







在当今高并发、分布式系统成为主流的时代背景下,Java作为企业级应用开发的主力语言,其并发编程模型正经历着一场深刻的变革。JEP 480(结构化并发)作为Java并发编程领域的重要演进,代表了从传统线程池到现代结构化编程范式的转变。本文将深入剖析JEP 480的架构设计,追溯其技术演进历程,通过生活化案例和代码示例展示其核心价值,并探讨其对未来Java并发编程的影响。我们将从传统并发模型的问题出发,逐步揭示结构化并发如何通过引入任务作用域的概念,解决线程泄漏、取消延迟等长期困扰开发者的难题,最终实现并发代码的可维护性、可靠性和可观察性的全面提升。
传统并发模型的困境与挑战
在深入探讨JEP 480之前,我们有必要先理解传统Java并发模型存在的问题。自Java 5引入java.util.concurrent包以来,ExecutorService和Future已成为Java并发编程的基石。然而,随着系统复杂度的提升,这些传统并发构造逐渐暴露出诸多局限性,特别是在错误处理和资源管理方面。
非结构化并发的典型问题
让我们从一个典型的并发场景开始:服务器应用中处理用户请求的任务需要并发执行两个子任务——查找用户信息(findUser())和获取订单详情(fetchOrder())。传统实现可能如下:
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = esvc.submit(() -> findUser());
Future<Integer> order = esvc.submit(() -> fetchOrder());
String theUser = user.get(); // 连接findUser
int theOrder = order.get(); // 连接fetchOrder
return new Response(theUser, theOrder);
}
这段看似简单的代码隐藏着几个严重问题:
-
线程泄漏风险:当
findUser()抛出异常时,handle()会在user.get()处抛出异常,但fetchOrder()会继续在后台线程中运行,造成资源浪费。这就像Jeep车队在越野探险时,如果领队车抛锚了,其他车辆仍会继续前进,导致车队分散,难以管理。 -
取消传播缺失:如果执行
handle()的线程被中断,中断不会自动传播到子任务。findUser()和fetchOrder()线程会继续运行,形成“僵尸线程”。类似Jeep车队中,如果指挥中心发出紧急停止信号,但某些车辆通信设备故障,无法接收指令,继续危险行驶。 -
响应延迟:如果
findUser()执行时间很长,而fetchOrder()快速失败,handle()仍需等待findUser()完成后才能处理fetchOrder()的失败,导致不必要的延迟。这如同Jeep车队中一辆车陷入泥潭,其他车辆必须等待救援完成才能继续前进,即使前方道路已经畅通。
问题根源分析
这些问题的根本原因在于任务间缺乏显式的结构化关系。在传统并发模型中:
-
任务与子任务的关系仅存在于开发者脑海中,运行时系统无法感知这种逻辑关系
-
任何线程都可以向
ExecutorService提交工作,任何线程都可以等待Future的结果 -
子任务的生命周期不受父任务约束,可以比父任务存活更长时间
-
错误传播路径不明确,需要开发者手动管理取消逻辑
这种“自由形式”的并发模式虽然灵活,但违背了软件开发的基本原则——代码结构应该反映运行时行为。在单线程代码中,方法调用栈天然形成了任务-子任务的层次结构,而传统并发模型破坏了这种自然的结构。
单线程与并发代码的对比
对比单线程版本的handle()方法,其结构清晰可见:
Response handle() throws IOException {
String theUser = findUser(); // 子任务1
int theOrder = fetchOrder(); // 子任务2
return new Response(theUser, theOrder);
}
在这个版本中:
-
任务-子任务关系通过代码块结构明确体现
-
findUser()完成后才会开始fetchOrder() -
如果
findUser()失败,fetchOrder()根本不会执行 -
所有子任务必须在父任务完成前结束
这种结构化的执行流程正是JEP 480希望在并发编程中恢复的特性。
传统解决方案及其局限性
面对这些问题,开发者通常尝试以下解决方案:
手动取消:使用try-finally包裹任务,在失败时显式取消其他子任务:
Response handle() throws ExecutionException, InterruptedException {
Future<String> user = null;
Future<Integer> order = null;
try {
user = esvc.submit(() -> findUser());
order = esvc.submit(() -> fetchOrder());
String theUser = user.get();
int theOrder = order.get();
return new Response(theUser, theOrder);
} catch (Exception e) {
if (user != null) user.cancel(true);
if (order != null) order.cancel(true);
throw e;
}
}
这种方法虽然解决了部分问题,但代码变得冗长且容易出错,逻辑意图被样板代码淹没。
ExecutorService生命周期管理:使用try-with-resources管理ExecutorService:
try (ExecutorService esvc = Executors.newVirtualThreadPerTaskExecutor()) {
Future<String> user = esvc.submit(() -> findUser());
Future<Integer> order = esvc.submit(() -> fetchOrder());
// ...
