 机器学习建模与评估实战
机器学习建模与评估实战





今日任务:
- 回顾预处理的全流程
- 机器学习的简单建模:数据集的划分,建模的三行代码
- 机器学习模型分类问题的评估指标
- 对心脏病数据集采用机器学习模型建模和评估
经过前面的学习,机器学习数据预处理的步骤已基本掌握,现在进入机器学习的建模和评估。
一、数据读取
选择信贷数据集进行读取数据,确定标签与特征。
此外,说明df.drop()函数:
- DataFrame.drop(labels, axis=0, index=None, columns=None, inplace=False)
labels:要删除的行或列的标签- axis:制定删除列(axis=1)还是行(axis=0,默认)
#读取数据
data = pd.read_csv(r'data.csv')
data.head()
data.info()#查看基本信息:缺失值、数据类型、尺寸等
#确定标签和特征
X = data.drop(['Credit Default'],axis=1) #特征
y = data['Credit Default'] #标签二、数据预处理
在实际操作中,需要先进行缺失值处理,然后进行数据类型转换,接着处理异常值,再进行特征缩放,最后进行特征工程。这样的顺序可以保证数据在预处理过程中的一致性和有效性,为后续的机器学习模型训练提供高质量的数据。
2.1 离散特征编码
由数据的概览信息可以得到‘Years in current job’这列存在缺失值,但是为非数值型类型,所以选择先进行数据类型转换,然后进行缺失值处理。
回顾Day 5 所学:(1)筛选出非数值型特征,select_dtypes()(2)查看离散变量,选择编码方法:标签编码(有序),独热编码(无序)(3)调用对应的函数进行编码:map() / get_dummies()(4)若为独热编码,还需要进行数据转换(bool型到int型)(5)检查
#数据类型转换
#提取离散特征
discrete_features = data.select_dtypes(include=['object']).columns.tolist()
#查看离散特征分布
for col in discrete_features:
print(data[col].value_counts())#选择编码方法
#1-标签编码:Home Ownership,Years in current job,Term
mapping_dict = {
'Home Ownership':{
'Own Home':0,
'Rent':1,
"Have Mortgage":2,
'Home Mortgage':3
},
"Years in current job": {
"10+ years": 10,
"2 years": 2,
"3 years": 3,
"< 1 year": 0,
"5 years": 5,
"1 year": 1,
"4 years": 4,
"6 years": 6,
"7 years": 7,
"8 years": 8,
"9 years": 9
},
'Term':{
'Short Term':0,
'Long Term':1
}
}
for key, value in mapping_dict.items(): #遍历字典
data[key] = data[key].map(value) #调用函数映射
#2-独热编码:Purpose
data = pd.get_dummies(data,columns=['Purpose']) #调用函数
data_1 = pd.read_csv(r'data.csv')
new_features = []
#寻找新特征
for i in data.columns:
if i not in data_1:
new_features.append(i)
#数据转换:bool->int
for j in new_features:
data[j] = data[j].astype(int)
data.dtypes2.2 缺失值填补
对数值型特征进行缺失值的填补,根据需要选择不同的填充方法:均值、中位数或基于其他相关特征进行回归预测填充等。由于不考虑效果,选择使用众数填充:
#缺失值填充
numeric_features = data.select_dtypes(include=['float64','int64']).columns.tolist()
for i in numeric_features:
mode_filled = data[i].mode()[0] #计算。众数可能有多个
data[i] = data[i].fillna(mode_filled)#填充
data.isnull().sum()
2.3 异常值处理
对于数值型特征,可以通过箱线图等方法检测异常值。如果存在异常值,需根据实际情况决定是否进行处理。若是数据录入错误等原因导致的异常值,可以进行修正或删除;若是真实存在的极端值,可能需要保留,但在某些模型中可能需要进行特殊处理,如采用稳健的统计方法或对数据进行变换。
