




本文以手写数字识别为例,介绍了深度学习的应用流程,并对应用流程中的关键问题进行了说明,包括:训练数据和测试数据、数据预处理、模型建立和应用等,最后简要说明了深度学习的分类。
目录
1 应用示例
以一个经典的应用示例来说明深度学习应用的大概流程。
手写体数字识别应用是学习深度学习常用的入门实例。该应用所用到的MNIST数据集(http://yann.lecun.com/exdb/mnist/)是一个手写体的数字图片集,它包含有训练集和验证集,由250个人手写的数字构成。训练集包含60000个样本,验证集包含10000个样本。
训练集和验证集中的每个样本包括一张图片和一个标签,图片由个像素点构成,每个像素点用1个灰度值表示,标签是与图片对应的0到9的数字。训练集的前10张图片如下图所示,它们对应的标签分别为数字0、1、2、...、9。

深度学习一般的应用流程,是用训练集来训练出一个模型,然后用验证集来验证该模型的效果,效果好的模型才能应用于实际工作中。训练集和验证集中的样本是带有标签的,它们可以看作是提前从应用场景中采集的数据,其中蕴含了有关应用的“知识”。用训练集来训练模型,就是让模型学习到这些“知识”。用验证集来验证模型,就是看看模型是否真正学习到了这些“知识”。
与训练样本和验证样本类似的,还有测试样本。测试样本是不带标签的,它是将要在未来的应用场景进行采集的数据。深度学习的根本目的是对未来测试样本的标签做出正确的预测,从而应用于人们的生产和生活中。例如停车场的车辆号牌识别模型就要正确识别出现场采集的车牌号码,从而实现自动停车计费。
在手写体数字识别应用示例中,先要构建一个深度学习模型(通常是神经网络模型),然后用有标签的训练样本图片对深度学习模型进行训练,使模型学习到蕴含在训练样本图片中的“知识”,然后将验证样本输入模型得到预测标签,通过对比实际标签就可以评估模型的“好”或“坏”的程度。
示例代码如下所示,读者现在只需要了解流程即可,本专栏的后续文章将会对其中的细节内容深入探讨,帮助读者逐一理解其中的技术细节。
示例代码共由5部分组成(由“###+编号”区分),分别为1.导入和设置环境;2.训练样本和验证样本数据预处理;3.定义神经网络模型;4.创建模型并用训练样本对它进行训练;5.训练好的模型在验证集上的效果。
在第2部分,使用torch.utils.data.DataLoader下载了数据集,并进行了归一化、独热编码等操作,为训练和验证模型作好了准备。有关归一化和独热编码的原理细节将在本专栏后续文章中讨论。
第3部分定义了一个全连接层的神经网络模型的类,第4部分实例化该类得到一个对象,并用训练样本对它进行了训练,从输出来看,在训练样本集上的预测准确率逐渐由10.84%提高到90.20%。该部分相关内容是本专栏的核心知识,后续将逐一展开讨论。
第5部分用训练好的模型对全部验证样本进行了预测,并将预测的标签与实际标签进行了比对,发现预测准确率为90.56%。在第5部分,还演示了验证集前16个样本及其预测结果,其中有1个预测错误,如后面的图所示。
代码 2-1 MNIST应用示例1
### 1.导入和设置环境 import torch import torch.nn as nn import torch.optim as optim from torch.utils.data import DataLoader, TensorDataset import datetime from torchvision import datasets, transforms # 设置随机种子 torch.manual_seed(0) ### 2.