




使用vgg16模型+CBAM,同时采用阶段式训练。
注:相较于resnet18,vgg16的结构、参数名都不同,需要对之前的代码做一定修改。
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
#import numpy as np
# 0-检查GPU是否可用
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"使用设备: {device}")
# 1-数据预处理(与原代码一致)
train_transform = transforms.Compose([
transforms.RandomCrop(32, padding=4),
transforms.RandomHorizontalFlip(),
transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2, hue=0.1),
transforms.RandomRotation(15),
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
test_transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))
])
# 2-加载数据集(与原代码一致)
train_dataset = datasets.CIFAR10(root='./data', train=True, download=True, transform=train_transform)
test_dataset = datasets.CIFAR10(root='./data', train=False, transform=test_transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
# 3-定义通道注意力
class ChannelAttention(nn.Module):
def __init__(self, in_channels, ratio=16):
"""
通道注意力机制初始化
参数:
in_channels: 输入特征图的通道数
ratio: 降维比例,用于减少参数量,默认为16
"""
super().__init__()
# 全局平均池化,将每个通道的特征图压缩为1x1,保留通道间的平均值信息
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化,将每个通道的特征图压缩为1x1,保留通道间的最显著特征
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享全连接层,用于学习通道间的关系
# 先降维(除以ratio),再通过ReLU激活,最后升维回原始通道数
self.fc = nn.Sequential(
nn.Linear(in_channels, in_channels // ratio, bias=False), # 降维层
nn.ReLU(), # 非线性激活函数
nn.Linear(in_channels // ratio, in_channels, bias=False) # 升维层
)
# Sigmoid函数将输出映射到0-1之间,作为各通道的权重
self.sigmoid = nn.Sigmoid()
def forward(self, x):
"""
前向传播函数
参数:
x: 输入特征图,形状为 [batch_size, channels, height, width]
返回:
调整后的特征图,通道权重已应用
"""
# 获取输入特征图的维度信息,这是一种元组的解包写法
b, c, h, w = x.shape
# 对平均池化结果进行处理:展平后通过全连接网络
avg_out = self.fc(self.avg_pool(x).view(b, c))
# 对最大池化结果进行处理:展平后通过全连接网络
max_out = self.fc(self.max_pool(x).view(b, c))
# 将平均池化和最大池化的结果相加并通过sigmoid函数得到通道权重
attention = self.sigmoid(avg_out + max_out).view(b, c, 1, 1)
# 将注意力权重与原始特征相乘,增强重要通道,抑制不重要通道
return x * attention #这个运算是pytorch的广播机制
## 3-空间注意力模块
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
self.conv = nn.Conv2d(2, 1, kernel_size, padding=kernel_size//2, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 通道维度池化
avg_out = torch.mean(x, dim=1, keepdim=True) # 平均池化:(B,1,H,W)
max_out, _ = torch.max(x, dim=1, keepdim=True) # 最大池化:(B,1,H,W)
pool_out = torch.cat([avg_out, max_out], dim=1) # 拼接:(B,2,H,W)
attention = self.conv(pool_out) # 卷积提取空间特征
return x * self.sigmoid(attention) # 特征与空间权重相乘
## 4-CBAM模块
class CBAM(nn.Module):
def __init__(self, in_channels, ratio=16, kernel_size=7):
super().__init__()
self.channel_attn = ChannelAttention(in_channels, ratio)
self.spatial_attn = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attn(x)
x = self.spatial_attn(x)
return x
# 5-定义Vgg16 + CBAM
from torchvision.models import vgg16
class Vgg16_CBAM(nn.Module):
def __init__(self,num_classes=10,weights=True,ratio=16,kernel_size=7):
super().__init__()
self.backbone = vgg16(weights=weights) # 新版本torchvison使用weights代替pretrained
self.features = self.backbone.features # VGG16的特征提取部分(卷积层)
# VGG16原始首层: 64个3x3卷积, stride=1, padding=1,对于CIFAR-10不需要修改首层,因为VGG16原本就使用3x3卷积
# 五层layer末尾加入CBAM:特征层尺寸变化: 32x32 -> 16x16 -> 8x8 -> 4x4 -> 2x2 -> 1x1
self.cbam_layer1 = CBAM(in_channels=64,ratio=ratio,kernel_size=kernel_size)
self.cbam_layer2 = CBAM(in_channels=128,ratio=ratio,kernel_size=kernel_size)
self.cbam_layer3 = CBAM(in_channels=256,ratio=ratio,kernel_size=kernel_size)
self.cbam_layer4 = CBAM(in_channels=512,ratio=ratio,kernel_size=kernel_size)
self.cbam_layer5 = CBAM(in_channels=512,ratio=ratio,kernel_size=kernel_size)
# 重写分类层,适合cifar的10分类
self.backbone.classifier = nn.Sequential(
nn.Linear(512 * 1 * 1, 512), # VGG16最后特征图尺寸是2x2,但经过自适应池化后变为1x1
nn.ReLU(True),
nn.Dropout(),
nn.Linear(512, 256),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(256, num_classes),
)
# 添加自适应池化来适应不同输入尺寸
self.adaptive_pool = nn.AdaptiveAvgPool2d((1, 1)) # 原始结构输出的是7*7
def forward(self,x):
# VGG16的特征提取流程
# Layer 1: 2个卷积 + ReLU + MaxPool
x = self.features[0:5](x) # 64通道, 16x16
x = self.cbam_layer1(x)
# Layer 2: 2个卷积 + ReLU + MaxPool
x = self.features[5:10](x) # 128通道, 8x8
x = self.cbam_layer2(x)
# Layer 3: 3个卷积 + ReLU + MaxPool
x = self.features[10:17](x) # 256通道, 4x4
x = self.cbam_layer3(x)
# Layer 4: 3个卷积 + ReLU + MaxPool
x = self.features[17:24](x) # 512通道, 2x2
x = self.cbam_layer4(x)
# Layer 5: 3个卷积 + ReLU + MaxPool (VGG16的最后一层)
x = self.features[24:](x) # 512通道, 1x1
x = self.cbam_layer5(x)
# 自适应池化 + 分类
x = self.adaptive_pool(x) # [B, 512, 1, 1]
x = torch.flatten(x, 1)
x = self.backbone.classifier(x)
return x
# 6-三阶段训练 + 差异化学习率
import time
# 6.1-冻结逻辑
def set_trainable_layers(model,train_parts):
for name,param in model.named_parameters():
param.requires_grad = False
for part in train_parts:
if part in name:
