




本文介绍了机器学习和深度学习的发展历程,以及Python环境搭建与深度学习开发工具配置的完整流程。主要内容包括:1)机器学习与深度学习的发展;2)Python 3.10.11版本的安装;3)深度学习常用的扩展库;4)虚拟环境的概念与创建;5)两种开发环境的使用方法:Spyder IDE适合调试和代码跟踪,Jupyter Notebook适合交互式开发和文档展示;6)张量的概念及其操作的初步演示。张量是深度学习应用中最基本的数据结构。
目录
前言
随着AI大模型技术的快速发展,辅助编码技术已经得到了很大的提高,大模型已经可以自动编写一些像样的代码。在此类技术的辅助下,程序设计者可以节省大量的时间和精力。
但是,不可否认的是,大模型是基于现有知识的,其编写的代码的质量和逻辑往往存在错误,程序设计者需要具备扎实的理论基础来指导AI大模型编写和调试代码,从而真正享受到AI大模型带来的便利。
本专栏没有刻意追求前沿的应用,而是面向深度学习的理论基础,帮助读者理解深层次的原理,从而可以精确地指导AI大模型进行代码编写。
本专栏采用示例入手、逐步深入的方式来剖析原理,便于读者理解。
1 机器学习与深度学习的发展
2016年3月,阿尔法围棋程序(AlphaGo)挑战世界围棋冠军李世石,以4比1的总比分取得了胜利。此事震惊世界,2016年因此被称为人工智能(Artificial Intelligence,AI)“新”元年。随后,该程序在网络上连胜多位中、日、韩围棋高手,更于2017年5月打败当时世界围棋排名第一的柯洁。
实际上人类在棋类游戏中已经是屡屡失败于计算机了,比如国际象棋冠军早在1997年就被名为“深蓝”的计算机打败。为什么这次会引发这么大的轰动呢?除了围棋变化特别大的原因外,更重要的是阿尔法程序已经具备了自我学习和自我进化能力。战胜李世石的第一代阿尔法狗,学习了百万多局人类的棋局。而到了它的升级版,已经完全摆脱人类的思维,从零开始自我学习了三天,就横扫整个围棋界。
机器的这种学习能力,作为人工智能的核心要素,将会对人类社会的生产、生活、军事等活动产生难以估量的影响。
那么,什么是机器学习(Machine Learning,ML)呢?人类的学习中,最基础的是记忆,即机械的复述。但更重要的是指“举一反三”的能力。当用图片、文字、视频等教人们认识动物时,人们不仅记住了动物的知识,还学会了对真实的动物进行分析、辨认和判别,这是一种学习知识,并应用知识的能力。获得这种能力,并用来解决实际问题,正是机器学习的目标。这种能力对人类来说并不难,人类的学习能力比现在所有机器学习算法的能力都要强得多。但计算机具有数据存储和处理方面的优势,一旦它具有了这种能力,就可以高效地替代人完成类似工作。比如,从海量的监视视频中找到某个通缉犯。