训练样本和验证样本数据预处理 # 数据预处理方式 transform = transforms.Compose([ transforms.ToTensor(), # 转换为 torch.Tensor ]) # 加载MNIST数据集 train_dataset = datasets.MNIST('./data', train=True, download=True, transform=transform) val_dataset = datasets.MNIST('./data', train=False, transform=transform) # 样本拉平、归一化后 X_train = train_dataset.data.float().view(-1, 784) / 255.0 y_train = train_dataset.targets X_val = val_dataset.data.float().view(-1, 784) / 255.0 y_val = val_dataset.targets # 转换为独热编码 y_train = torch.nn.functional.one_hot(y_train, num_classes=10).float() y_val = torch.nn.functional.one_hot(y_val, num_classes=10).float() # 创建数据加载器 batch_size = 200 train_loader = DataLoader(TensorDataset(X_train, y_train), batch_size=batch_size, shuffle=True) val_loader = DataLoader(TensorDataset(X_val, y_val), batch_size=batch_size) ### 3.定义神经网络模型 class MNISTModel(nn.Module): def __init__(self): super(MNISTModel, self).__init__() self.fc1 = nn.Linear(784, 784) self.fc2 = nn.Linear(784, 784) self.fc3 = nn.Linear(784, 10) self.sigmoid = nn.Sigmoid() def forward(self, x): x = self.sigmoid(self.fc1(x)) x = self.sigmoid(self.fc2(x)) x = self.fc3(x) return x ### 4.创建模型并用训练样本对它进行训练 model = MNISTModel() # 实例化模型类得到模型对象 criterion = nn.CrossEntropyLoss() # 定义损失函数 optimizer = optim.SGD(model.parameters(), lr=0.15) # 定义优化器 # 训练模型,开始计时 start_time = datetime.datetime.now() epochs = 10 for epoch in range(epochs): # 每轮中的训练 model.train() train_loss = 0.0 for batch_X, batch_y in train_loader: optimizer.zero_grad() outputs = model(batch_X) loss = criterion(outputs, batch_y) loss.backward() optimizer.step() train_loss += loss.item() # 看一下该轮训练后的效果 model.eval() correct = 0 total = 0 with torch.no_grad(): for batch_X, batch_y