param.requires_grad = True
break
# 6.2-训练
def train_staged_finetuning_vgg(model, criterion, train_loader, test_loader, device, epochs):
optimizer = None
# 初始化历史记录列表,与你的要求一致
all_iter_losses, iter_indices = [], []
train_acc_history, test_acc_history = [], []
train_loss_history, test_loss_history = [], []
for epoch in range(1,epochs+1):
epoch_start_time = time.time()
# --------阶段式训练+动态调整学习率-----------------------
if epoch == 1:
print("\n" + "="*50 + "\n **阶段 1:训练注意力模块和分类头**\n" + "="*50)
set_trainable_layers(model,['classifier','cbam'])
# 等价于trainable_params = [p for p in model.parameters() if p.requires_grad],使用解冻的参数
# filter(函数,可迭代对象):遍历对象,应用函数(返回True的对象)
optimizer = optim.Adam(params=filter(lambda p:p.requires_grad,model.parameters()),lr=1e-3)
elif epoch == 6:
print("\n" + "="*50 + "\n **阶段 2:解冻高层卷积层 (features 17-30)**\n" + "="*50)
set_trainable_layers(
model,
['features.17', 'features.18', 'features.19', 'features.20', 'features.21',
'features.22', 'features.23', 'features.24','features.25', 'features.26',
'features.27', 'features.28','features.29', 'features.30', 'classifier', 'cbam']
)
optimizer = optim.Adam(filter(lambda p:p.requires_grad,model.parameters()),lr=1e-4)
elif epoch == 21:
print("\n" + "="*50 + "\n **阶段 3:解冻所有层,进行全局微调**\n" + "="*50)
for name,param in model.named_parameters():
param.requires_grad = True
optimizer = optim.Adam(model.parameters(),lr=1e-5)
# 训练循环
model.train()
running_loss,correct,total = 0.0,0,0 # running_loss一般为浮点数
for batch_idx,(data,target) in enumerate(train_loader):
data,target = data.to(device),target.to(device)
optimizer.zero_grad() # 梯度清零
output = model(data) # 前向传播
loss = criterion(output,target) # 损失计算
loss.backward() # 反向传播
optimizer.step() # 更新参数
# 记录
iter_loss = loss.item()
all_iter_losses.append(iter_loss)
iter_indices.append((epoch-1)*len(train_loader)+batch_idx+1)
# 统计
running_loss += iter_loss
total += target.size(0)
_,predicted = output.max(1)
correct += predicted.eq(target).sum().item()
# 每100个batch打印结果
if (batch_idx + 1) % 100 == 0:
print(f'Epoch: {epoch}/{epochs} | Batch: {batch_idx+1}/{len(train_loader)} '
f'| 单Batch损失: {iter_loss:.4f} | 累计平均损失: {running_loss/(batch_idx+1):.4f}')
# 计算epoch_loss、epoch_acc
epoch_train_loss = running_loss / len(train_loader)
epoch_train_acc = 100. * correct / total
train_loss_history.append(epoch_train_loss)
train_acc_history.append(epoch_train_acc)
# 测试循环
model.eval()
test_losses,test_correct,test_total = 0.0,0,0
with torch.no_grad():
for data,target in test_loader:
data,target = data.to(device),target.to(device)
out = model(data)
test_loss = criterion(out,target)
test_losses += test_loss.item()
test_total += target.size(0)
_,predicted = out.max(1)
test_correct += predicted.eq(target).sum().item()
epoch_test_loss = test_losses / len(test_loader)
epoch_test_acc = 100. * test_correct / test_total
test_loss_history.append(epoch_test_loss)
test_acc_history.append(epoch_test_acc)
# 打印每个epoch的最终结果
print(f'Epoch {epoch}/{epochs} 完成 | 耗时: {time.time() - epoch_start_time:.2f}s | 训练准确率: {epoch_train_acc:.2f}% | 测试准确率: {epoch_test_acc:.2f}%')
# 循环结束,绘图
# 训练结束后调用绘图函数
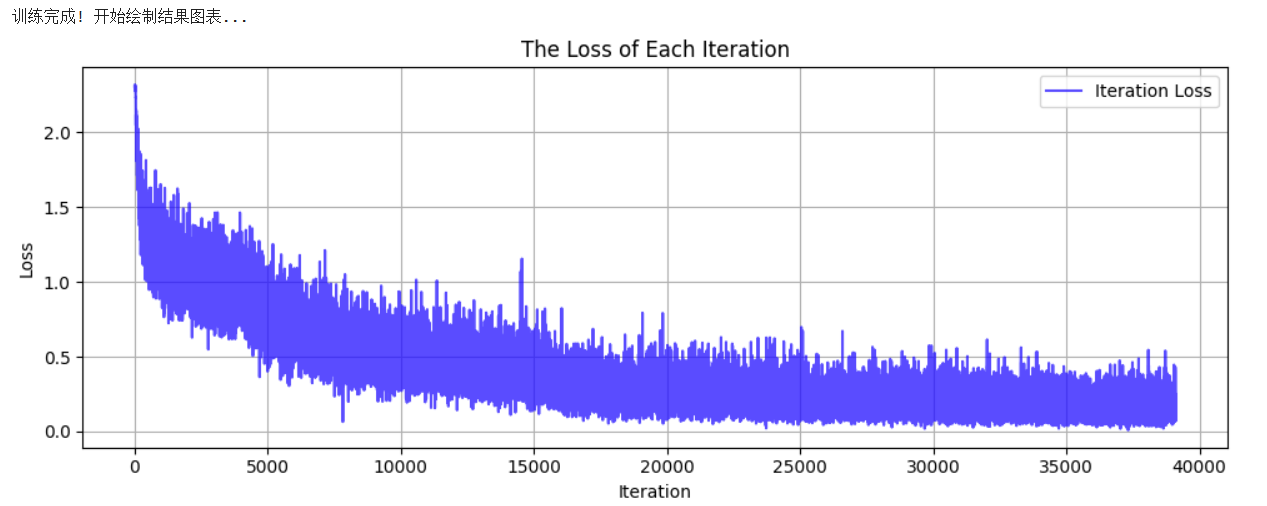
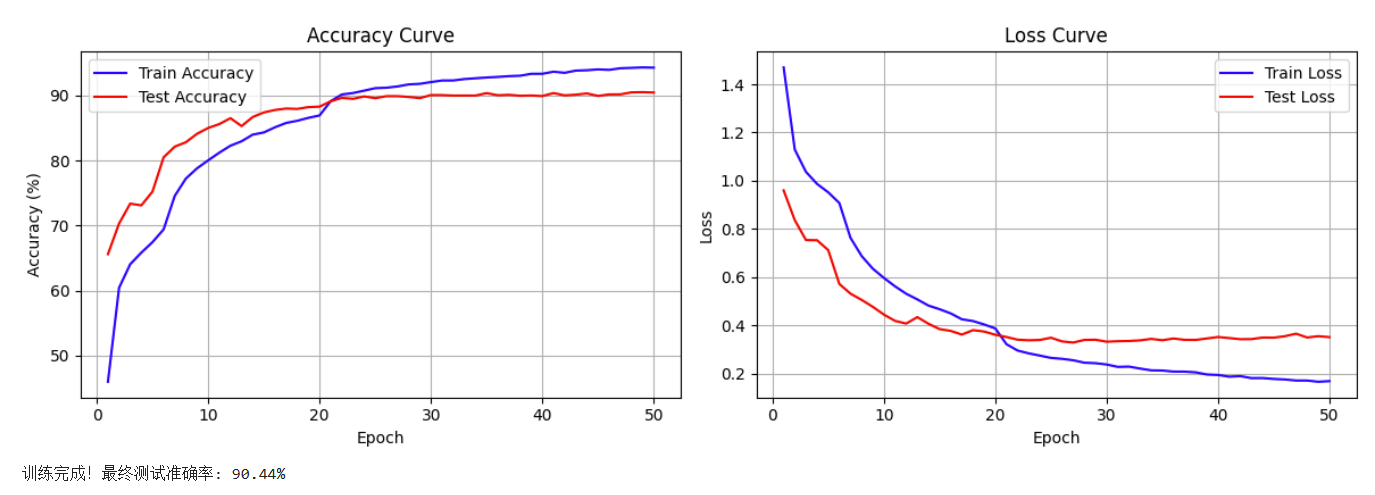
print("\n训练完成! 开始绘制结果图表...")
plot_iter_losses(all_iter_losses, iter_indices)
plot_epoch_metrics(train_acc_history, test_acc_history, train_loss_history, test_loss_history)
# 返回最终的测试准确率
return epoch_test_acc
# 7-绘制每个 iteration 的损失曲线
def plot_iter_losses(losses, indices):
plt.figure(figsize=(10, 4))
plt.plot(indices, losses, 'b-', alpha=0.7, label='Iteration Loss')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.title('The Loss of Each Iteration')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 7-绘制每个 epoch 的准确率和损失曲线
def plot_epoch_metrics(train_acc, test_acc, train_loss, test_loss):
epochs = range(1, len(train_acc) + 1)
plt.figure(figsize=(12, 4))
# 绘制准确率曲线
plt.subplot(1, 2, 1)
plt.plot(epochs, train_acc, 'b-', label='Train Accuracy')
plt.plot(epochs, test_acc, 'r-', label='Test Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy (%)')
plt.title('Accuracy Curve')
plt.legend()
plt.grid(True)
# 绘制损失曲线
plt.subplot(1, 2, 2)
plt.plot(epochs, train_loss, 'b-', label='Train Loss')
plt.plot(epochs, test_loss, 'r-', label='Test Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Loss Curve')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
# 8-执行训练
model = Vgg16_CBAM().to(device)
criterion = nn.CrossEntropyLoss()
epochs = 50
print('开始使用带分阶段微调策略的ResNet18+CBAM模型进行训练...')
final_accuracy = train_staged_finetuning_vgg(model, criterion, train_loader, test_loader, device, epochs)
print(f"训练完成!最终测试准确率: {final_accuracy:.2f}%")
# torch.save(model.state_dict(), 'resnet18_cbam_finetuned.pth')
# print("模型已保存为: resnet18_cbam_finetuned.pth")
开始使用带分阶段微调策略的Vgg16+CBAM模型进行训练...