实际上,对于异常值一般采取不处理或者结合对照试验分析处理前后的结果。
2.4 连续特征缩放
对数值型特征进行特征缩放,将其缩放到相同的尺度,以避免某些特征因数值较大而在模型中占据主导地位。常用的方法有Min - Max标准化和Z - score标准化。
#对连续特征进行标准化
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler() #实例化
data[continous_features] = standard_scaler.fit_transform(data[continous_features])
data[continous_features].head()2.5 特征工程
包括衍生新特征和特征选择两种:前者根据已有特征创建新的特征,可能会对模型性能有提升;后者通过相关性分析等方法,选择与标签相关性较高的特征,去除相关性较低或冗余的特征,以降低模型的复杂度和过拟合的风险。
三、可视化分析
描述性统计,用来展现单特征分布、多特征间的关系以及标签与特征的关系等。在day6 描述性统计 以及day9 热力图与子图绘制 中都有过可视化分析的操作,此处不再说明。
四、建模
今日主要学习简单的建模与评估,不涉及调参部分。
4.1 数据划分
在训练数据之前,需要划分训练集与测试集,借助sklearn里的train_test_split():
- X,y:特征数据集,通常是DataFrame或numpy数组;目标变量,通常是Series或numpy数组
- test_size:测试集的比例,一般在0.2 ~ 0.3
- random_state:控制随机数生成器的种子,设置固定值可确保结果重现
- train_size:训练集的比例(与test_size选一个使用)
- shuffle:是否在划分前打乱数据,默认为True;对于时间序列数据,通常设置为False
- stratify:按指定标签进行分层抽样,保持类别比例
- 函数的返回值依次为训练集特征(X_train)、测试集特征、训练集标签(y_train)、测试集标签
from sklearn.model_selection import train_test_split
#划分训练集和测试集
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=42)
print(X_train.shape,X_test.shape) #打印划分后的尺寸
4.2 模型训练与评估
训练
对于不同的模型进行训练,虽然模型不同,但本质上只有三行代码:
- 模型的实例化:knn_model = KNeighborsClassifier()
- 模型训练(代入训练集):knn_model.fit(X_train, y_train)
- 模型预测(代入测试集):knn_pred = knn_model.predict(X_test)
from sklearn.neighbors import KNeighborsClassifier #K近邻分类器
from sklearn.linear_model import LogisticRegression #逻辑回归
from lightgbm import LGBMClassifier #LGBM分类器
from xgboost import XGBClassifier #XBGoost分类器
from sklearn.ensemble import RandomForestClassifier #随机森林分类器
#导入评估指标
from sklearn.metrics import accuracy_score,precision_score,f1_score,recall_score
from sklearn.metrics import classification_report,confusion_matrix
import warnings #用于忽略警告信息,方便显示信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
#逻辑回归
logreg_model = LogisticRegression(random_state=42) #实例化
logreg_model.fit(X_train,y_train) #训练
logreg_pred = logreg_model.predict(X_test) #预测这里还注意到,建模时对于有些模型需要随机种子而有些不需要,主要与模型本身是否具有随机性有关:
- 基于树的方法:涉及特征采样、数据采样,具有随机性。如XGBoost\LightGBM\RF等
- 距离-Based方法:纯距离计算,无随机性;如KNN
- 线性模型:数学优化,结果确定;如线性回归
- 神经网络:权重初始化随机
