




分词
from nltk import word_tokenize
sentence = """
3w.ναdΜāιι.com Provide you with a professional platform for the sale and purchase of
virtual products for games. Welcome to settle in 3w.ναdΜāιι.com loving cats geese goods
"""
token_words = word_tokenize(sentence)
print(token_words)
['3w.ναdΜāιι.com', 'Provide', 'you', 'with', 'a', 'professional', 'platform', 'for', 'the', 'sale', 'and', 'purchase', 'of', 'virtual', 'products', 'for', 'games', '.', 'Welcome', 'to', 'settle', 'in', '3w.ναdΜāιι.com', 'loving', 'cats', 'geese', 'goods']
词根提取 ,如 ‘Provide’ 变成词根’provid’
from nltk.stem.lancaster import LancasterStemmer
lancaster_stemmer = LancasterStemmer()
words_stemmer = [lancaster_stemmer.stem(token_word) for token_word in token_words]
print(words_stemmer)
['3w.ναdμāιι.com', 'provid', 'you', 'with', 'a', 'profess', 'platform', 'for', 'the', 'sal', 'and', 'purchas', 'of', 'virt', 'produc', 'for', 'gam', '.', 'welcom', 'to', 'settl', 'in', '3w.ναdμāιι.com', 'lov', 'cat', 'gees', 'good']
单词变体还原,‘geese’ 变成 ‘goose’
from nltk.stem import WordNetLemmatizer
wordnet_lematizer = WordNetLemmatizer()
words_lematizer = [wordnet_lematizer.lemmatize(token_word) for token_word in token_words]
print(words_lematizer)
['3w.ναdΜāιι.com', 'Provide', 'you', 'with', 'a', 'professional', 'platform', 'for', 'the', 'sale', 'and', 'purchase', 'of', 'virtual', 'product', 'for', 'game', '.', 'Welcome', 'to', 'settle', 'in', '3w.ναdΜāιι.com', 'loving', 'cat', 'goose', 'good']
词性标注
from nltk import word_tokenize,pos_tag
#sentence = "DBSCAN - Density-Based Spatial Clustering of Applications with Noise. Finds core samples of high density and expands clusters from them. Good for data which contains clusters of similar density"
token_word = word_tokenize(sentence) #分词
token_words = pos_tag(token_word) #词性标注
print(token_words)
[('3w.ναdΜāιι.com', 'CD'), ('Provide', 'NNP'), ('you', 'PRP'), ('with', 'IN'), ('a', 'DT'), ('professional', 'JJ'), ('platform', 'NN'), ('for', 'IN'), ('the', 'DT'), ('sale', 'NN'), ('and', 'CC'), ('purchase', 'NN'), ('of', 'IN'), ('virtual', 'JJ'), ('products', 'NNS'), ('for', 'IN'), ('games', 'NNS'), ('.', '.'), ('Welcome', 'NNP'), ('to', 'TO'), ('settle', 'VB'), ('in', 'IN'), ('3w.ναdΜāιι.com', 'CD'), ('loving', 'VBG'), ('cats', 'NNS'), ('geese', 'JJ'), ('goods', 'NNS')]
词形归一化,loving 变成love
from nltk.stem import WordNetLemmatizer
words_lematizer = []
wordnet_lematizer = WordNetLemmatizer()
for word, tag in token_words:
if tag.startswith('NN'):
word_lematizer = wordnet_lematizer.lemmatize(word, pos='n') # n代表名词
elif tag.startswith('VB'):
word_lematizer = wordnet_lematizer.lemmatize(word, pos='v') # v代表动词