==================================================
**阶段 1:训练注意力模块和分类头**
==================================================
Epoch: 1/50 | Batch: 100/782 | 单Batch损失: 1.9991 | 累计平均损失: 2.1124
Epoch: 1/50 | Batch: 200/782 | 单Batch损失: 1.5551 | 累计平均损失: 1.9010
Epoch: 1/50 | Batch: 300/782 | 单Batch损失: 1.3525 | 累计平均损失: 1.7562
Epoch: 1/50 | Batch: 400/782 | 单Batch损失: 1.3983 | 累计平均损失: 1.6667
Epoch: 1/50 | Batch: 500/782 | 单Batch损失: 1.2711 | 累计平均损失: 1.6013
Epoch: 1/50 | Batch: 600/782 | 单Batch损失: 1.5219 | 累计平均损失: 1.5493
Epoch: 1/50 | Batch: 700/782 | 单Batch损失: 1.3993 | 累计平均损失: 1.5032
Epoch 1/50 完成 | 耗时: 44.58s | 训练准确率: 45.97% | 测试准确率: 65.59%
Epoch: 2/50 | Batch: 100/782 | 单Batch损失: 1.3702 | 累计平均损失: 1.2011
Epoch: 2/50 | Batch: 200/782 | 单Batch损失: 1.1570 | 累计平均损失: 1.1816
Epoch: 2/50 | Batch: 300/782 | 单Batch损失: 1.2680 | 累计平均损失: 1.1723
Epoch: 2/50 | Batch: 400/782 | 单Batch损失: 1.0104 | 累计平均损失: 1.1616
Epoch: 2/50 | Batch: 500/782 | 单Batch损失: 1.0775 | 累计平均损失: 1.1547
Epoch: 2/50 | Batch: 600/782 | 单Batch损失: 0.7792 | 累计平均损失: 1.1422
Epoch: 2/50 | Batch: 700/782 | 单Batch损失: 1.0966 | 累计平均损失: 1.1350
Epoch 2/50 完成 | 耗时: 45.55s | 训练准确率: 60.43% | 测试准确率: 70.30%
Epoch: 3/50 | Batch: 100/782 | 单Batch损失: 1.1602 | 累计平均损失: 1.0786
Epoch: 3/50 | Batch: 200/782 | 单Batch损失: 1.1154 | 累计平均损失: 1.0650
Epoch: 3/50 | Batch: 300/782 | 单Batch损失: 1.2021 | 累计平均损失: 1.0647
Epoch: 3/50 | Batch: 400/782 | 单Batch损失: 1.0482 | 累计平均损失: 1.0554
Epoch: 3/50 | Batch: 500/782 | 单Batch损失: 0.9524 | 累计平均损失: 1.0556
Epoch: 3/50 | Batch: 600/782 | 单Batch损失: 0.9516 | 累计平均损失: 1.0467
Epoch: 3/50 | Batch: 700/782 | 单Batch损失: 1.0887 | 累计平均损失: 1.0391
Epoch 3/50 完成 | 耗时: 44.01s | 训练准确率: 64.05% | 测试准确率: 73.36%
Epoch: 4/50 | Batch: 100/782 | 单Batch损失: 1.0069 | 累计平均损失: 1.0019
Epoch: 4/50 | Batch: 200/782 | 单Batch损失: 1.1889 | 累计平均损失: 1.0057
Epoch: 4/50 | Batch: 300/782 | 单Batch损失: 1.1446 | 累计平均损失: 1.0048
Epoch: 4/50 | Batch: 400/782 | 单Batch损失: 1.0381 | 累计平均损失: 1.0009
Epoch: 4/50 | Batch: 500/782 | 单Batch损失: 0.9675 | 累计平均损失: 0.9998
Epoch: 4/50 | Batch: 600/782 | 单Batch损失: 0.9027 | 累计平均损失: 0.9949
Epoch: 4/50 | Batch: 700/782 | 单Batch损失: 1.0135 | 累计平均损失: 0.9906
Epoch 4/50 完成 | 耗时: 45.93s | 训练准确率: 65.83% | 测试准确率: 73.09%
Epoch: 5/50 | Batch: 100/782 | 单Batch损失: 1.3844 | 累计平均损失: 0.9606
Epoch: 5/50 | Batch: 200/782 | 单Batch损失: 0.9874 | 累计平均损失: 0.9552
Epoch: 5/50 | Batch: 300/782 | 单Batch损失: 0.6890 | 累计平均损失: 0.9611
Epoch: 5/50 | Batch: 400/782 | 单Batch损失: 1.0992 | 累计平均损失: 0.9569
Epoch: 5/50 | Batch: 500/782 | 单Batch损失: 1.0124 | 累计平均损失: 0.9533
Epoch: 5/50 | Batch: 600/782 | 单Batch损失: 0.9730 | 累计平均损失: 0.9514
Epoch: 5/50 | Batch: 700/782 | 单Batch损失: 0.8750 | 累计平均损失: 0.9520
Epoch 5/50 完成 | 耗时: 43.57s | 训练准确率: 67.44% | 测试准确率: 75.21%
==================================================
**阶段 2:解冻高层卷积层 (features 17-30)**
==================================================
Epoch: 6/50 | Batch: 100/782 | 单Batch损失: 0.9525 | 累计平均损失: 1.0133
Epoch: 6/50 | Batch: 200/782 | 单Batch损失: 1.0390 | 累计平均损失: 0.9892
Epoch: 6/50 | Batch: 300/782 | 单Batch损失: 0.8435 | 累计平均损失: 0.9697
Epoch: 6/50 | Batch: 400/782 | 单Batch损失: 0.8093 | 累计平均损失: 0.9525
Epoch: 6/50 | Batch: 500/782 | 单Batch损失: 1.0202 | 累计平均损失: 0.9389
Epoch: 6/50 | Batch: 600/782 | 单Batch损失: 0.9691 | 累计平均损失: 0.9276
Epoch: 6/50 | Batch: 700/782 | 单Batch损失: 0.7845 | 累计平均损失: 0.9137
Epoch 6/50 完成 | 耗时: 44.87s | 训练准确率: 69.40% | 测试准确率: 80.48%
Epoch: 7/50 | Batch: 100/782 | 单Batch损失: 0.8546 | 累计平均损失: 0.8034
Epoch: 7/50 | Batch: 200/782 | 单Batch损失: 0.9314 | 累计平均损失: 0.7892
Epoch: 7/50 | Batch: 300/782 | 单Batch损失: 0.8307 | 累计平均损失: 0.7820
Epoch: 7/50 | Batch: 400/782 | 单Batch损失: 0.7948 | 累计平均损失: 0.7808
Epoch: 7/50 | Batch: 500/782 | 单Batch损失: 0.6705 | 累计平均损失: 0.7763
Epoch: 7/50 | Batch: 600/782 | 单Batch损失: 0.6565 | 累计平均损失: 0.7710
Epoch: 7/50 | Batch: 700/782 | 单Batch损失: 0.9356 | 累计平均损失: 0.7692
Epoch 7/50 完成 | 耗时: 44.10s | 训练准确率: 74.56% | 测试准确率: 82.12%
Epoch: 8/50 | Batch: 100/782 | 单Batch损失: 0.8082 | 累计平均损失: 0.7130
Epoch: 8/50 | Batch: 200/782 | 单Batch损失: 0.5411 | 累计平均损失: 0.7055
Epoch: 8/50 | Batch: 300/782 | 单Batch损失: 0.8405 | 累计平均损失: 0.7030
Epoch: 8/50 | Batch: 400/782 | 单Batch损失: 0.6998 | 累计平均损失: 0.7000
Epoch: 8/50 | Batch: 500/782 | 单Batch损失: 0.6001 | 累计平均损失: 0.6955
Epoch: 8/50 | Batch: 600/782 | 单Batch损失: 0.5251 | 累计平均损失: 0.6890
Epoch: 8/50 | Batch: 700/782 | 单Batch损失: 0.5528 | 累计平均损失: 0.6875
Epoch 8/50 完成 | 耗时: 43.39s | 训练准确率: 77.22% | 测试准确率: 82.80%
Epoch: 9/50 | Batch: 100/782 | 单Batch损失: 0.8478 | 累计平均损失: 0.6609
