




今日任务:
- 热力图的绘制方法
- 子图的绘制方法
-
对心脏病数据集绘制热力图和单特征分布的大图(包含几个子图)
在day 6中初步学习了描述性统计分析,掌握了箱型图、直方图、计数图等图形的绘制。然而这些图形并不能很好反映多变量之间的关系,故而学习热力图(Heatmap)用于描述特征间的关系。此外,还注意到有些图形属于同一类分析,单独绘制不便于分析,完全可以将其汇总到一张大图中,这就是子图。
数据读取
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
data = pd.read_csv(r'data.csv')
data.head()数据预处理
此处练习标签编码的使用“定义映射字典、map函数映射、检查”,回顾Day 8 所学:
#标签编码
mapping_dict = {
'Years in current job':{
"10+ years":10,
"2 years":2,
"3 years": 3,
"< 1 year": 0,
"5 years": 5,
"1 year": 1,
"4 years": 4,
"6 years": 6,
"7 years": 7,
"8 years": 8,
"9 years": 9
},
'Term':{
'Short Term':0,
'Long Term':1
}
}
data['Years in current job'] = data['Years in current job'].map(mapping_dict['Years in current job'])
data['Term'] = data['Term'].map(mapping_dict['Term']) #映射
data.dtypes热力图的绘制
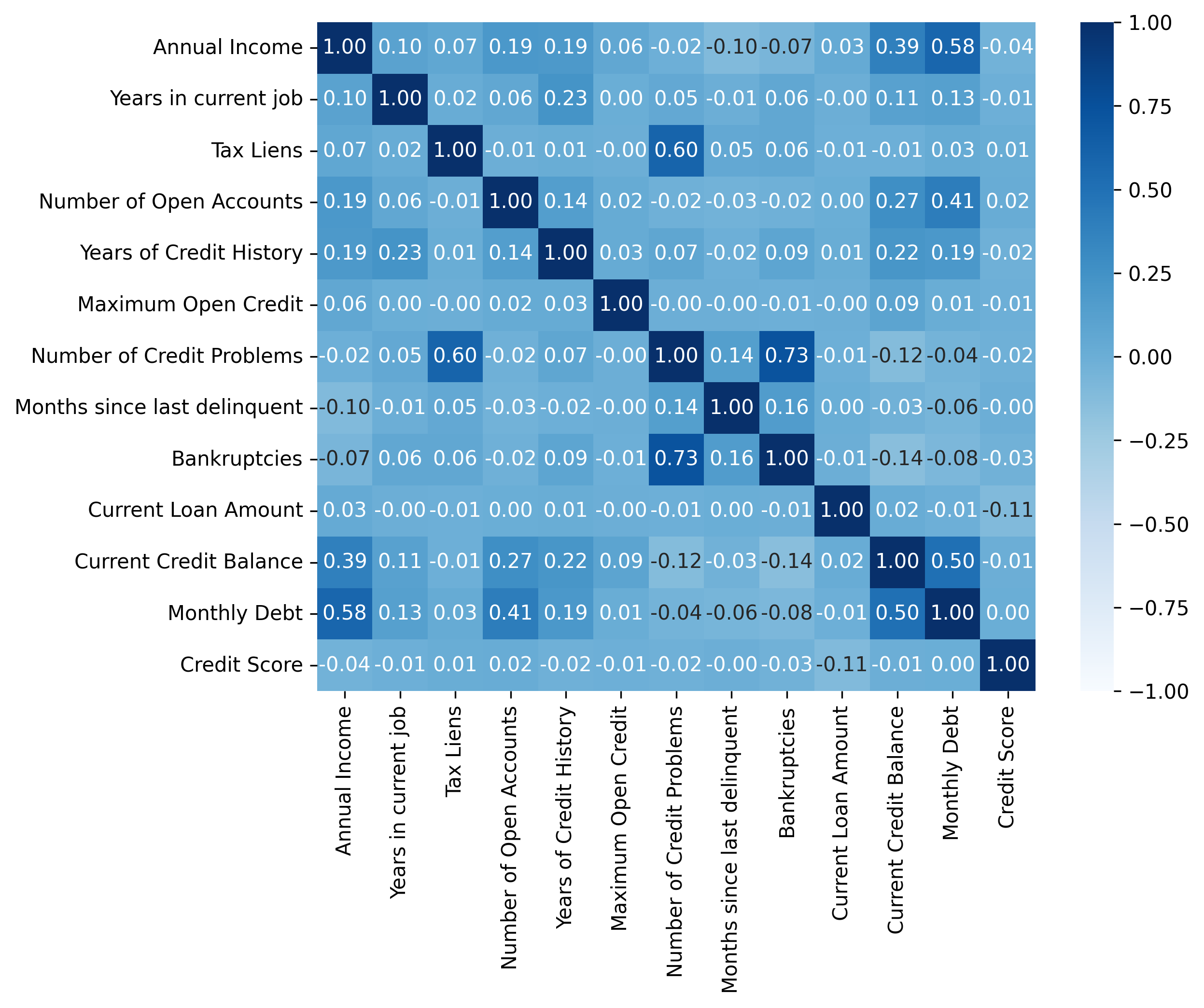
热力图通过颜色的深浅直观展示相关性强度,可用来识别高度相关的特征、快速了解变量的关系模式、发现潜在的数据结构和规律等。但是热力图只能显示线性关系,还存在对异常值敏感、只能处理数值数据等缺点。
绘制热力图的一般步骤:
- 准备预处理好的数据,无缺失值、异常值等
- 绘制相关性系数 data.corr():绘制数值型,numeric_only=True
- 绘图sns.heatmap():参数说明如下
sns.heatmap(
data=correlation_matrix, # 必需:2D数据集(DataFrame或数组)
annot=True, # 是否在格子中显示数值
fmt=".2f", # 数值格式(保留2位小数)
