print("\n--- 开始训练 ---")
for epoch in range(EPOCHS):
for i, (real_data,) in enumerate(dataloader):
# 将数据移动到设备
real_data = real_data.to(device)
current_batch_size = real_data.size(0)
# 创建真实和虚假的标签
real_labels = torch.ones(current_batch_size, 1).to(device)
fake_labels = torch.zeros(current_batch_size, 1).to(device)
# ---------------------
# 训练判别器
# ---------------------
d_optimizer.zero_grad() # 梯度清零
# (1) 用真实数据训练
real_output = discriminator(real_data)
d_loss_real = criterion(real_output, real_labels)
# (2) 用假数据训练
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
# 使用 .detach() 防止在训练判别器时梯度流回生成器,这里我们未来再说
fake_data = generator(noise).detach()
fake_output = discriminator(fake_data)
d_loss_fake = criterion(fake_output, fake_labels)
# 总损失并反向传播
d_loss = d_loss_real + d_loss_fake
d_loss.backward()
d_optimizer.step()
# ---------------------
# 训练生成器
# ---------------------
g_optimizer.zero_grad() # 梯度清零
# 生成新的假数据,并尝试"欺骗"判别器
noise = torch.randn(current_batch_size, LATENT_DIM).to(device)
fake_data = generator(noise)
fake_output = discriminator(fake_data)
# 计算生成器的损失,目标是让判别器将假数据误判为真(1)
g_loss = criterion(fake_output, real_labels)
# 反向传播并更新生成器
g_loss.backward()
g_optimizer.step()
# 每 1000 个 epoch 打印一次训练状态
if (epoch + 1) % 1000 == 0:
print(
f"Epoch [{epoch+1}/{EPOCHS}], "
f"Discriminator Loss: {d_loss.item():.4f}, "
f"Generator Loss: {g_loss.item():.4f}"
)
print("--- 训练完成 ---")
可视化
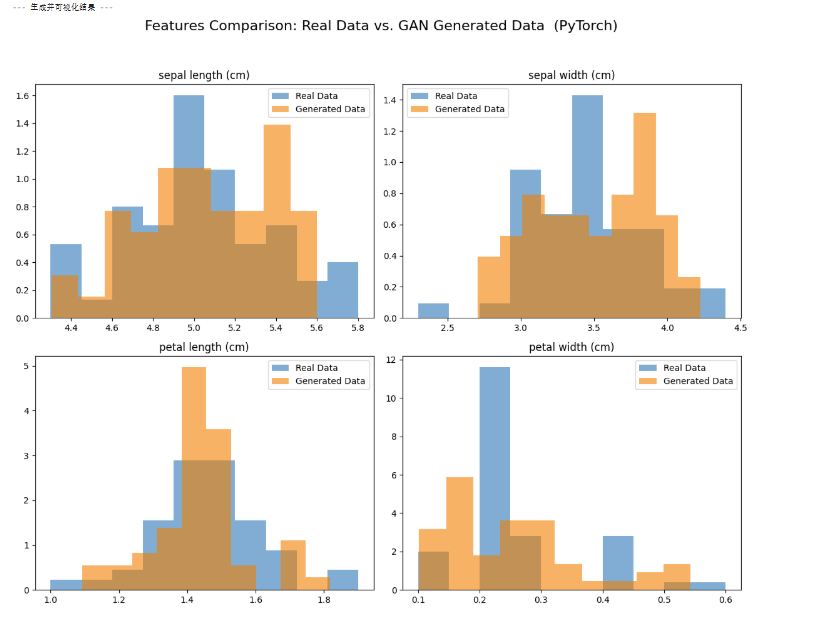
GAN训练效果的关键指标:真实数据和生成器创造的新数据(重叠性),查看生成器是否真的学会了原始数据的分布规律
- 若两者分布高度重叠 → 生成数据质量高,GAN 学得好
- 若分布差异大、峰谷错位明显 → 生成数据存在偏差,GAN 学习不充分
# --- 6. 生成新数据并进行可视化对比 ---
print("\n--- 生成并可视化结果 ---")
# 将生成器设为评估模式
generator.eval()
# 使用 torch.no_grad() 来关闭梯度计算
with torch.no_grad():
num_new_samples = 50
noise = torch.randn(num_new_samples, LATENT_DIM).to(device)
generated_data_scaled = generator(noise)
# 将生成的数据从GPU移到CPU,并转换为numpy数组
generated_data_scaled_np = generated_data_scaled.cpu().numpy()
# 逆向转换回原始尺度
generated_data = scaler.inverse_transform(generated_data_scaled_np)
real_data_original_scale = scaler.inverse_transform(X_scaled)
# 可视化对比
fig, axes = plt.subplots(2, 2, figsize=(12, 10))
fig.suptitle('真实数据 vs. GAN生成数据 的特征分布对比 (PyTorch)', fontsize=16)
feature_names = iris.feature_names
for i, ax in enumerate(axes.flatten()):
ax.hist(real_data_original_scale[:, i], bins=10, density=True, alpha=0.6, label='Real Data')
ax.hist(generated_data[:, i], bins=10, density=True, alpha=0.6, label='Generated Data')
ax.set_title(feature_names[i])
ax.legend()
plt.tight_layout(rect=[0, 0.03, 1, 0.95])
plt.show()
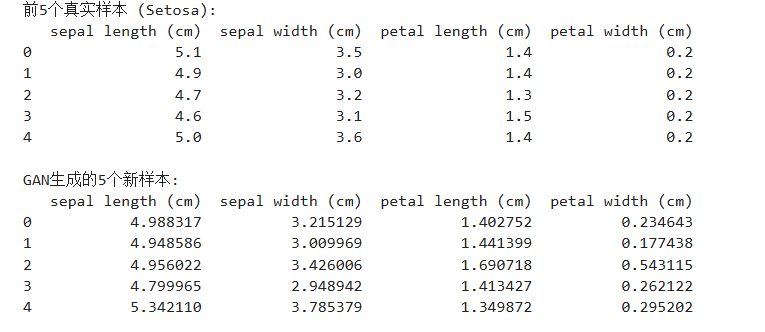
# 将生成的数据与真实数据并排打印出来看看
print("\n前5个真实样本 (Setosa):")
print(pd.DataFrame(real_data_original_scale[:5], columns=feature_names))
print("\nGAN生成的5个新样本:")
print(pd.DataFrame(generated_data[:5], columns=feature_names))整体区间基本重叠,但是高度还存在一定差异
作业
使用心脏病数据集,不平衡的病人样本用 GAN 学习并生成病人样本,对比使用 GAN 前后的F1-Score 差异。

















 730
730

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