Epoch: 9/50 | Batch: 200/782 | 单Batch损失: 0.9905 | 累计平均损失: 0.6572
Epoch: 9/50 | Batch: 300/782 | 单Batch损失: 0.8812 | 累计平均损失: 0.6441
Epoch: 9/50 | Batch: 400/782 | 单Batch损失: 0.6530 | 累计平均损失: 0.6395
Epoch: 9/50 | Batch: 500/782 | 单Batch损失: 0.5794 | 累计平均损失: 0.6437
Epoch: 9/50 | Batch: 600/782 | 单Batch损失: 0.5964 | 累计平均损失: 0.6416
Epoch: 9/50 | Batch: 700/782 | 单Batch损失: 0.5492 | 累计平均损失: 0.6382
Epoch 9/50 完成 | 耗时: 46.06s | 训练准确率: 78.79% | 测试准确率: 84.10%
Epoch: 10/50 | Batch: 100/782 | 单Batch损失: 0.6457 | 累计平均损失: 0.6225
Epoch: 10/50 | Batch: 200/782 | 单Batch损失: 0.6635 | 累计平均损失: 0.6221
Epoch: 10/50 | Batch: 300/782 | 单Batch损失: 0.5259 | 累计平均损失: 0.6107
Epoch: 10/50 | Batch: 400/782 | 单Batch损失: 0.6342 | 累计平均损失: 0.6096
Epoch: 10/50 | Batch: 500/782 | 单Batch损失: 0.5066 | 累计平均损失: 0.6036
Epoch: 10/50 | Batch: 600/782 | 单Batch损失: 0.4775 | 累计平均损失: 0.6026
Epoch: 10/50 | Batch: 700/782 | 单Batch损失: 0.4644 | 累计平均损失: 0.5975
Epoch 10/50 完成 | 耗时: 44.17s | 训练准确率: 80.02% | 测试准确率: 84.99%
Epoch: 11/50 | Batch: 100/782 | 单Batch损失: 0.5181 | 累计平均损失: 0.5678
Epoch: 11/50 | Batch: 200/782 | 单Batch损失: 0.4668 | 累计平均损失: 0.5742
Epoch: 11/50 | Batch: 300/782 | 单Batch损失: 0.6041 | 累计平均损失: 0.5706
Epoch: 11/50 | Batch: 400/782 | 单Batch损失: 0.4549 | 累计平均损失: 0.5646
Epoch: 11/50 | Batch: 500/782 | 单Batch损失: 0.5661 | 累计平均损失: 0.5630
Epoch: 11/50 | Batch: 600/782 | 单Batch损失: 0.4941 | 累计平均损失: 0.5629
Epoch: 11/50 | Batch: 700/782 | 单Batch损失: 0.6719 | 累计平均损失: 0.5636
Epoch 11/50 完成 | 耗时: 46.11s | 训练准确率: 81.20% | 测试准确率: 85.59%
Epoch: 12/50 | Batch: 100/782 | 单Batch损失: 0.6041 | 累计平均损失: 0.5065
Epoch: 12/50 | Batch: 200/782 | 单Batch损失: 0.5212 | 累计平均损失: 0.5240
Epoch: 12/50 | Batch: 300/782 | 单Batch损失: 0.4535 | 累计平均损失: 0.5262
Epoch: 12/50 | Batch: 400/782 | 单Batch损失: 0.4024 | 累计平均损失: 0.5265
Epoch: 12/50 | Batch: 500/782 | 单Batch损失: 0.5667 | 累计平均损失: 0.5260
Epoch: 12/50 | Batch: 600/782 | 单Batch损失: 0.4736 | 累计平均损失: 0.5275
Epoch: 12/50 | Batch: 700/782 | 单Batch损失: 0.3657 | 累计平均损失: 0.5295
Epoch 12/50 完成 | 耗时: 45.58s | 训练准确率: 82.27% | 测试准确率: 86.50%
Epoch: 13/50 | Batch: 100/782 | 单Batch损失: 0.6435 | 累计平均损失: 0.5012
Epoch: 13/50 | Batch: 200/782 | 单Batch损失: 0.5296 | 累计平均损失: 0.5007
Epoch: 13/50 | Batch: 300/782 | 单Batch损失: 0.3240 | 累计平均损失: 0.5002
Epoch: 13/50 | Batch: 400/782 | 单Batch损失: 0.5343 | 累计平均损失: 0.5007
Epoch: 13/50 | Batch: 500/782 | 单Batch损失: 0.5318 | 累计平均损失: 0.5058
Epoch: 13/50 | Batch: 600/782 | 单Batch损失: 0.3491 | 累计平均损失: 0.5048
Epoch: 13/50 | Batch: 700/782 | 单Batch损失: 0.5395 | 累计平均损失: 0.5062
Epoch 13/50 完成 | 耗时: 42.65s | 训练准确率: 82.95% | 测试准确率: 85.28%
Epoch: 14/50 | Batch: 100/782 | 单Batch损失: 0.3773 | 累计平均损失: 0.4577
Epoch: 14/50 | Batch: 200/782 | 单Batch损失: 0.6456 | 累计平均损失: 0.4665
Epoch: 14/50 | Batch: 300/782 | 单Batch损失: 0.3989 | 累计平均损失: 0.4687
Epoch: 14/50 | Batch: 400/782 | 单Batch损失: 0.4966 | 累计平均损失: 0.4765
Epoch: 14/50 | Batch: 500/782 | 单Batch损失: 0.4851 | 累计平均损失: 0.4799
Epoch: 14/50 | Batch: 600/782 | 单Batch损失: 0.4281 | 累计平均损失: 0.4815
Epoch: 14/50 | Batch: 700/782 | 单Batch损失: 0.2749 | 累计平均损失: 0.4829
Epoch 14/50 完成 | 耗时: 45.92s | 训练准确率: 83.97% | 测试准确率: 86.68%
Epoch: 15/50 | Batch: 100/782 | 单Batch损失: 0.6055 | 累计平均损失: 0.4809
Epoch: 15/50 | Batch: 200/782 | 单Batch损失: 0.5193 | 累计平均损失: 0.4668
Epoch: 15/50 | Batch: 300/782 | 单Batch损失: 0.4821 | 累计平均损失: 0.4624
Epoch: 15/50 | Batch: 400/782 | 单Batch损失: 0.3487 | 累计平均损失: 0.4607
Epoch: 15/50 | Batch: 500/782 | 单Batch损失: 0.5683 | 累计平均损失: 0.4623
Epoch: 15/50 | Batch: 600/782 | 单Batch损失: 0.6684 | 累计平均损失: 0.4652
Epoch: 15/50 | Batch: 700/782 | 单Batch损失: 0.7181 | 累计平均损失: 0.4684
Epoch 15/50 完成 | 耗时: 44.46s | 训练准确率: 84.31% | 测试准确率: 87.38%
Epoch: 16/50 | Batch: 100/782 | 单Batch损失: 0.6311 | 累计平均损失: 0.4378
Epoch: 16/50 | Batch: 200/782 | 单Batch损失: 0.3834 | 累计平均损失: 0.4360
Epoch: 16/50 | Batch: 300/782 | 单Batch损失: 0.4118 | 累计平均损失: 0.4349
Epoch: 16/50 | Batch: 400/782 | 单Batch损失: 0.5199 | 累计平均损失: 0.4446
Epoch: 16/50 | Batch: 500/782 | 单Batch损失: 0.4544 | 累计平均损失: 0.4521
Epoch: 16/50 | Batch: 600/782 | 单Batch损失: 0.3277 | 累计平均损失: 0.4494
Epoch: 16/50 | Batch: 700/782 | 单Batch损失: 0.3073 | 累计平均损失: 0.4483
Epoch 16/50 完成 | 耗时: 45.46s | 训练准确率: 85.10% | 测试准确率: 87.76%
Epoch: 17/50 | Batch: 100/782 | 单Batch损失: 0.5786 | 累计平均损失: 0.4285
Epoch: 17/50 | Batch: 200/782 | 单Batch损失: 0.2672 | 累计平均损失: 0.4158
Epoch: 17/50 | Batch: 300/782 | 单Batch损失: 0.6549 | 累计平均损失: 0.4199
Epoch: 17/50 | Batch: 400/782 | 单Batch损失: 0.2725 | 累计平均损失: 0.4207
Epoch: 17/50 | Batch: 500/782 | 单Batch损失: 0.3361 | 累计平均损失: 0.4222