in train_loader: outputs = model(batch_X) _, predicted = torch.max(outputs.data, 1) # 模型预测值的独热编码 _, labels = torch.max(batch_y.data, 1) # 真实标签值的独热编码 total += labels.size(0) correct += (predicted == labels).sum().item() # 准确率 print(f'Epoch {epoch+1}/{epochs}, 对训练样本进行预测的准确率(Train Acc): {100*correct/total:.2f}%') # 训练结束,终止计时 end_time = datetime.datetime.now() print(f"训练用时: {end_time - start_time}") #>>> Epoch 1/10, 对训练样本进行预测的准确率(Train Acc): 10.84% #>>> Epoch 2/10, 对训练样本进行预测的准确率(Train Acc): 69.08% #>>> ... #>>> Epoch 10/10, 对训练样本进行预测的准确率(Train Acc): 90.20% #>>> 训练用时: 0:01:15.719202 ### 5.训练好的模型在验证集上的效果 # 在验证集上进行预测 model.eval() val_correct = 0 val_total = 0 with torch.no_grad(): for batch_X, batch_y in val_loader: outputs = model(batch_X) _, predicted = torch.max(outputs.data, 1) _, labels = torch.max(batch_y.data, 1) val_total += labels.size(0) val_correct += (predicted == labels).sum().item() print(f'对验证样本进行预测的准确率(val Acc): {100*val_correct/val_total:.2f}%') #>>> 对验证样本进行预测的准确率(val Acc): 90.56% # 用16个验证样本进行预测效果可视化 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei', 'DejaVu Sans'] # 用黑体,如果找不到就用DejaVu Sans plt.rcParams['axes.unicode_minus'] = False # 解决负号显示问题 model.eval() with torch.no_grad(): # 取前16个验证样本 sample_data = X_val[:16] sample_labels = y_val[:16] predictions = model(sample_data) _, predicted_labels = torch.max(predictions, 1) _, true_labels = torch.max(sample_labels, 1) fig, axes = plt.subplots(4, 4, figsize=(10, 10)) for i, ax in enumerate(axes.flat): ax.imshow(sample_data[i].reshape(28, 28), cmap='gray') ax.set_title(f'真实标签: {true_labels[i]}, 预测标签: {predicted_labels[i]}') ax.axis('off') plt.tight_layout() plt.show() #>>> 输出见下图

2 深度学习典型应用流程