要使机器具备这种能力,出现过所谓的符号学习(Symbol Learning)和统计学习(Statistical Learning)两类主要方法。符号学习以知识推理为主要工具,在早期推动了机器学习的发展。随着计算能力的大幅度提升,统计学习占据了更多舞台,作出了更多的贡献。现在,人们提到的机器学习,更多的是指统计学习。从统计学习的角度来说,机器学习算法是从现有数据中分析出规律,并利用规律来对未知数据进行预测的算法。机器学习已经发展成为一门多领域交叉的学科,涉及概率论、统计学、微积分、矩阵论、最优化等知识。
机器学习诞生的标志是1959年IBM公司的计算机科学家亚瑟·塞缪尔编写的一个跳棋程序。该程序可以根据每盘的胜负结果来计算每个棋盘位置的重要性,从而提升计算机下棋的水平。在随后的几十年里,机器学习的发展起起落落,直至近年来异常火热,在学术界得到特别重视。在产业界更是得到广泛应用,涉及到欺诈检测、客户定位、产品推荐、实时工业监控、自动驾驶、人脸识别、情感分析和医疗诊断等等领域,相关从业人员报酬不菲。
传统神经网络(Neural Networks,NN)是实现机器学习中分类、聚类、回归等模型的重要方法。后来,人们发现改进后的多层次的神经网络可以用来自动提取数据特征,从而有效克服人工提取特征的障碍,由此逐渐发展为机器学习的一个分支,即深度学习(Deep Learning,DL)。目前所研究和应用的神经网络是分层次的,深度的含义是指很多层的意思,而传统神经网络的层数很小。近年来正是深度学习取得了重大突破,得到了广泛的应用,从而推动机器学习、乃至人工智能都得到了蓬勃发展。深度学习取得了如此瞩目的成就,以至于在某些情况下,它被看成了一个相对独立的领域。
深度学习并不特指某个算法,而是一类神经网络学习的统称。深度学习在机器视觉、语音识别、自然语言处理、推荐系统和数据挖掘等领域都取得了突破性的进展,成为解决这些领域问题的有力工具。深度学习的兴起与大数据和高性能计算平台的发展有直接关系。训练深度神经网络需要大量的样本数据,训练耗时也大大增加。大数据技术的发展为深度神经网络的训练提供了大量的“燃料”,而以GPU技术为代表的高性能计算平台的发展,为深度神经网络的训练提供了高速的“引擎”。
机器学习、深度学习和近年来人们常提到的人工智能、模式识别、数据挖掘等都存在着或多或少的关系。相比机器学习和深度学习,人工智能具有更加广泛的含义,它包括知识表示、智能推理等基础领域和机器人、自然语言处理、计算机视觉等应用领域。而机器学习和深度学习是人工智能的重要实现技术。
2 Python安装
访问Python官方网站(www.python.org),进入“Downloads”页面,下载稳定版本的安装包。
本专栏的示例基于Windows下的3.10.11版本的Python编写,建议读者下载该版本的Python安装包。Python编程语言不具备向后兼容的特点,因此不同版本的代码可能会不能直接运行。但差异很小,可通过DeepSeek等工具自动转换。
Windows 64位操作系统下的3.10.11版的Python安装包文件名为:“python-3.10.11-amd64.exe”。双击安装,建议勾选“Add Python to PATH”选项。