评估
对于不同的机器学习问题有不同的评估指标,根据实际情况选择指标:
- 回归:均方误差(MSE)、均方根误差(RMSE)、
、平均绝对误差MAE等
- 分类:accuracy,precision,recall,F1-Score,AUC,混淆矩阵,分类报告等
-
聚类:轮廓系数,Calinski-Harabasz指数等
信贷数据集处理的是一个二分类问题,采用分类报告、混淆矩阵、准确率、精确率、召回率和F1分数进行评估:
- precision:预测为正例的样本中真正为正例的比例,注重减少假正例(垃圾邮件检测)
- accuracy:全局指标,衡量所有类别预测正确的比例 (TP + TN) / (TP + TN + FP + FN)
- recall:真正为正例的样本中被预测为正例的比例,注重减少假负例(疾病诊断)
- F1-Score:精确率和召回率的调和平均数
- classification_report:汇总,生成所有类别的指标
- confusion_matrix:[[TN, FP],[FN, TP]]
注:TP即 True Positive,FN即False Negative。
#得到分类报告和混淆矩阵
print('Logreg 分类报告:')
print(classification_report(y_test,logreg_pred)) #y_true,y_pred
print('Logreg 混淆矩阵:')
print(confusion_matrix(y_test,logreg_pred))
#评估指标
print(f'Logreg的准确率:{accuracy_score(y_test,logreg_pred):.4f}')
print(f'Logreg的精确率:{precision_score(y_test,logreg_pred):.4f}')
print(f'Logreg的召回率:{recall_score(y_test,logreg_pred):.4f}')
print(f'Logreg的F1分数:{f1_score(y_test,logreg_pred):.4f}')
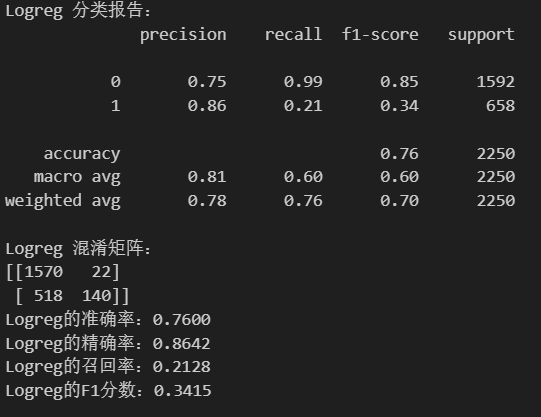
此外,如果单独调用precision_score等指标,在二分类中默认只计算正类(标签 1)的性能。
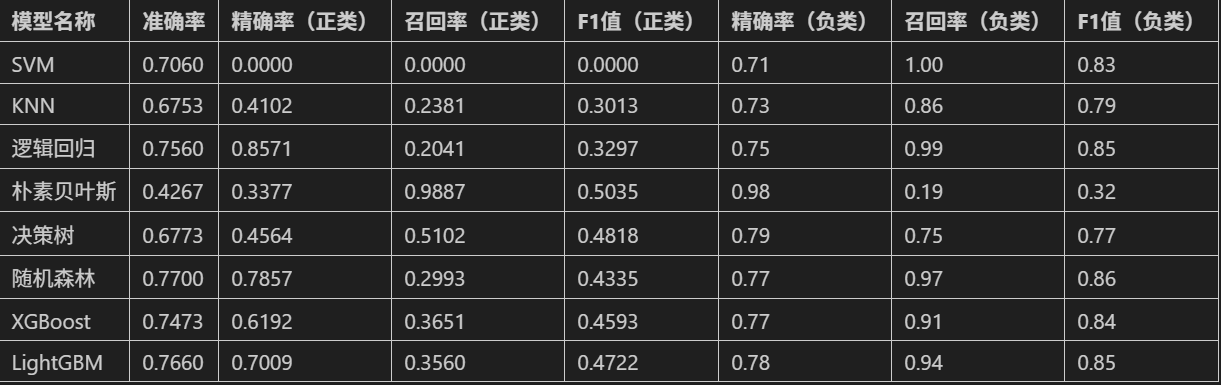
对于不同的模型,按照上述方法,替换模型后完成建模与评估,可得到类似下面的结果(示例):
五、作业:心脏病数据建模与评估
对于心脏病数据,由于之前的预处理步骤差不多已完成,简单回顾一下。重点操作建模与评估部分。
1.数据读取与查看
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#读取数据
data = pd.read_csv(r'heart.csv')
data.head() #读取前5行
data.info()
data.isnull().sum()2.没有缺失值,进行编码和标准化
#对于多分类特征进行独热编码
continous_features = ['age','trestbps','chol','thalach','oldpeak']
discrete_features = ['sex','cp','fbs','restecg','exang','slope','thal']
multi_features = ['cp','restecg','slope','thal']
data = pd.get_dummies(data=data,columns=multi_features,prefix=multi_features) #返回的是新的dataframe+编码列
data.head()
#对连续特征进行标准化
from sklearn.preprocessing import StandardScaler
standard_scaler = StandardScaler() #实例化
data[continous_features] = standard_scaler.fit_transform(data[continous_features])
data[continous_features].head()3.可视化
4.导入模型、划分标签与特征、训练集与测试集(不调参)
from sklearn.neighbors import KNeighborsClassifier
from sklearn.linear_model import LogisticRegression
from lightgbm import LGBMClassifier
from xgboost import XGBClassifier
from sklearn.ensemble import RandomForestClassifier
#导入评估指标