一个典型的深度学习应用流程通常可分为采集训练数据、预处理数据、建立模型和应用四个主要阶段,如下图所示。
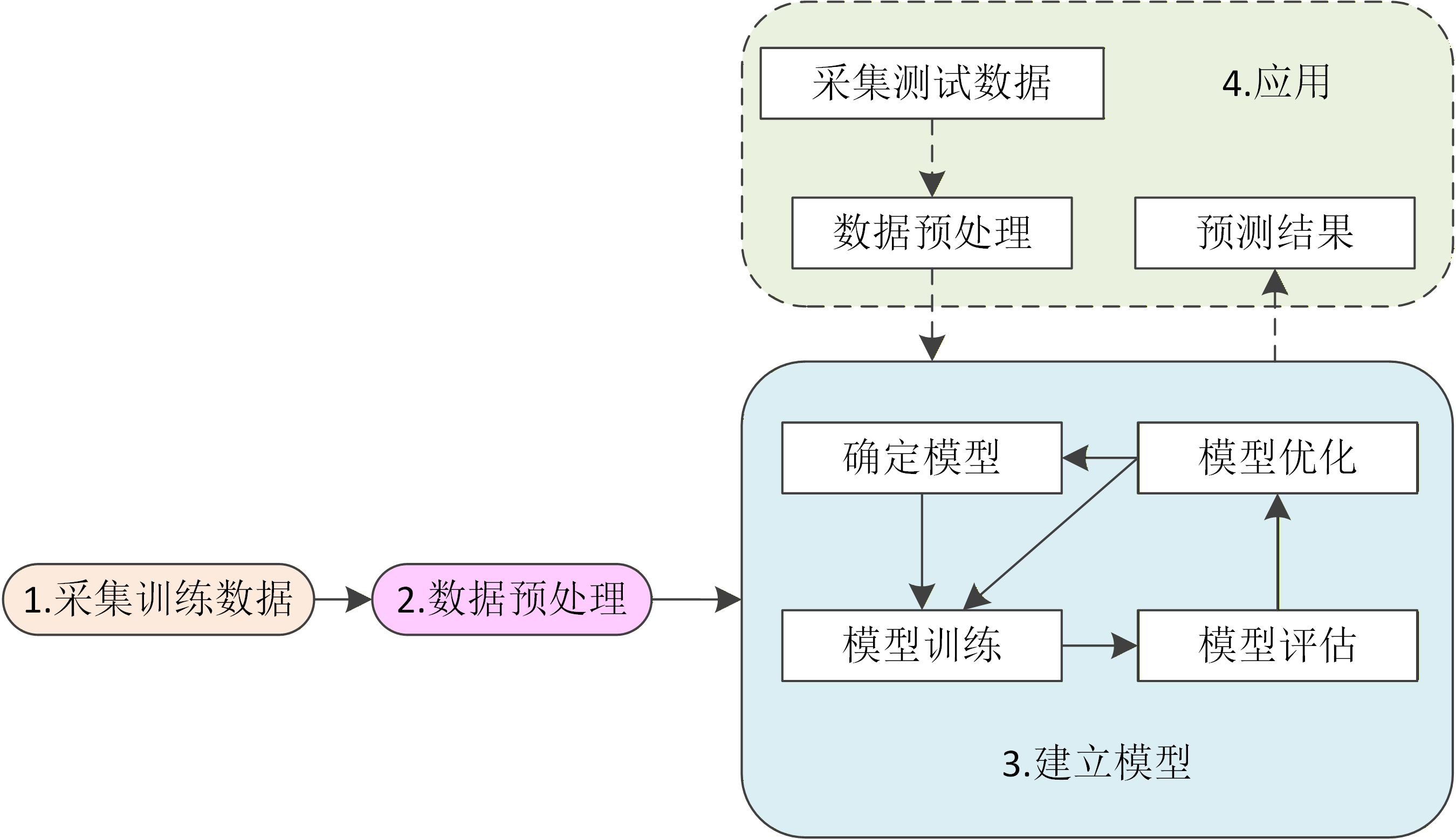
通过各种的手段采集到的训练数据,经过预处理后,得到建立模型所需要的格式化数据。将这些数据用于训练模型,等模型成功建立起来后,就可以进行应用。
应用阶段又包括采集测试数据、特征工程、模型预测三个子阶段,如图中虚线框所示。在应用阶段,采集到的测试数据经过预处理后,得到应用模型所需要的格式化数据,输入模型后,得到预测结果。
上述应用流程中有一些重要概念需要进一步解释。
-
1.训练数据和测试数据
训练数据是用来训练模型的数据,它包括训练样本和验证样本。测试数据是模型服务的对象,对测试样本作出正确的预测是深度学习(包括机器学习)一系列活动的最终目的。
数据的类型不仅包括格式化的数据,还包括文本、视频、音频等非格式化的数据。对它们的采集手段多种多样,一般要用到现代化的信息采集手段,如扫描仪、摄像头、传感器等等。
-
2.数据预处理
数据预处理是将训练数据和测试数据整理成有利于训练模型的工作。如上面手写体数字识别的示例中,对训练数据进行了归一化和独热编码等操作。对数据进行预先处理是训练模型的重要环节。对数据进行预处理的常用操作将在后文专门讨论。
在传统的机器学习方法中,数据预处理具有特别重要的意义,它不仅包含对数据的整理,还包含从数据中提取有利于模型训练的特征的工作(称之为特征工程)。这里的特征是指蕴含在数据中的体现规律性的某项特质,例如,对于一个预测购物的模型训练,把训练样本中的时间由某年某月某日原始数据改为是否周末特征,可能更有利于模型理解是否购物与时间的关系。传统机器学习模型(树、森林、朴素贝叶斯等非多层神经网络模型)的效果对“好”的特征的依赖非常大,特征提取是建模中非常重要的环节,对预测结果影响很大。对于文本、图像、语音等复杂数据,人工提取特征是非常困难的事情。为了追求好的效果,人们曾经想了很多办法来提取它们的特征,提取出的特征数量甚至达到了上万个。
近年来,以人工神经网络为基础的深度学习在自然语言处理、图像识别、语音识别等领域的自动提取特征研究取得了的重大突破。正是在以神经网络为基础的深度学习为特征提取问题提供了有效的解决方法之后,机器学习才得以异军突起,得到广泛应用。深度学习带来的革命性变化是弥合了从底层具体数据到高层抽象概念之间的鸿沟,使得学习过程可以自动从大量训练数据中学习特征,不再需要过多人工干预,实现了所谓的端到端(end to end)学习。
-
3.建立模型
建立模型就是从训练数据生成模型,并用于对测试数据进行预测。
建立模型,首先要确定建立什么样的模型。深度学习的模型是很多层的神经网络模型。神经网络模型由两部分组成,分别是网络的结构和网络的参数。神经网络的结构设计一直没有完善的理论指导,基本处于摸索的状态,即通过在实践中试验得到“好用”的结构。目前有很多人在研究有关神经网络结构设计的理论,但仍然没有见到公开发表的突破性成就。
而通过训练模型确定模型参数的研究则在近年取得了重要的进展,正是这些进展才使得深度学习得以迅速发展和应用,取得辉煌成就。有关多层神经网络的内容是本专栏的重点,将在后续文章中逐步讨论。
通过确定模型结构、训练模型参数后,模型一般还需要进行评估。只有评估为合格的模型才能真正投入生产和生活实际应用。
评估不合格的模型则需要进行优化,优化可以是人工调整某些重要参数,也可以是重新确定模型结构,也可以是增加训练样本重新训练。
优化过的模型要重新训练和评估。一般要经过多轮过程才能得到满意的模型。
3 深度学习模型分类
3.1 从学习过程特点来分类