3 Python扩展库
Python的强大功能来源于它的数量庞大、功能完善的第三方扩展库(也称为包或者模块,package),常用的与深度学习相关的扩展库有以下几个。
1)Numpy
Numpy扩展库提供了数组支持。在深度学习算法的实践中,样本集一般都看作数组进行操作处理,因此该扩展包在深度学习的应用中有很重要的作用。
2)Pandas
Pandas是面板数据(Panel Data)的简写。它是Python的数据分析工具,支持类似SQL的数据增、删、改、查功能。Pandas结合Numpy,可以完成大部分的数据准备工作。
3)Matplotlib
该包主要用于绘图和绘表,是数据可视化工具。在Python程序中经常用来作图示说明,在它的官网提供了很多示例,读者可以根据图形提示,选择相应的代码进行修改以适合自己的需要。在本专栏中,主要是用Matplotlib来画折线图和点图,相关内容不难学习,读者可以参考一些中文学习网站。
4)SymPy
该包主要用于符号计算,如公式推导等,涉及的领域包括:代数运算、多项式、微积分、方程式求解、离散数学、矩阵、几何、物理学、统计学、画图、打印等等。
5)Scikit-Learn(sklearn)
Scikit-Learn是一个基于Python的机器学习扩展包,它包含六个部分:分类、回归、聚类、数据降维(Dimensionality Reduction)、模型选择(Model Selection)和数据预处理(Preprocessing)。它在学术界和工程界都得到了广泛应用。在学习相关知识时,不仅可以参考它提供的丰富资源,还可利用它提供的各种工具来快速完成试验,同时它还提供了算法实现的源代码供学习。
6)Jupyter Notebook
Jupyter Notebook(此前被称为 IPython notebook)是一个交互式笔记本,支持运行40多种编程语言。它是一个Web应用程序,可将代码、文本说明、数学方程、图表等集合在一个文档里,表达能力非常强,便于交流。现在很多资料都采用Jupyter格式,成为同行交流的重要工具。
7)Spyder
Spyder是一款专为Python设计的开源集成开发环境(IDE),尤其适合科学计算和数据分析,支持Linux、Windows和Mac OS系统。 为了便于说明,本专栏的大部分示例程序都以Jupyter格式提供。但该格式的程序不便于查看数据变化过程,读者可以将该格式的代码复制至Spyder中运行,用Spyder提供的单步跟踪等功能来观察数据的变化,以加深对算法运行过程的理解。
8)PyTorch