Epoch: 17/50 | Batch: 600/782 | 单Batch损失: 0.2837 | 累计平均损失: 0.4250
Epoch: 17/50 | Batch: 700/782 | 单Batch损失: 0.3694 | 累计平均损失: 0.4244
Epoch 17/50 完成 | 耗时: 44.21s | 训练准确率: 85.76% | 测试准确率: 87.98%
Epoch: 18/50 | Batch: 100/782 | 单Batch损失: 0.3102 | 累计平均损失: 0.4076
Epoch: 18/50 | Batch: 200/782 | 单Batch损失: 0.3988 | 累计平均损失: 0.4160
Epoch: 18/50 | Batch: 300/782 | 单Batch损失: 0.5079 | 累计平均损失: 0.4166
Epoch: 18/50 | Batch: 400/782 | 单Batch损失: 0.4572 | 累计平均损失: 0.4194
Epoch: 18/50 | Batch: 500/782 | 单Batch损失: 0.3407 | 累计平均损失: 0.4202
Epoch: 18/50 | Batch: 600/782 | 单Batch损失: 0.2056 | 累计平均损失: 0.4178
Epoch: 18/50 | Batch: 700/782 | 单Batch损失: 0.5021 | 累计平均损失: 0.4161
Epoch 18/50 完成 | 耗时: 44.00s | 训练准确率: 86.10% | 测试准确率: 87.92%
Epoch: 19/50 | Batch: 100/782 | 单Batch损失: 0.3875 | 累计平均损失: 0.4075
Epoch: 19/50 | Batch: 200/782 | 单Batch损失: 0.2705 | 累计平均损失: 0.4062
Epoch: 19/50 | Batch: 300/782 | 单Batch损失: 0.3310 | 累计平均损失: 0.4020
Epoch: 19/50 | Batch: 400/782 | 单Batch损失: 0.7302 | 累计平均损失: 0.4031
Epoch: 19/50 | Batch: 500/782 | 单Batch损失: 0.5806 | 累计平均损失: 0.4046
Epoch: 19/50 | Batch: 600/782 | 单Batch损失: 0.4491 | 累计平均损失: 0.4036
Epoch: 19/50 | Batch: 700/782 | 单Batch损失: 0.4433 | 累计平均损失: 0.4019
Epoch 19/50 完成 | 耗时: 45.25s | 训练准确率: 86.55% | 测试准确率: 88.20%
Epoch: 20/50 | Batch: 100/782 | 单Batch损失: 0.3506 | 累计平均损失: 0.3830
Epoch: 20/50 | Batch: 200/782 | 单Batch损失: 0.3832 | 累计平均损失: 0.3850
Epoch: 20/50 | Batch: 300/782 | 单Batch损失: 0.4669 | 累计平均损失: 0.3862
Epoch: 20/50 | Batch: 400/782 | 单Batch损失: 0.3470 | 累计平均损失: 0.3856
Epoch: 20/50 | Batch: 500/782 | 单Batch损失: 0.5021 | 累计平均损失: 0.3830
Epoch: 20/50 | Batch: 600/782 | 单Batch损失: 0.2543 | 累计平均损失: 0.3843
Epoch: 20/50 | Batch: 700/782 | 单Batch损失: 0.2123 | 累计平均损失: 0.3851
Epoch 20/50 完成 | 耗时: 45.76s | 训练准确率: 86.92% | 测试准确率: 88.27%
==================================================
**阶段 3:解冻所有层,进行全局微调**
==================================================
Epoch: 21/50 | Batch: 100/782 | 单Batch损失: 0.4499 | 累计平均损失: 0.3409
Epoch: 21/50 | Batch: 200/782 | 单Batch损失: 0.2803 | 累计平均损失: 0.3442
Epoch: 21/50 | Batch: 300/782 | 单Batch损失: 0.5222 | 累计平均损失: 0.3388
Epoch: 21/50 | Batch: 400/782 | 单Batch损失: 0.2717 | 累计平均损失: 0.3336
Epoch: 21/50 | Batch: 500/782 | 单Batch损失: 0.4110 | 累计平均损失: 0.3268
Epoch: 21/50 | Batch: 600/782 | 单Batch损失: 0.3074 | 累计平均损失: 0.3257
Epoch: 21/50 | Batch: 700/782 | 单Batch损失: 0.4456 | 累计平均损失: 0.3229
Epoch 21/50 完成 | 耗时: 50.07s | 训练准确率: 89.12% | 测试准确率: 89.09%
Epoch: 22/50 | Batch: 100/782 | 单Batch损失: 0.2055 | 累计平均损失: 0.2974
Epoch: 22/50 | Batch: 200/782 | 单Batch损失: 0.2505 | 累计平均损失: 0.2876
Epoch: 22/50 | Batch: 300/782 | 单Batch损失: 0.2528 | 累计平均损失: 0.2927
Epoch: 22/50 | Batch: 400/782 | 单Batch损失: 0.1889 | 累计平均损失: 0.2945
Epoch: 22/50 | Batch: 500/782 | 单Batch损失: 0.1024 | 累计平均损失: 0.2931
Epoch: 22/50 | Batch: 600/782 | 单Batch损失: 0.2279 | 累计平均损失: 0.2939
Epoch: 22/50 | Batch: 700/782 | 单Batch损失: 0.1303 | 累计平均损失: 0.2944
Epoch 22/50 完成 | 耗时: 48.16s | 训练准确率: 90.14% | 测试准确率: 89.62%
Epoch: 23/50 | Batch: 100/782 | 单Batch损失: 0.4221 | 累计平均损失: 0.2976
Epoch: 23/50 | Batch: 200/782 | 单Batch损失: 0.2823 | 累计平均损失: 0.2980
Epoch: 23/50 | Batch: 300/782 | 单Batch损失: 0.3706 | 累计平均损失: 0.2872
Epoch: 23/50 | Batch: 400/782 | 单Batch损失: 0.2858 | 累计平均损失: 0.2862
Epoch: 23/50 | Batch: 500/782 | 单Batch损失: 0.2233 | 累计平均损失: 0.2836
Epoch: 23/50 | Batch: 600/782 | 单Batch损失: 0.4694 | 累计平均损失: 0.2843
Epoch: 23/50 | Batch: 700/782 | 单Batch损失: 0.3438 | 累计平均损失: 0.2848
Epoch 23/50 完成 | 耗时: 47.49s | 训练准确率: 90.36% | 测试准确率: 89.47%
Epoch: 24/50 | Batch: 100/782 | 单Batch损失: 0.2588 | 累计平均损失: 0.2807
Epoch: 24/50 | Batch: 200/782 | 单Batch损失: 0.2666 | 累计平均损失: 0.2853
Epoch: 24/50 | Batch: 300/782 | 单Batch损失: 0.2779 | 累计平均损失: 0.2798
Epoch: 24/50 | Batch: 400/782 | 单Batch损失: 0.3286 | 累计平均损失: 0.2763
Epoch: 24/50 | Batch: 500/782 | 单Batch损失: 0.3347 | 累计平均损失: 0.2790
Epoch: 24/50 | Batch: 600/782 | 单Batch损失: 0.2135 | 累计平均损失: 0.2775
Epoch: 24/50 | Batch: 700/782 | 单Batch损失: 0.2744 | 累计平均损失: 0.2747
Epoch 24/50 完成 | 耗时: 48.68s | 训练准确率: 90.73% | 测试准确率: 89.84%
Epoch: 25/50 | Batch: 100/782 | 单Batch损失: 0.3880 | 累计平均损失: 0.2538
Epoch: 25/50 | Batch: 200/782 | 单Batch损失: 0.4967 | 累计平均损失: 0.2601
Epoch: 25/50 | Batch: 300/782 | 单Batch损失: 0.2734 | 累计平均损失: 0.2644
Epoch: 25/50 | Batch: 400/782 | 单Batch损失: 0.2157 | 累计平均损失: 0.2668
Epoch: 25/50 | Batch: 500/782 | 单Batch损失: 0.2542 | 累计平均损失: 0.2668
Epoch: 25/50 | Batch: 600/782 | 单Batch损失: 0.3547 | 累计平均损失: 0.2675
Epoch: 25/50 | Batch: 700/782 | 单Batch损失: 0.5125 | 累计平均损失: 0.2641