在机器学习领域,从学习的过程特点来看,机器学习可以分为监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)和半监督学习(Semi-supervised Learning)等类别。
监督学习学习中,模型训练用的样本是所谓的有标签(Label)数据。有标签数据是指已经给出明确标记的数据,手写体数字识别示例中,每张数字图片都有一个对应数字的标签。监督学习利用有标签的训练数据来训练模型,目标是用该模型给未标记的测试数据打上标签。
与监督学习不同,无监督学习的训练样本没有标签,它自动从训练数据中学习知识,建立模型。无监督学习也称为无指导学习。在大多数工程应用中,事先标记大量的训练数据是一件代价很大的工作,因此,无监督学习在机器学习中具有重要作用。
半监督学习是监督学习和无监督学习相结合的一种学习方法,它利用少量已标记样本的帮助来对大量未标记样本进行标记。
作为机器学习的子领域,深度学习应用最多的是监督学习。
3.2 从学习对象来分类
从学习对象来看,可以分为序列数据和非序列数据。
输入模型的样本一般是由多个分量组成。例如,在手写体数字识别示例中,一次输入模型的是一张图片,它是个像素点组成的,因此它有784个分量。
如果样本的分量之间存在前后关联关系,则称为序列的。例如在处理语言文本的模型中,输入模型的汉语句子中的字是有前后关联关系的。
如果样本的分量之间不存在前后关联关系,则称为非序列的。例如,一条描述房屋属性的样本数据,可能包括房屋的卧室数量、卫生间数量、房屋的大小、房屋地下室的大小、房屋的外观、房屋的修建时间、房屋的翻修时间、房屋的位置等。
3.2 从应用任务来分类
常见的深度学习应用任务有分类、标注、回归等。
1.分类(Classification)
分类是机器学习应用中最为广泛的任务,它用于将某个事物判定为属于预先设定的多个类别中的某一个,例如,根据花瓣的若干特征来判断该花属于哪一种花,根据顾客的行为特征来判断该顾客是否会购买商品等。
对序列数据来说,分类的应用也很常见,比如垃圾邮件分类、影评情感分类等应用。在这些应用中,输入模型的是由有次序关系的字、词组成的语句文本,模型输出的是预先设定的某个类别,例如是否垃圾邮件、是否负面电影评价。
分类属于监督学习,数据的标签是预设的类别号。分类模型分为二分类和多分类的。如果要预测明天是否下雨,则是一个二分类问题,如果要预测是阴、晴还是雨,则是一个三(多)分类问题。
2.回归(Regression)
回归预测的不是属于哪一类,而是什么值,可以看作是将分类模型的类别数量无限增加,即标签值不再只是几个离散的值了,而是连续的值。例如,根据以往的数据来预测指定温度和湿度时某草地上小花朵的数据,就是回归应用的例子。
回归问题在序列数据上的应用也很多,如根据过去若干天的气温来预测明天的气温是多少度,因为温度的一个连续的值,所以这是一个回归模型要解决的问题。
常见应用中,回归模型主要用于各种数据的预测,比如机场客流量分布预测、音乐流行趋势预测、微博互动量预测、电影票房预测、产品价格预测、网约车出行流量预测等等。
回归也属于监督学习。
3.标注(Tagging)
标注是序列数据特有的应用。输入标注模型的是序列数据,标注模型输出的也是序列数据。例如,在自然语言处理的词性标注任务中,需要对每一个词标出它的词性,假如输入的序列是(我 爱 自然 语言 处理),输出的正确序列是(代词 动词 名词 名词 动词),如下图所示。输出序列是对应的输入词的词性标签。

自然语言处理领域的问题大多是标注问题,例如给汉字加注拼音、将句子分词等等。
可以认为标注问题是分类问题的一个推广,它也属于监督学习范畴。


















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