cmap="coolwarm", # 颜色映射
vmin=-1, vmax=1, # 颜色范围
center=0, # 颜色中心点
square=True, # 是否使格子为正方形
cbar=True, # 是否显示颜色条
cbar_kws=None, # 颜色条参数
linewidths=0.5, # 格子间线宽
linecolor='white', # 格子线颜色
annot_kws={"size": 10} # 数值文本格式
)#绘制热图
# 提取连续值特征
continuous_features = [
'Annual Income', 'Years in current job', 'Tax Liens',
'Number of Open Accounts', 'Years of Credit History',
'Maximum Open Credit', 'Number of Credit Problems',
'Months since last delinquent', 'Bankruptcies',
'Current Loan Amount', 'Current Credit Balance', 'Monthly Debt',
'Credit Score'
]
#相关性矩阵的计算
correlation_matrix = data[continuous_features].corr()
#绘图
plt.rcParams['figure.dpi'] = 300 #设置清晰度
plt.figure(figsize=(8,6))
sns.heatmap(correlation_matrix,annot=True,fmt='.2f',cmap='Blues',vmin=-1,vmax=1)
plt.show()
子图的绘制
绘制的子图的思路与画一张图的思路相似,只不过在绘制子图时先创建画布与坐标轴,指定子图的布局。在绘制子图的过程中,根据索引定位到具体的位置上调用方法绘图(参数设置等与单图相似)。
在这个过程,发现需要同时用到索引与值,单独操作过于繁琐,引入enumerate(iterable)函数:
- iterable:可迭代对象,如列表、元祖、字典、字符串等
- start:索引的开始值,默认为0
- 返回值:返回一个迭代对象,包括索引和值
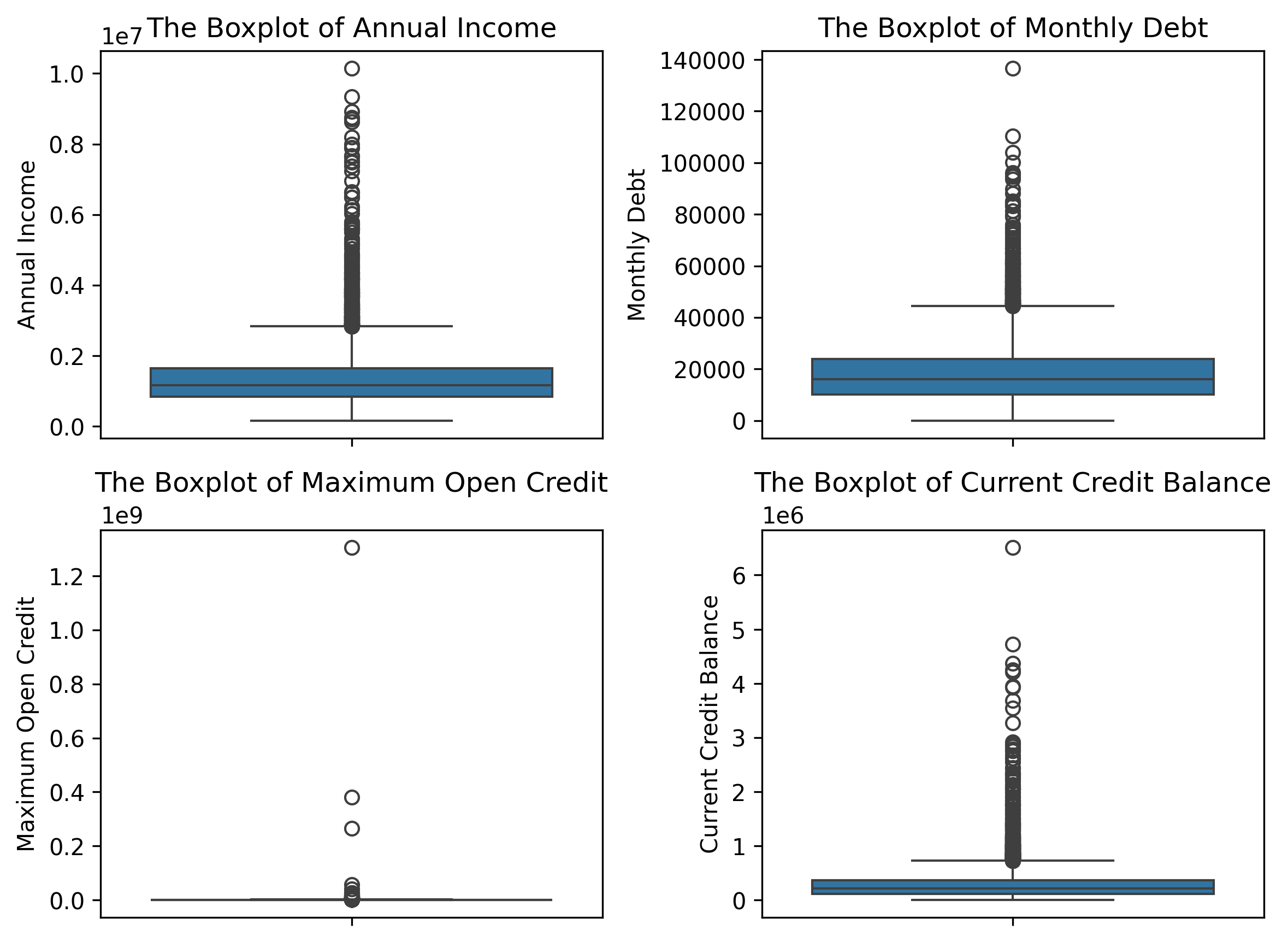
方法一(展平一维):
#绘制子图
features = ['Annual Income','Monthly Debt','Maximum Open Credit','Current Credit Balance']