}
这解决了线程泄漏问题,但无法处理子任务间的协调取消。
这些解决方案都不够理想,因为它们都违背了结构化编程的基本原则——代码块结构应该反映程序运行时行为。我们需要一种能够将并发任务组织成明确层次结构的新模型,这正是JEP 480结构化并发的核心目标。
结构化并发核心设计解析
JEP 480提出的结构化并发(Structured Concurrency)从根本上重构了Java的并发编程模型。其核心思想是将并发任务组织成明确的层次结构,使得任务与子任务之间的关系在代码结构和运行时行为中都清晰可见。这种设计借鉴了单线程编程中天然存在的调用栈层次,将其扩展到并发领域。
架构设计理念
结构化并发的架构设计建立在几个关键理念之上:
-
任务作用域(Scope)边界:每个并发任务都在一个明确的作用域内执行,作用域定义了任务的生命周期边界。这与Jeep车队探险时的“编组”概念类似——所有车辆必须在指定区域内活动,超出范围即视为异常。
-
父子任务关系:子任务必须在其父任务的作用域内创建和执行,父任务必须等待所有子任务完成后才能结束。这确保了任务结构的完整性,就像Jeep车队中的领队车必须确保所有成员车辆完成当前路段才能宣布阶段完成。
-
错误传播与取消协调:任何子任务的失败都会自动触发同级子任务的取消,并最终导致父任务失败。这类似于Jeep车队中任何一辆车出现故障,整个车队都会停下来协调处理。
-
可观察性增强:任务层次结构在运行时具体化,可以通过监控工具直观查看。这解决了传统并发模型中“线程转储难以理解”的问题,就像Jeep车队每辆车都配备GPS追踪器,指挥中心可以清晰掌握每辆车的位置和状态。
核心API设计
JEP 480引入了StructuredTaskScope作为核心抽象,其主要API包括:
public class StructuredTaskScope<T> implements AutoCloseable {
public <U extends T> Subtask<U> fork(Callable<? extends U> task);
public void join() throws InterruptedException;
public void shutdown();
public void close();
protected void handleComplete(Subtask<? extends T> subtask);
// ... 其他方法
}
关键组件解析:
-
fork():替代
ExecutorService.submit(),用于启动子任务,返回Subtask而非Future。Subtask提供了更丰富的子任务状态查询能力。 -
join():等待所有子任务完成,可以抛出
InterruptedException响应中断。 -
shutdown():请求取消所有未完成的子任务。
-
close():继承自
AutoCloseable,确保作用域结束时资源被清理。 -
handleComplete():模板方法,子类可以覆盖以实现自定义完成处理逻辑。
任务生命周期状态机
结构化并发中的任务生命周期比传统Future更加精细,Subtask的状态转换如下:
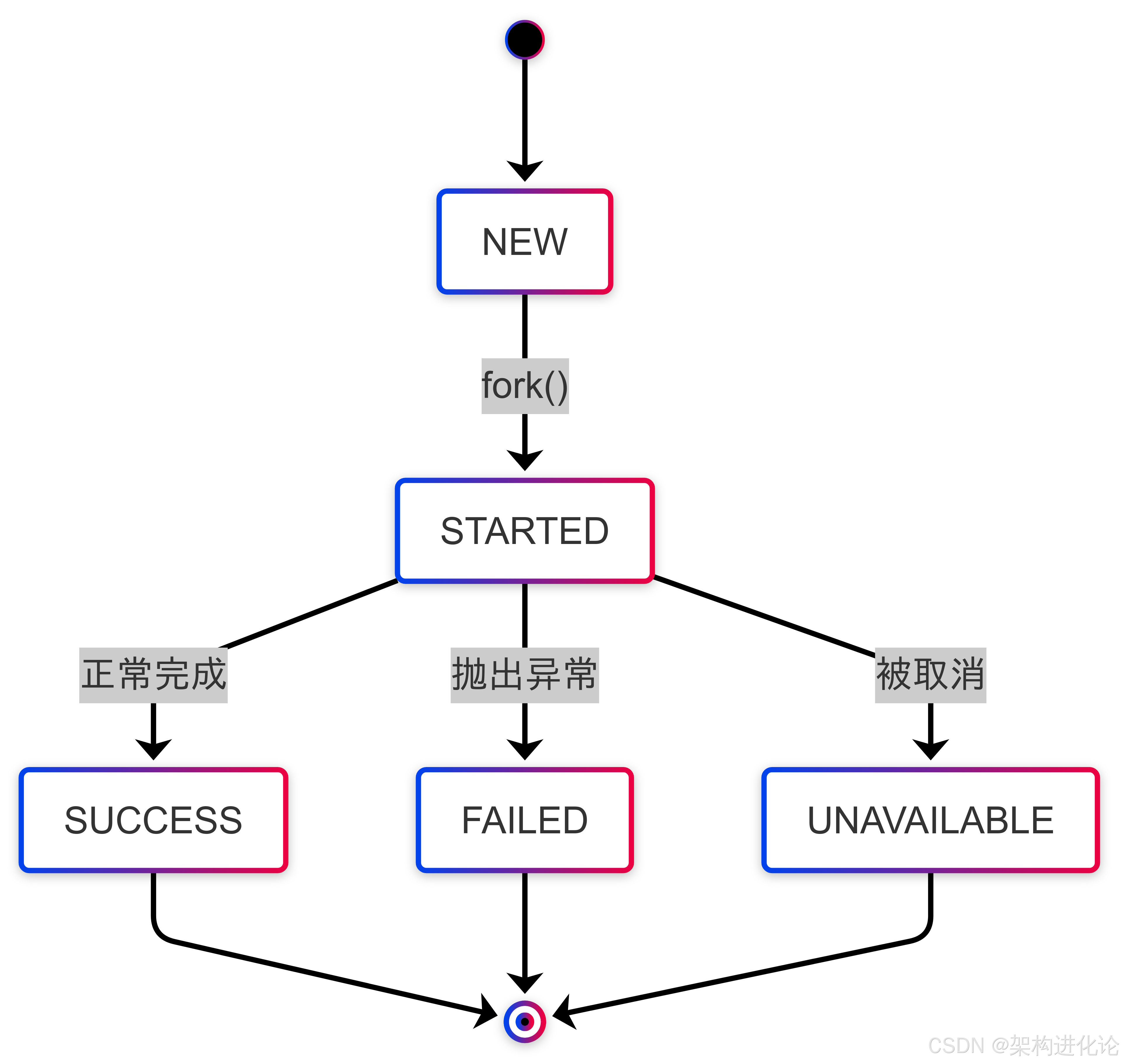
这种明确的状态机设计使得任务监控和调试更加直观,每个子任务的最终状态都能被准确追踪。
结构化并发的数学基础
结构化并发背后的理论可以部分用有向无环图(DAG)来描述。设任务系统为,其中:
-
是所有任务的集合
-
是任务间的父子关系边
-
对于任意边
,
是
的父任务
关键约束条件:
这个公式确保了任务系统的结构化特性——没有“游离”的任务,所有任务都有明确的父任务和生命周期边界。
设计模式对比
与传统并发模型相比,结构化并发引入了新的设计模式:
| 设计维度 | 传统并发模型 | 结构化并发模型 |