PyTorch是一个深度学习框架,它由Facebook于2017年开源,它具有简洁、容易理解、可动态调试、功能强大的特点,同时其生态圈也十分丰富,有利于初学者在网上查询和讨论遇到的问题。目前,深度学习及相关领域发表的学术论文的实验大多基于PyTorch来完成,且网上有丰富的基于PyTorch完成的深度学习相关代码供学习和借鉴。2023年,华为正式宣布成为PyTorch基金会的Premier会员,这是中国首个、全球第十个PyTorch基金会最高级别会员。随着华为加入PyTorch生态圈,PyTorch可以方便地使用华为的昇腾处理器作为计算平台。
4 虚拟环境
Python的可应用于不同领域业务开发的第三方扩展库一般来自于不同的机构。它们不仅数量庞大,而且相互之间存在复杂的依赖关系,一个最终使用的扩展库可能依赖于多个其他扩展库才能正常运行,而其他扩展库可能又需要依赖另外的扩展库。
虚拟环境可用来隔离不同应用开发的扩展库依赖关系。比如,当需要同时开发机器学习应用和网络应用时,可以分别放在两个不同的虚拟环境中,以免相互影响而产生意想不到的干扰。建好的虚拟环境还可以整体迁移到其他计算机上,这对于维护环境和配置相同的学生机房十分有用。
考虑到大部分初学者都使用Windows操作系统,因此以Windows下的安装步骤为例来介绍虚拟环境的安装过程。
本专栏的演示程序运行的虚拟环境安装过程如下:
1)安装版本为3.10.11的python。
2)在工作盘(示例为f盘)上新建环境(示例环境名为torchml),并激活。
右键Windows开始菜单,选择“运行”,输入“cmd”进入控制台,然后依次输入并运行以下命令:
-
>f: >cd \ >python -m venv torchml >cd torchml\scripts >activate其中,第三行是创建一个名为“torchml”的虚拟环境,在f盘的根目录下会新生成一个名字“torchml”的文件夹。第五行是激活该虚拟环境。
3)安装PyTorch深度学习框架
到PyTorch官网(https://pytorch.org/)的安装页面,按设备条件生成相应的安装命令,如下图中最下面一行“pip3 install torch torchvision torchaudio”所示。
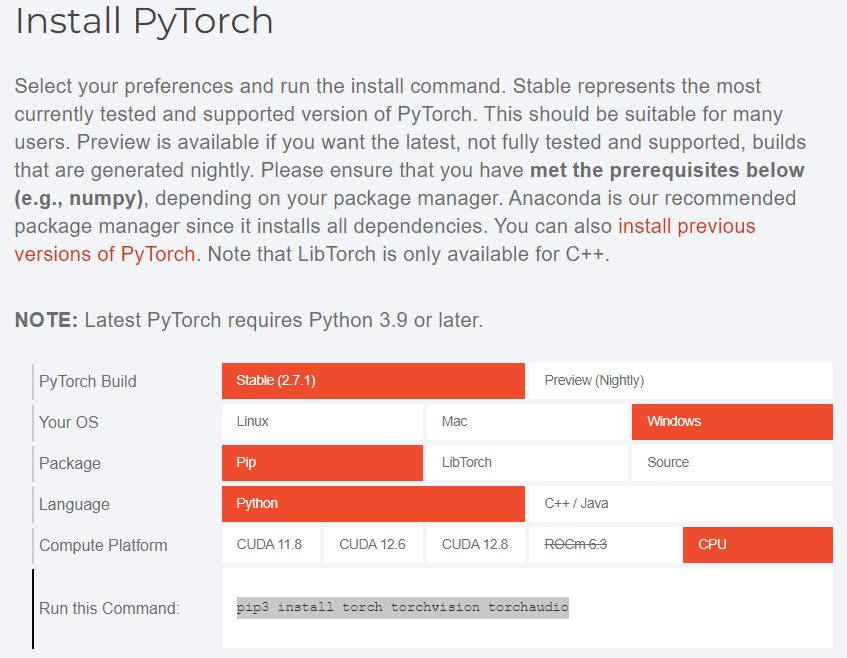
生成的安装命令复制到激活的虚拟环境中执行,如无意外,即可安装PyTorch深度学习框架。
按照支持的不同计算平台(CPU、GPU和华为的昇腾平台),PyTorch深度学习框架分为不同的版本。本专栏面向初学者,大部分示例基于最基本的CPU平台实现。安装GPU平台的版本相对复杂一些,读者可以参考网上资源。
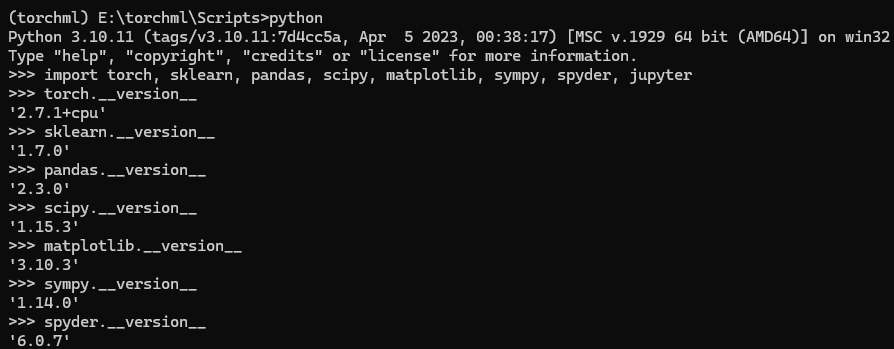
安装后,进入python命令行交互式运行环境,如果能用import语句导入并查看版本号,则说明安装成功,如下图所示。
4)安装其他扩展库
执行以下命令,从清华大学镜像服务器下载并安装scikit-learn扩展库。
>pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn同样方法安装jupyter,matplotlib,spyder,hmmlearn,pandas,torchvision,torchinfo,statsmodels等,并验证是否安装成功,如上图所示。
按以上步骤成功安装后,就可以得到演示示例用的运行环境。可以将torchml文件夹压缩后保存起来,当环境损坏时,可用来解压覆盖原文件夹以快速恢复初始状态,也可用来在相同配置电脑上安装相同的环境,这一点对学生实验机房管理非常有用。
5)安装后的使用方法
假设f盘根目录下的“mywork”目录为工作目录。右键Windows开始菜单,选择“运行”(或者Win键+R键),输入“cmd”进入控制台,然后输入以下命令:
>f:
>cd \ml\scripts
>activate
>cd \mywork然后使用jupyter notebook命令或spyder命令启动相应的开发运行环境。
5 开发环境使用
5.1 Spyder
Spyder是图形化集成开发环境,按上小节的方法启动虚拟环境后,输入“spyder”命令启动Spyder,如下图所示。启动之后,默认会打开一个名为:untitled0.py的临时代码文件。在其中新的一行输入print(“Hello, World!”)语句,点击工具栏中的绿色右三角运行,将在右下的输出窗口中输出“Hello, World!”。
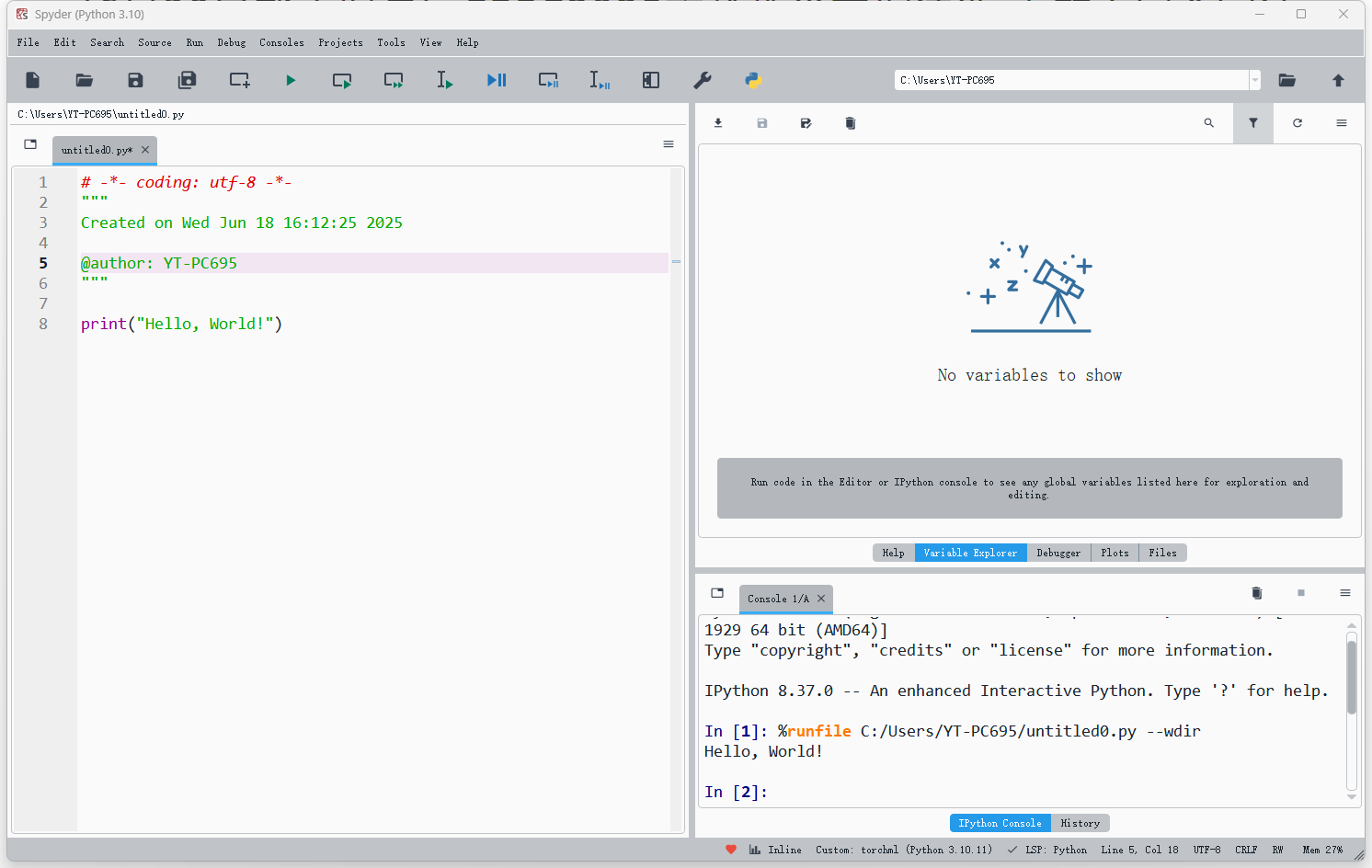
在菜单栏File项里选择“Save as…”命令,可将文件改名另存到任意文件夹里。
5.2 Jupyter Notebook
在虚拟环境中,用“cd”命令进入到工作目录,输入“jupyter notebook”命令在浏览器中启动Jupyter Notebook,工作目录初始为空目录,点击右上角的new按钮,选择其中的“Python3”建立一个新的代码文件。在新打开的窗口的第一行输入print(“Hello, World!”)语句,然后点击工具栏中的Run按钮或者输入Shift+Enter快捷键使程序运行,会在该行下面输出“Hello, World!”,如下图所示。点击File菜单,选择其中的“Rename…”项,可以将保存在工作目录下的文件更名为“hello.ipynb”。可见在Jupyter方式里,也可以进行交互式编程,还可以保存运行过程供以后再次察看。
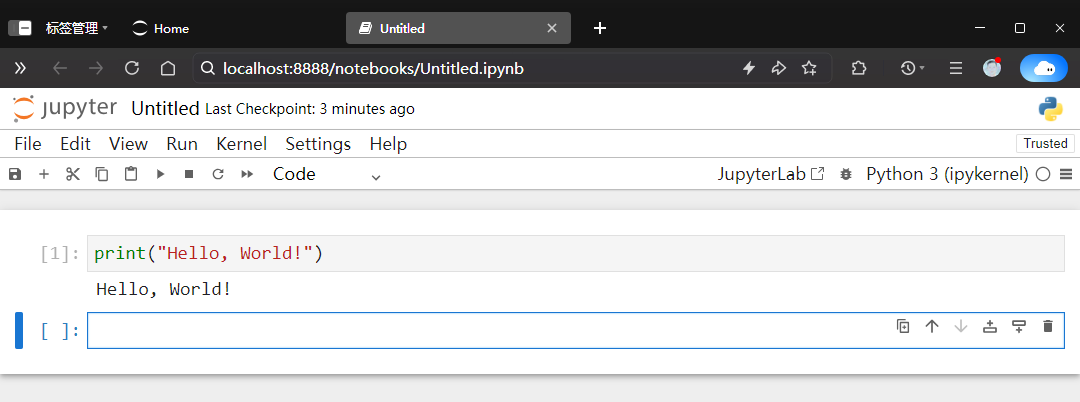
Jupyter Notebook文件中可以嵌入详细的说明,便于交流,而spyder集成开发环境可以单步跟踪代码运行情况,观察数据的变化情况,有利于理解算法的运行过程。当然两个环境并不矛盾,在一个环境中写的代码很容易移植到另一个环境中运行,可根据需要应用它们。
6 张量的概念及其操作初步演示
6.1 常见的深度学习框架
目前,常见的深度学习框架有TensorFlow、MindSpore和PyTorch等。