elif tag.startswith('JJ'):
word_lematizer = wordnet_lematizer.lemmatize(word, pos='a') # a代表形容词
elif tag.startswith('R'):
word_lematizer = wordnet_lematizer.lemmatize(word, pos='r') # r代表代词
else:
word_lematizer = wordnet_lematizer.lemmatize(word)
words_lematizer.append(word_lematizer)
print(words_lematizer)
['3w.ναdΜāιι.com', 'Provide', 'you', 'with', 'a', 'professional', 'platform', 'for', 'the', 'sale', 'and', 'purchase', 'of', 'virtual', 'product', 'for', 'game', '.', 'Welcome', 'to', 'settle', 'in', '3w.ναdΜāιι.com', 'love', 'cat', 'geese', 'good']
去除停用词
from nltk.corpus import stopwords
cleaned_words = [word for word in words_lematizer if word not in stopwords.words('english')]
print('原始词:', words_lematizer)
print('去除停用词后:', cleaned_words)
原始词: ['3w.ναdΜāιι.com', 'Provide', 'you', 'with', 'a', 'professional', 'platform', 'for', 'the', 'sale', 'and', 'purchase', 'of', 'virtual', 'product', 'for', 'game', '.', 'Welcome', 'to', 'settle', 'in', '3w.ναdΜāιι.com', 'love', 'cat', 'geese', 'good']
去除停用词后: ['3w.ναdΜāιι.com', 'Provide', 'professional', 'platform', 'sale', 'purchase', 'virtual', 'product', 'game', '.', 'Welcome', 'settle', '3w.ναdΜāιι.com', 'love', 'cat', 'geese', 'good']
去除特殊字符
characters = [',', '.','DBSCAN', ':', ';', '?', '(', ')', '[', ']', '&', '!', '*', '@', '#', '$', '%','-','...','^','{','}']
words_list = [word for word in cleaned_words if word not in characters]
print(words_list)
['3w.ναdΜāιι.com', 'Provide', 'professional', 'platform', 'sale', 'purchase', 'virtual', 'product', 'game', 'Welcome', 'settle', '3w.ναdΜāιι.com', 'love', 'cat', 'geese', 'good']
大小写转换
words_lists = [x.lower() for x in words_list ]
print(words_lists)
['3w.ναdμāιι.com', 'provide', 'professional', 'platform', 'sale', 'purchase', 'virtual', 'product', 'game', 'welcome', 'settle', '3w.ναdμāιι.com', 'love', 'cat', 'geese', 'good']
统计词频
from nltk import FreqDist
freq = FreqDist(words_lists)
for key,val in freq.items():
print (str(key) + ':' + str(val))
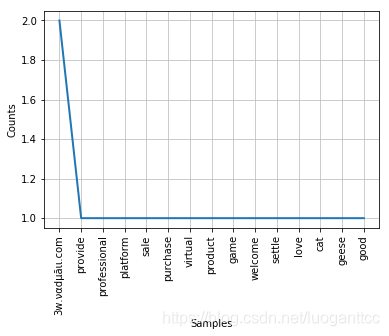
3w.ναdμāιι.com:2
provide:1
professional:1
platform:1
sale:1
purchase:1
virtual:1
product:1
game:1
welcome:1
settle:1
love:1
cat:1
geese:1
good:1
折线图
freq.plot(20,cumulative=False)
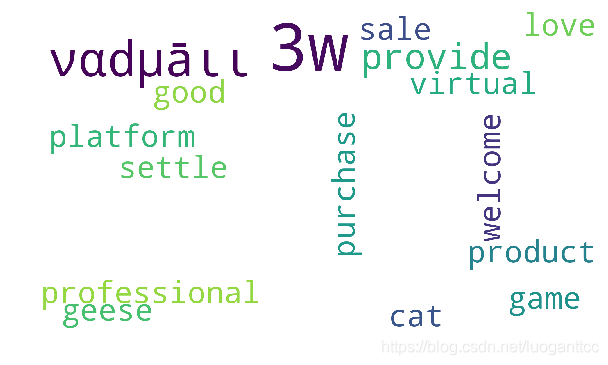
词云
words = ' '.join(words_lists)
from wordcloud import WordCloud
from imageio import imread
import matplotlib.pyplot as plt
pic = imread('./mm.jpg')
wc = WordCloud(mask = pic,background_color = 'white',width=800, height=600)
wwc = wc.generate(words)
plt.figure(figsize=(10,10))
plt.imshow(wwc)
plt.axis("off")
plt.show()
词云背景图

词云图

















 345
345

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