Epoch 25/50 完成 | 耗时: 47.03s | 训练准确率: 91.11% | 测试准确率: 89.57%
Epoch: 26/50 | Batch: 100/782 | 单Batch损失: 0.4087 | 累计平均损失: 0.2577
Epoch: 26/50 | Batch: 200/782 | 单Batch损失: 0.4989 | 累计平均损失: 0.2574
Epoch: 26/50 | Batch: 300/782 | 单Batch损失: 0.2294 | 累计平均损失: 0.2565
Epoch: 26/50 | Batch: 400/782 | 单Batch损失: 0.0950 | 累计平均损失: 0.2562
Epoch: 26/50 | Batch: 500/782 | 单Batch损失: 0.2312 | 累计平均损失: 0.2583
Epoch: 26/50 | Batch: 600/782 | 单Batch损失: 0.2300 | 累计平均损失: 0.2583
Epoch: 26/50 | Batch: 700/782 | 单Batch损失: 0.3930 | 累计平均损失: 0.2572
Epoch 26/50 完成 | 耗时: 45.92s | 训练准确率: 91.18% | 测试准确率: 89.88%
Epoch: 27/50 | Batch: 100/782 | 单Batch损失: 0.4780 | 累计平均损失: 0.2734
Epoch: 27/50 | Batch: 200/782 | 单Batch损失: 0.3950 | 累计平均损失: 0.2564
Epoch: 27/50 | Batch: 300/782 | 单Batch损失: 0.2581 | 累计平均损失: 0.2570
Epoch: 27/50 | Batch: 400/782 | 单Batch损失: 0.2109 | 累计平均损失: 0.2555
Epoch: 27/50 | Batch: 500/782 | 单Batch损失: 0.1451 | 累计平均损失: 0.2539
Epoch: 27/50 | Batch: 600/782 | 单Batch损失: 0.5966 | 累计平均损失: 0.2548
Epoch: 27/50 | Batch: 700/782 | 单Batch损失: 0.1832 | 累计平均损失: 0.2542
Epoch 27/50 完成 | 耗时: 46.42s | 训练准确率: 91.38% | 测试准确率: 89.88%
Epoch: 28/50 | Batch: 100/782 | 单Batch损失: 0.2343 | 累计平均损失: 0.2491
Epoch: 28/50 | Batch: 200/782 | 单Batch损失: 0.2561 | 累计平均损失: 0.2461
Epoch: 28/50 | Batch: 300/782 | 单Batch损失: 0.3587 | 累计平均损失: 0.2459
Epoch: 28/50 | Batch: 400/782 | 单Batch损失: 0.2645 | 累计平均损失: 0.2432
Epoch: 28/50 | Batch: 500/782 | 单Batch损失: 0.3130 | 累计平均损失: 0.2428
Epoch: 28/50 | Batch: 600/782 | 单Batch损失: 0.3228 | 累计平均损失: 0.2433
Epoch: 28/50 | Batch: 700/782 | 单Batch损失: 0.2348 | 累计平均损失: 0.2453
Epoch 28/50 完成 | 耗时: 44.49s | 训练准确率: 91.69% | 测试准确率: 89.76%
Epoch: 29/50 | Batch: 100/782 | 单Batch损失: 0.1096 | 累计平均损失: 0.2363
Epoch: 29/50 | Batch: 200/782 | 单Batch损失: 0.2373 | 累计平均损失: 0.2392
Epoch: 29/50 | Batch: 300/782 | 单Batch损失: 0.3243 | 累计平均损失: 0.2397
Epoch: 29/50 | Batch: 400/782 | 单Batch损失: 0.1743 | 累计平均损失: 0.2429
Epoch: 29/50 | Batch: 500/782 | 单Batch损失: 0.2297 | 累计平均损失: 0.2446
Epoch: 29/50 | Batch: 600/782 | 单Batch损失: 0.3294 | 累计平均损失: 0.2430
Epoch: 29/50 | Batch: 700/782 | 单Batch损失: 0.1227 | 累计平均损失: 0.2432
Epoch 29/50 完成 | 耗时: 46.13s | 训练准确率: 91.78% | 测试准确率: 89.58%
Epoch: 30/50 | Batch: 100/782 | 单Batch损失: 0.2625 | 累计平均损失: 0.2294
Epoch: 30/50 | Batch: 200/782 | 单Batch损失: 0.2453 | 累计平均损失: 0.2338
Epoch: 30/50 | Batch: 300/782 | 单Batch损失: 0.1655 | 累计平均损失: 0.2348
Epoch: 30/50 | Batch: 400/782 | 单Batch损失: 0.2633 | 累计平均损失: 0.2382
Epoch: 30/50 | Batch: 500/782 | 单Batch损失: 0.2890 | 累计平均损失: 0.2380
Epoch: 30/50 | Batch: 600/782 | 单Batch损失: 0.3140 | 累计平均损失: 0.2382
Epoch: 30/50 | Batch: 700/782 | 单Batch损失: 0.3076 | 累计平均损失: 0.2376
Epoch 30/50 完成 | 耗时: 47.80s | 训练准确率: 92.05% | 测试准确率: 90.05%
Epoch: 31/50 | Batch: 100/782 | 单Batch损失: 0.2126 | 累计平均损失: 0.2268
Epoch: 31/50 | Batch: 200/782 | 单Batch损失: 0.1463 | 累计平均损失: 0.2204
Epoch: 31/50 | Batch: 300/782 | 单Batch损失: 0.1002 | 累计平均损失: 0.2199
Epoch: 31/50 | Batch: 400/782 | 单Batch损失: 0.0766 | 累计平均损失: 0.2219
Epoch: 31/50 | Batch: 500/782 | 单Batch损失: 0.1805 | 累计平均损失: 0.2238
Epoch: 31/50 | Batch: 600/782 | 单Batch损失: 0.1238 | 累计平均损失: 0.2273
Epoch: 31/50 | Batch: 700/782 | 单Batch损失: 0.2888 | 累计平均损失: 0.2271
Epoch 31/50 完成 | 耗时: 48.03s | 训练准确率: 92.29% | 测试准确率: 90.04%
Epoch: 32/50 | Batch: 100/782 | 单Batch损失: 0.1744 | 累计平均损失: 0.2220
Epoch: 32/50 | Batch: 200/782 | 单Batch损失: 0.2029 | 累计平均损失: 0.2296
Epoch: 32/50 | Batch: 300/782 | 单Batch损失: 0.0928 | 累计平均损失: 0.2290
Epoch: 32/50 | Batch: 400/782 | 单Batch损失: 0.1529 | 累计平均损失: 0.2279
Epoch: 32/50 | Batch: 500/782 | 单Batch损失: 0.2070 | 累计平均损失: 0.2265
Epoch: 32/50 | Batch: 600/782 | 单Batch损失: 0.2541 | 累计平均损失: 0.2297
Epoch: 32/50 | Batch: 700/782 | 单Batch损失: 0.1368 | 累计平均损失: 0.2293
Epoch 32/50 完成 | 耗时: 46.34s | 训练准确率: 92.29% | 测试准确率: 89.97%
Epoch: 33/50 | Batch: 100/782 | 单Batch损失: 0.3285 | 累计平均损失: 0.2279
Epoch: 33/50 | Batch: 200/782 | 单Batch损失: 0.1984 | 累计平均损失: 0.2199
Epoch: 33/50 | Batch: 300/782 | 单Batch损失: 0.2083 | 累计平均损失: 0.2169
Epoch: 33/50 | Batch: 400/782 | 单Batch损失: 0.1612 | 累计平均损失: 0.2159
Epoch: 33/50 | Batch: 500/782 | 单Batch损失: 0.2259 | 累计平均损失: 0.2178
Epoch: 33/50 | Batch: 600/782 | 单Batch损失: 0.3105 | 累计平均损失: 0.2201
Epoch: 33/50 | Batch: 700/782 | 单Batch损失: 0.1795 | 累计平均损失: 0.2221
Epoch 33/50 完成 | 耗时: 45.48s | 训练准确率: 92.51% | 测试准确率: 89.97%
Epoch: 34/50 | Batch: 100/782 | 单Batch损失: 0.2584 | 累计平均损失: 0.2037
Epoch: 34/50 | Batch: 200/782 | 单Batch损失: 0.1003 | 累计平均损失: 0.2104
Epoch: 34/50 | Batch: 300/782 | 单Batch损失: 0.1768 | 累计平均损失: 0.2067