TensorFlow由Google公司于2015年开源,推动了深度学习的发展。2019年,Google公司又发布了TensorFlow2.0版,它克服了上一版思维模式不友好、不能动态调试的弊端。TensorFlow2深度学习框架支持CPU、GPU和Google自己的TPU处理器作为计算平台。但TensorFlow在2.11版之后不再支持Windows系统中的GPU作为计算平台,这一点给大部分使用Windows系统的初学者制造了一定的学习障碍。
MindSpore由华为公司于2020年开源,是国产的深度学习框架。MindSpore深度学习框架支持CPU、GPU和华为自己的昇腾Ascend处理器作为计算平台。
PyTorch由Facebook于2017年开源,它具有简洁、容易理解、可动态调试、功能强大的特点,同时其生态圈也十分丰富,有利于初学者在网上查询和讨论遇到的问题。目前,深度学习及相关领域发表的学术论文的实验大多基于PyTorch来完成,且网上有丰富的基于PyTorch完成的深度学习相关代码供学习和借鉴。2023年,华为正式宣布成为PyTorch基金会的Premier会员,这是中国首个、全球第十个PyTorch基金会最高级别会员。随着华为加入PyTorch生态圈,PyTorch可以方便地使用华为的昇腾处理器作为计算平台。因此,PyTorch是比较适合初学者的深度学习框架。在PyTorch的官网提供了详细说明文档(https://docs.pytorch.org/docs/stable/index.html),但是要理解这些文档,需要具备深度学习的基本知识,本专栏将逐步探讨这些知识。
6.2 张量
在深度学习框架中,张量(Tensor)及其操作(Operator)是最基本的数据结构。
张量是多维排列的数据。不同维度的张量分别表示不同的数据,0维张量表示标量,1维张量表示向量,2维张量表示矩阵,3维张量可以表示彩色图像的RGB三通道等等,如下图所示。
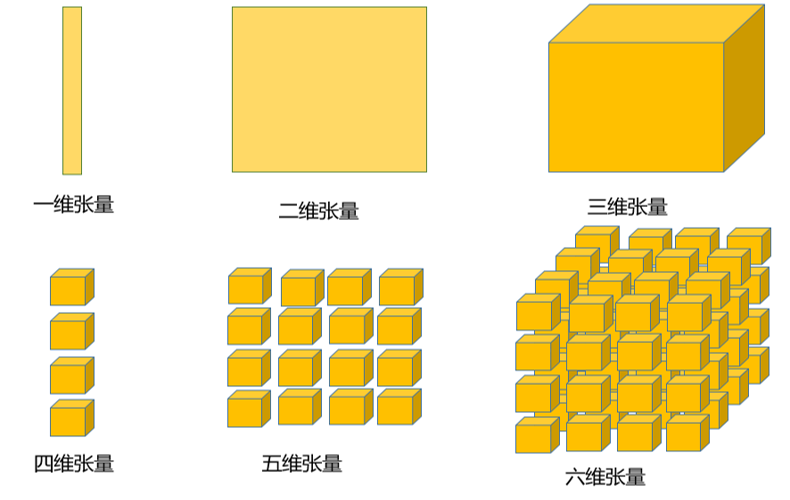
张量数据的类型与NumPy的数据类型一致,包括各类整数类型和浮点数类型。在深度学习中,一般将待处理的数据规范化为特定维度的张量。例如,在图像处理时,彩色像素点的红、绿、蓝三色值用一个3维的张量来表示,而一幅图片由多个像素点组成,因此,加上像素点的宽和高位置信息,图片可以用5维的张量来表示。
6.3 PyTorch中的tensor
PyTorch的torch是核心模块,提供了张量和操作的基本功能,是其他模块的基础。下面给出一个张量定义及其维度操作的简单示例。
### 张量的定义及维度操作
import torch
t1 = torch.tensor([1, 2]) # 定义一个张量
print(t1, "维度:", t1.dim()) # dim()方法查看张量的维度
#>>> tensor([1, 2]) 维度: 1
t2 = torch.tensor([[1], [2]])