#创建布局
fig,axes = plt.subplots(2,2,figsize=(8,6))
axes = axes.flatten() #展平为一维,便于遍历
#绘图
for index,value in enumerate(features):
sns.boxplot(data=data,y=features[index],ax=axes[index])
axes[index].set_ylabel(features[index])
axes[index].set_title(f'The Boxplot of {features[index]}')
plt.tight_layout()
plt.show()方法二(未展平):
#绘制子图
features = ['Annual Income','Monthly Debt','Maximum Open Credit','Current Credit Balance']
#创建布局
fig,axes = plt.subplots(2,2,figsize=(8,6))
#绘图
for index,value in enumerate(features):
row = index // 2
col = index % 2
axes[row,col].boxplot(data[features[index]].dropna())#排除缺失值
axes[row,col].set_ylabel(features[index])
axes[row,col].set_title(f'The Boxplot of {features[index]}')
plt.tight_layout()
plt.show()此外,经过实际操作发现,在绘制子图的循环体中,绘图风格不同:
-
sns.histplot(ax=axes[i]):seaborn函数式调用,通过ax参数指定子图位置。更现代、功能更丰富、代码更简洁 -
axes[i].hist():matplotlib 面向对象语法:更底层、控制更精细、但代码更冗长
还注意到,ax索引方式的不同:
- 二维索引:[row,col],需要计算行列索引,适用于小网格
- 展平一维:使用axes.flatten()将二维数组展平维一维,可以直接循环遍历,适用范围更广
心脏数据集实战
结合Day 7 和 今日所学,复习、操作心脏病数据集的描述性统计分析(包括子图的绘制、热力图)。

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