Epoch: 34/50 | Batch: 400/782 | 单Batch损失: 0.1120 | 累计平均损失: 0.2096
Epoch: 34/50 | Batch: 500/782 | 单Batch损失: 0.1492 | 累计平均损失: 0.2117
Epoch: 34/50 | Batch: 600/782 | 单Batch损失: 0.4729 | 累计平均损失: 0.2118
Epoch: 34/50 | Batch: 700/782 | 单Batch损失: 0.2829 | 累计平均损失: 0.2132
Epoch 34/50 完成 | 耗时: 47.31s | 训练准确率: 92.63% | 测试准确率: 89.97%
Epoch: 35/50 | Batch: 100/782 | 单Batch损失: 0.0973 | 累计平均损失: 0.2162
Epoch: 35/50 | Batch: 200/782 | 单Batch损失: 0.3113 | 累计平均损失: 0.2114
Epoch: 35/50 | Batch: 300/782 | 单Batch损失: 0.1509 | 累计平均损失: 0.2140
Epoch: 35/50 | Batch: 400/782 | 单Batch损失: 0.1400 | 累计平均损失: 0.2106
Epoch: 35/50 | Batch: 500/782 | 单Batch损失: 0.1742 | 累计平均损失: 0.2132
Epoch: 35/50 | Batch: 600/782 | 单Batch损失: 0.1834 | 累计平均损失: 0.2116
Epoch: 35/50 | Batch: 700/782 | 单Batch损失: 0.1941 | 累计平均损失: 0.2118
Epoch 35/50 完成 | 耗时: 45.55s | 训练准确率: 92.75% | 测试准确率: 90.35%
Epoch: 36/50 | Batch: 100/782 | 单Batch损失: 0.1941 | 累计平均损失: 0.2100
Epoch: 36/50 | Batch: 200/782 | 单Batch损失: 0.3143 | 累计平均损失: 0.2123
Epoch: 36/50 | Batch: 300/782 | 单Batch损失: 0.3180 | 累计平均损失: 0.2120
Epoch: 36/50 | Batch: 400/782 | 单Batch损失: 0.1477 | 累计平均损失: 0.2105
Epoch: 36/50 | Batch: 500/782 | 单Batch损失: 0.2480 | 累计平均损失: 0.2081
Epoch: 36/50 | Batch: 600/782 | 单Batch损失: 0.1265 | 累计平均损失: 0.2070
Epoch: 36/50 | Batch: 700/782 | 单Batch损失: 0.2208 | 累计平均损失: 0.2076
Epoch 36/50 完成 | 耗时: 45.81s | 训练准确率: 92.84% | 测试准确率: 90.02%
Epoch: 37/50 | Batch: 100/782 | 单Batch损失: 0.2978 | 累计平均损失: 0.2121
Epoch: 37/50 | Batch: 200/782 | 单Batch损失: 0.1337 | 累计平均损失: 0.2079
Epoch: 37/50 | Batch: 300/782 | 单Batch损失: 0.1106 | 累计平均损失: 0.2072
Epoch: 37/50 | Batch: 400/782 | 单Batch损失: 0.1462 | 累计平均损失: 0.2059
Epoch: 37/50 | Batch: 500/782 | 单Batch损失: 0.2917 | 累计平均损失: 0.2055
Epoch: 37/50 | Batch: 600/782 | 单Batch损失: 0.2256 | 累计平均损失: 0.2054
Epoch: 37/50 | Batch: 700/782 | 单Batch损失: 0.3676 | 累计平均损失: 0.2064
Epoch 37/50 完成 | 耗时: 51.01s | 训练准确率: 92.96% | 测试准确率: 90.09%
Epoch: 38/50 | Batch: 100/782 | 单Batch损失: 0.1724 | 累计平均损失: 0.2071
Epoch: 38/50 | Batch: 200/782 | 单Batch损失: 0.2279 | 累计平均损失: 0.2038
Epoch: 38/50 | Batch: 300/782 | 单Batch损失: 0.1562 | 累计平均损失: 0.2035
Epoch: 38/50 | Batch: 400/782 | 单Batch损失: 0.2418 | 累计平均损失: 0.2016
Epoch: 38/50 | Batch: 500/782 | 单Batch损失: 0.1331 | 累计平均损失: 0.2007
Epoch: 38/50 | Batch: 600/782 | 单Batch损失: 0.0358 | 累计平均损失: 0.2015
Epoch: 38/50 | Batch: 700/782 | 单Batch损失: 0.2012 | 累计平均损失: 0.2034
Epoch 38/50 完成 | 耗时: 45.56s | 训练准确率: 93.02% | 测试准确率: 89.94%
Epoch: 39/50 | Batch: 100/782 | 单Batch损失: 0.0745 | 累计平均损失: 0.1889
Epoch: 39/50 | Batch: 200/782 | 单Batch损失: 0.1449 | 累计平均损失: 0.1931
Epoch: 39/50 | Batch: 300/782 | 单Batch损失: 0.0746 | 累计平均损失: 0.1929
Epoch: 39/50 | Batch: 400/782 | 单Batch损失: 0.2014 | 累计平均损失: 0.1966
Epoch: 39/50 | Batch: 500/782 | 单Batch损失: 0.1101 | 累计平均损失: 0.1967
Epoch: 39/50 | Batch: 600/782 | 单Batch损失: 0.1739 | 累计平均损失: 0.1969
Epoch: 39/50 | Batch: 700/782 | 单Batch损失: 0.2660 | 累计平均损失: 0.1965
Epoch 39/50 完成 | 耗时: 48.10s | 训练准确率: 93.32% | 测试准确率: 89.98%
Epoch: 40/50 | Batch: 100/782 | 单Batch损失: 0.1464 | 累计平均损失: 0.2063
Epoch: 40/50 | Batch: 200/782 | 单Batch损失: 0.1744 | 累计平均损失: 0.1973
Epoch: 40/50 | Batch: 300/782 | 单Batch损失: 0.1837 | 累计平均损失: 0.1974
Epoch: 40/50 | Batch: 400/782 | 单Batch损失: 0.1493 | 累计平均损失: 0.1952
Epoch: 40/50 | Batch: 500/782 | 单Batch损失: 0.1925 | 累计平均损失: 0.1956
Epoch: 40/50 | Batch: 600/782 | 单Batch损失: 0.4688 | 累计平均损失: 0.1944
Epoch: 40/50 | Batch: 700/782 | 单Batch损失: 0.2618 | 累计平均损失: 0.1942
Epoch 40/50 完成 | 耗时: 45.23s | 训练准确率: 93.32% | 测试准确率: 89.90%
Epoch: 41/50 | Batch: 100/782 | 单Batch损失: 0.3755 | 累计平均损失: 0.1835
Epoch: 41/50 | Batch: 200/782 | 单Batch损失: 0.1731 | 累计平均损失: 0.1842
Epoch: 41/50 | Batch: 300/782 | 单Batch损失: 0.1727 | 累计平均损失: 0.1827
Epoch: 41/50 | Batch: 400/782 | 单Batch损失: 0.1781 | 累计平均损失: 0.1839
Epoch: 41/50 | Batch: 500/782 | 单Batch损失: 0.3459 | 累计平均损失: 0.1847
Epoch: 41/50 | Batch: 600/782 | 单Batch损失: 0.2775 | 累计平均损失: 0.1870
Epoch: 41/50 | Batch: 700/782 | 单Batch损失: 0.1197 | 累计平均损失: 0.1857
Epoch 41/50 完成 | 耗时: 44.92s | 训练准确率: 93.64% | 测试准确率: 90.36%
Epoch: 42/50 | Batch: 100/782 | 单Batch损失: 0.2667 | 累计平均损失: 0.1943
Epoch: 42/50 | Batch: 200/782 | 单Batch损失: 0.1461 | 累计平均损失: 0.1902
Epoch: 42/50 | Batch: 300/782 | 单Batch损失: 0.2032 | 累计平均损失: 0.1881
Epoch: 42/50 | Batch: 400/782 | 单Batch损失: 0.1085 | 累计平均损失: 0.1863
Epoch: 42/50 | Batch: 500/782 | 单Batch损失: 0.2701 | 累计平均损失: 0.1851
Epoch: 42/50 | Batch: 600/782 | 单Batch损失: 0.3015 | 累计平均损失: 0.1879