print(t2, "维度:", t2.dim())
#>>> tensor([[1],
#>>> [2]]) 维度: 2
t3 = torch.tensor([[1, 2], [3, 4]])
print(t3, "维度:", t3.dim())
#>>> tensor([[1, 2],
#>>> [3, 4]]) 维度: 2
t4, t5 = t3.split(1, dim=0) # 按维度0将张量拆成大小为1的两个张量
print('t4:', t4)
print('t5:', t5)
#>>> t4: tensor([[1, 2]])
#>>> t5: tensor([[3, 4]])
t6, t7 = t3.split(1, dim=1) # 按维度1将张量拆成大小为1的两个张量
print('t6:', t6)
print('t7:', t7)
#>>> t6: tensor([[1],
#>>> [3]])
#>>> t7: tensor([[2],
#>>> [4]])对张量可以进行与Numpy类似的改变维数reshape、转置transpose、切片slice、索引index、拼接concat、分割splite和排序topk等操作,以及常见的加、减、乘、除和比较等运算。此类操作比较简单易懂,网上有很多相关讲解文章。与神经网络紧密相关的复杂操作,将在后续文章里逐步展开讨论。
下面给出一个对比numpy数组与tensor平方运算操作的示例。
### numpy计算
import numpy as np
np_x = np.array([1.0, 2.0, 6.0])
print("numpy output = ", np.square(np_x)) # 或者 np_x ** 2;np_x * np_x; np.power(np_x, 2)
#>>> numpy output = [ 1. 4. 36.]
### 张量的运算操作
import torch
tc_x = torch.tensor([1.0, 2.0, 6.0])
print( torch.pow(tc_x, 2) )
#>>> tensor([ 1., 4., 36.])
### 对python运算符的支持
print(np_x ** 2)
print(tc_x ** 2)
#>>> [ 1. 4. 36.]
#>>> tensor([ 1., 4., 36.])该示例从列表创建了一个张量。张量还可以从NumPy的数组创建,或者转成NumPy的数组。
随后,对该张量施加了一个求2次幂的操作,并将结果输出。
通过运算符重载,张量的操作还支持直接使用Python运算符,如示例中Python求平方的运算符可以直接作用于张量之上。


















 36万+
36万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