from sklearn.metrics import accuracy_score,precision_score,f1_score,recall_score
from sklearn.metrics import classification_report,confusion_matrix
import warnings #用于忽略警告信息
warnings.filterwarnings("ignore") # 忽略所有警告信息
#标签和特征
X = data.drop(['target'],axis=1)
y = data['target']
#划分训练集与测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=42)
5.对比模型的评估指标(KNN、LogisticRegression、XGBoost)
#1-KNN
knn_model = KNeighborsClassifier()#实例化
knn_model.fit(X_train,y_train)
knn_pred = knn_model.predict(X_test)
#计算混淆矩阵和分类报告
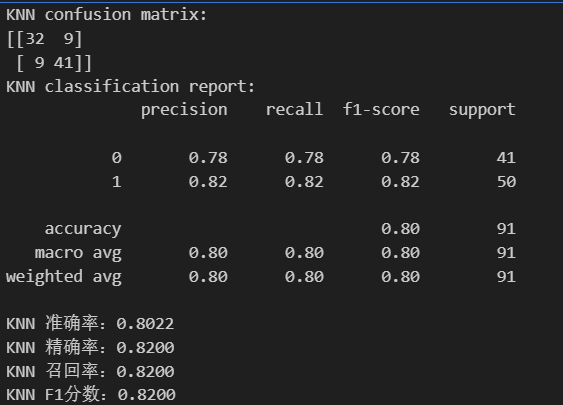
print('KNN confusion matrix:')
print(confusion_matrix(y_test,knn_pred))
print('KNN classification report:')
print(classification_report(y_test,knn_pred))
#评估指标
print(f'KNN 准确率:{accuracy_score(y_test,knn_pred):.4f}')
print(f'KNN 精确率:{precision_score(y_test,knn_pred):.4f}')
print(f'KNN 召回率:{recall_score(y_test,knn_pred):.4f}')
print(f'KNN F1分数:{f1_score(y_test,knn_pred):.4f}')
#2-逻辑回归
logreg_model = LogisticRegression(random_state=42) #实例化
logreg_model.fit(X_train,y_train) #训练
logreg_pred = logreg_model.predict(X_test) #预测
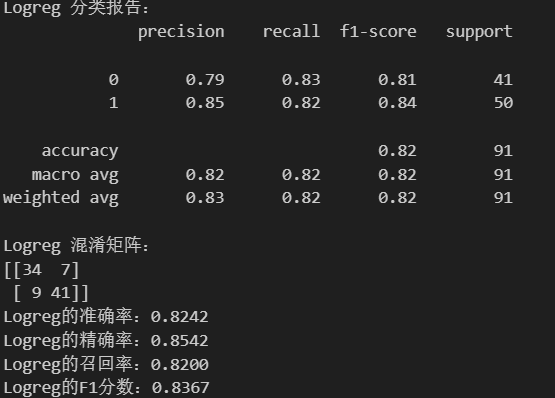
#得到分类报告和混淆矩阵
print('Logreg 分类报告:')
print(classification_report(y_test,logreg_pred)) #y_true,y_pred
print('Logreg 混淆矩阵:')
print(confusion_matrix(y_test,logreg_pred))
#评估指标
print(f'Logreg的准确率:{accuracy_score(y_test,logreg_pred):.4f}')
print(f'Logreg的精确率:{precision_score(y_test,logreg_pred):.4f}')
print(f'Logreg的召回率:{recall_score(y_test,logreg_pred):.4f}')
print(f'Logreg的F1分数:{f1_score(y_test,logreg_pred):.4f}')
#3-XGBoost
xgb_model = XGBClassifier(random_state=42) #实例化
xgb_model.fit(X_train,y_train) #训练
xgb_pred = xgb_model.predict(X_test) #预测
#得到分类报告和混淆矩阵
print('Xgb 分类报告:')
print(classification_report(y_test,xgb_pred)) #y_true,y_pred
print('Xgb 混淆矩阵:')
print(confusion_matrix(y_test,xgb_pred))
#评估指标
print(f'Lgb的准确率:{accuracy_score(y_test,xgb_pred):.4f}')
print(f'Lgb的精确率:{precision_score(y_test,xgb_pred):.4f}')
print(f'Lgb的召回率:{recall_score(y_test,xgb_pred):.4f}')
print(f'Lgb的F1分数:{f1_score(y_test,xgb_pred):.4f}')
评估指标对比如下:


















 808
808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