Epoch: 42/50 | Batch: 700/782 | 单Batch损失: 0.3653 | 累计平均损失: 0.1883
Epoch 42/50 完成 | 耗时: 49.64s | 训练准确率: 93.47% | 测试准确率: 90.00%
Epoch: 43/50 | Batch: 100/782 | 单Batch损失: 0.2850 | 累计平均损失: 0.1776
Epoch: 43/50 | Batch: 200/782 | 单Batch损失: 0.1780 | 累计平均损失: 0.1752
Epoch: 43/50 | Batch: 300/782 | 单Batch损失: 0.1189 | 累计平均损失: 0.1722
Epoch: 43/50 | Batch: 400/782 | 单Batch损失: 0.0734 | 累计平均损失: 0.1752
Epoch: 43/50 | Batch: 500/782 | 单Batch损失: 0.2057 | 累计平均损失: 0.1795
Epoch: 43/50 | Batch: 600/782 | 单Batch损失: 0.2651 | 累计平均损失: 0.1804
Epoch: 43/50 | Batch: 700/782 | 单Batch损失: 0.1135 | 累计平均损失: 0.1798
Epoch 43/50 完成 | 耗时: 45.35s | 训练准确率: 93.81% | 测试准确率: 90.11%
Epoch: 44/50 | Batch: 100/782 | 单Batch损失: 0.1531 | 累计平均损失: 0.1688
Epoch: 44/50 | Batch: 200/782 | 单Batch损失: 0.2061 | 累计平均损失: 0.1831
Epoch: 44/50 | Batch: 300/782 | 单Batch损失: 0.1842 | 累计平均损失: 0.1881
Epoch: 44/50 | Batch: 400/782 | 单Batch损失: 0.0837 | 累计平均损失: 0.1806
Epoch: 44/50 | Batch: 500/782 | 单Batch损失: 0.1702 | 累计平均损失: 0.1803
Epoch: 44/50 | Batch: 600/782 | 单Batch损失: 0.0747 | 累计平均损失: 0.1788
Epoch: 44/50 | Batch: 700/782 | 单Batch损失: 0.2756 | 累计平均损失: 0.1802
Epoch 44/50 完成 | 耗时: 47.31s | 训练准确率: 93.87% | 测试准确率: 90.30%
Epoch: 45/50 | Batch: 100/782 | 单Batch损失: 0.1605 | 累计平均损失: 0.1760
Epoch: 45/50 | Batch: 200/782 | 单Batch损失: 0.1025 | 累计平均损失: 0.1774
Epoch: 45/50 | Batch: 300/782 | 单Batch损失: 0.2391 | 累计平均损失: 0.1766
Epoch: 45/50 | Batch: 400/782 | 单Batch损失: 0.2520 | 累计平均损失: 0.1758
Epoch: 45/50 | Batch: 500/782 | 单Batch损失: 0.1377 | 累计平均损失: 0.1753
Epoch: 45/50 | Batch: 600/782 | 单Batch损失: 0.1646 | 累计平均损失: 0.1754
Epoch: 45/50 | Batch: 700/782 | 单Batch损失: 0.1905 | 累计平均损失: 0.1757
Epoch 45/50 完成 | 耗时: 45.04s | 训练准确率: 94.00% | 测试准确率: 89.92%
Epoch: 46/50 | Batch: 100/782 | 单Batch损失: 0.1077 | 累计平均损失: 0.1697
Epoch: 46/50 | Batch: 200/782 | 单Batch损失: 0.1432 | 累计平均损失: 0.1704
Epoch: 46/50 | Batch: 300/782 | 单Batch损失: 0.1727 | 累计平均损失: 0.1721
Epoch: 46/50 | Batch: 400/782 | 单Batch损失: 0.2897 | 累计平均损失: 0.1734
Epoch: 46/50 | Batch: 500/782 | 单Batch损失: 0.1190 | 累计平均损失: 0.1722
Epoch: 46/50 | Batch: 600/782 | 单Batch损失: 0.2002 | 累计平均损失: 0.1750
Epoch: 46/50 | Batch: 700/782 | 单Batch损失: 0.1131 | 累计平均损失: 0.1765
Epoch 46/50 完成 | 耗时: 45.99s | 训练准确率: 93.93% | 测试准确率: 90.15%
Epoch: 47/50 | Batch: 100/782 | 单Batch损失: 0.3100 | 累计平均损失: 0.1632
Epoch: 47/50 | Batch: 200/782 | 单Batch损失: 0.1920 | 累计平均损失: 0.1607
Epoch: 47/50 | Batch: 300/782 | 单Batch损失: 0.1461 | 累计平均损失: 0.1658
Epoch: 47/50 | Batch: 400/782 | 单Batch损失: 0.1348 | 累计平均损失: 0.1650
Epoch: 47/50 | Batch: 500/782 | 单Batch损失: 0.1224 | 累计平均损失: 0.1647
Epoch: 47/50 | Batch: 600/782 | 单Batch损失: 0.1450 | 累计平均损失: 0.1689
Epoch: 47/50 | Batch: 700/782 | 单Batch损失: 0.1678 | 累计平均损失: 0.1704
Epoch 47/50 完成 | 耗时: 47.87s | 训练准确率: 94.17% | 测试准确率: 90.16%
Epoch: 48/50 | Batch: 100/782 | 单Batch损失: 0.1005 | 累计平均损失: 0.1772
Epoch: 48/50 | Batch: 200/782 | 单Batch损失: 0.1809 | 累计平均损失: 0.1726
Epoch: 48/50 | Batch: 300/782 | 单Batch损失: 0.0382 | 累计平均损失: 0.1700
Epoch: 48/50 | Batch: 400/782 | 单Batch损失: 0.2581 | 累计平均损失: 0.1683
Epoch: 48/50 | Batch: 500/782 | 单Batch损失: 0.0898 | 累计平均损失: 0.1671
Epoch: 48/50 | Batch: 600/782 | 单Batch损失: 0.0505 | 累计平均损失: 0.1666
Epoch: 48/50 | Batch: 700/782 | 单Batch损失: 0.4168 | 累计平均损失: 0.1685
Epoch 48/50 完成 | 耗时: 46.67s | 训练准确率: 94.23% | 测试准确率: 90.47%
Epoch: 49/50 | Batch: 100/782 | 单Batch损失: 0.1299 | 累计平均损失: 0.1565
Epoch: 49/50 | Batch: 200/782 | 单Batch损失: 0.1168 | 累计平均损失: 0.1634
Epoch: 49/50 | Batch: 300/782 | 单Batch损失: 0.1516 | 累计平均损失: 0.1640
Epoch: 49/50 | Batch: 400/782 | 单Batch损失: 0.1734 | 累计平均损失: 0.1630
Epoch: 49/50 | Batch: 500/782 | 单Batch损失: 0.1532 | 累计平均损失: 0.1623
Epoch: 49/50 | Batch: 600/782 | 单Batch损失: 0.0709 | 累计平均损失: 0.1657
Epoch: 49/50 | Batch: 700/782 | 单Batch损失: 0.0803 | 累计平均损失: 0.1647
Epoch 49/50 完成 | 耗时: 46.83s | 训练准确率: 94.30% | 测试准确率: 90.50%
Epoch: 50/50 | Batch: 100/782 | 单Batch损失: 0.3703 | 累计平均损失: 0.1670
Epoch: 50/50 | Batch: 200/782 | 单Batch损失: 0.2956 | 累计平均损失: 0.1618
Epoch: 50/50 | Batch: 300/782 | 单Batch损失: 0.1813 | 累计平均损失: 0.1649
Epoch: 50/50 | Batch: 400/782 | 单Batch损失: 0.1484 | 累计平均损失: 0.1653
Epoch: 50/50 | Batch: 500/782 | 单Batch损失: 0.2528 | 累计平均损失: 0.1656
Epoch: 50/50 | Batch: 600/782 | 单Batch损失: 0.3289 | 累计平均损失: 0.1684
Epoch: 50/50 | Batch: 700/782 | 单Batch损失: 0.0867 | 累计平均损失: 0.1667
Epoch 50/50 完成 | 耗时: 45.57s | 训练准确率: 94.27% | 测试准确率: 90.44%使用4090训练,总共训练时间大约在38分钟,最终准确率在90.44%。可以看到存在过拟合,虽然不太严重。

















 1023
1023

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