|---|---|---|
| 任务组织 | 自由形式,无强制结构 | 严格的层次结构 |
| 错误处理 | 手动传播和取消 | 自动传播和协调取消 |
| 生命周期管理 | 分散,易泄漏 | 集中,自动清理 |
| 可观察性 | 线程转储难以理解 | 明确的任务层次关系 |
| 适用场景 | 任意复杂并发模式 | 逻辑上相关的任务组 |
这种模式转变类似于从“自由越野”到“有组织探险”的转变——Jeep车队从各车随意行驶变为有明确路线和纪律的编队行进。
结构化并发实战应用
理解了结构化并发的设计理念后,让我们通过实际代码示例来展示其强大能力。我们将从基础用法开始,逐步深入到高级模式,并结合生活化案例帮助理解这种新型并发范式。
基础使用模式
使用StructuredTaskScope重写之前的handle()方法,代码变得更加结构化和安全:
Response handle() throws ExecutionException, InterruptedException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<String> user = scope.fork(() -> findUser());
Subtask<Integer> order = scope.fork(() -> fetchOrder());
scope.join(); // 等待所有子任务完成
scope.throwIfFailed(); // 如果有任何失败,抛出异常
return new Response(user.get(), order.get());
}
}
这段代码的关键改进:
-
自动资源清理:使用try-with-resources确保作用域结束时所有线程被清理,杜绝线程泄漏。
-
协调取消:如果任一子任务失败,另一个会自动被取消,避免无用工作。
-
明确的结构:任务-子任务关系通过代码块结构清晰可见。
这与Jeep车队的管理方式异曲同工——领队(父任务)组织多辆车(子任务)同时探索不同路线,但任何一辆车发现问题(失败)都会通知领队,领队则立即召回其他车辆(取消)。
自定义策略实现
StructuredTaskScope支持通过子类化实现自定义策略。例如,实现“第一个成功结果”模式:
class FirstSuccess<T> extends StructuredTaskScope<T> {
private volatile T result;
private volatile Throwable exception;
@Override
protected void handleComplete(Subtask<? extends T> subtask) {
if (subtask.state() == Subtask.State.SUCCESS && result == null) {
result = subtask.get();
shutdown(); // 第一个成功,取消其余任务
}
}
public T getResult() throws Throwable {
if (result != null) return result;
if (exception != null) throw exception;
throw new IllegalStateException("No result available");
}
}
// 使用示例
String fetchFromAnyServer() throws Throwable {
try (var scope = new FirstSuccess<String>()) {
scope.fork(() -> queryServerA());
scope.fork(() -> queryServerB());
scope.fork(() -> queryServerC());
scope.join();
return scope.getResult();
}
}
这种模式适用于需要从多个冗余服务获取数据,但只需要第一个成功响应的场景。类似Jeep车队派出侦察车探索多条路线,只要有一条路线被确认可行,就召回其他侦察车。
与虚拟线程的协同
JEP 480与JEP 444(虚拟线程)完美协同,形成强大的轻量级并发组合:
Response handleConcurrentRequests(List<Request> requests) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
List<Subtask<Result>> subtasks = requests.stream()
.map(request -> scope.fork(() -> processRequest(request)))
.toList();
scope.join();
scope.throwIfFailed();
return combineResults(subtasks.stream().map(Subtask::get).toList());
}
}
虚拟线程提供了廉价的线程资源,结构化并发提供了良好的组织结构,二者结合可以轻松实现“一请求一线程”的高并发模式,同时保持代码的清晰和可靠。
异常处理模式
结构化并发改进了异常处理模式,使得错误传播更加符合直觉:
void processOrder(Order order) throws OrderException {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<Inventory> inventory = scope.fork(() -> checkInventory(order));
Subtask<Payment> payment = scope.fork(() -> processPayment(order));
Subtask<Shipping> shipping = scope.fork(() -> scheduleShipping(order));
try {
scope.join();
scope.throwIfFailed();
// 所有子任务成功,提交订单
commitOrder(inventory.get(), payment.get(), shipping.get());
} catch (InterruptedException e) {
// 处理中断
throw new OrderException("Order processing interrupted", e);
} catch (ExecutionException e) {
// 提取原始异常并处理
Throwable cause = e.getCause();
if (cause instanceof InventoryException) {
throw new OrderException("Inventory check failed", cause);
} else if (cause instanceof PaymentException) {
throw new OrderException("Payment processing failed", cause);
} // ...其他异常处理
}
}
}
这种模式确保了无论哪个子环节出现问题,整个订单处理流程都能优雅地失败,并清理所有资源。类似Jeep车队中任何一辆车出现故障,整个探险计划都会重新评估,而不是盲目继续。
性能考量与最佳实践
虽然结构化并发引入了额外的协调开销,但在大多数场景下这些开销可以忽略不计,特别是与虚拟线程配合使用时。以下是一些性能优化建议:
-
合理设置作用域粒度:不要为每个小任务创建新作用域,而应将相关任务分组到同一作用域。
-
避免阻塞父任务:父任务应尽快调用
join(),避免在fork和join之间执行耗时操作。 -
合理使用关闭策略:根据场景选择
ShutdownOnFailure(任一失败则全部取消)或ShutdownOnSuccess(任一成功则全部取消)。 -
监控任务执行时间:使用
Subtask的状态信息监控任务执行时间,识别性能瓶颈。
这些实践类似于Jeep车队管理中的经验——合理分组车辆、明确指挥链、及时监控各车状态。
技术演进与行业影响
结构化并发并非Java独有的创新,而是编程语言和并发模型演进过程中的重要里程碑。理解JEP 480在技术演进史中的位置,有助于我们把握未来并发编程的发展方向。
Java并发模型的演进历程
Java的并发模型经历了几个重要的发展阶段:
-
原始线程阶段(Java 1.0):直接使用
Thread类和synchronized关键字,并发控制完全由开发者手动管理。 -
Executor框架阶段(Java 5):引入
ExecutorService和Future,提供了线程池和任务抽象,大大简化了并发编程。 -
Fork/Join框架阶段(Java 7):针对可分治问题引入工作窃取算法,适合计算密集型任务。
-
CompletableFuture阶段(Java 8):引入异步编程模型,支持链式调用和组合操作。
-
虚拟线程阶段(Java 19, JEP 425):提供轻量级线程,大幅降低线程创建和上下文切换开销。
-
结构化并发阶段(Java 19孵化, Java 21预览):引入任务作用域概念,将并发任务组织为层次结构。
JEP 480代表了Java并发模型的最新演进方向——在提供高并发能力的同时,保持代码的结构化和可维护性。这与Jeep品牌从纯粹越野向“全场景生活方式”的演进异曲同工——既要保持核心能力,又要适应更广泛的使用场景。
与其他语言/框架的对比
结构化并发概念并非Java首创,多种语言和框架已有类似实现:
| 语言/框架 | 实现方式 | 特点 |
|---|---|---|
| Kotlin | 协程+结构化并发原语 | 深度集成到语言中,语法简洁 |
| Go | goroutine+context | 通过context包传递取消信号 |
| Python | asyncio.TaskGroup | 类似Java的StructuredTaskScope |
| C++ | std::stop_token | 提供取消传播机制但结构较弱 |
Java的结构化并发实现特点在于:
-
渐进式演进:保持与现有并发API的兼容性
-
虚拟线程集成:与JEP 444虚拟线程深度协同
-
可观察性强:提供丰富的任务状态信息
对系统架构的影响
结构化并发将对Java系统架构产生深远影响:
-
微服务通信模式:简化服务间并行调用模式,如扇出(fan-out)调用多个下游服务。
-
资源泄漏防护:自动化的生命周期管理减少因异常路径导致的资源泄漏。
-
可调试性提升:明确的任务层次结构使生产环境问题诊断更加直观。
-
响应式编程融合:可能与Reactive Streams等响应式编程模型找到结合点。
这些改进如同Jeep从单一越野功能向“全路况+智能化”转型,扩展了适用场景同时保持了核心优势。
性能与扩展性考量
结构化并发在性能方面的表现:
-
虚拟线程协同:与虚拟线程配合使用时,创建数百万个并发任务成为可能。
-
协调开销:任务协调引入的额外开销在大多数场景可忽略不计。
-
资源利用率:自动化的取消机制避免了无用计算,提高了整体资源利用率。
性能模型可表示为:
其中是最慢子任务的执行时间,
是固定的协调开销。
采用路线图建议
对于考虑采用结构化并发的团队,建议的演进路径:
新项目:直接使用结构化并发作为基础并发模型。
现有项目:
-
首先在边缘服务或新功能中试点
-
逐步替换复杂的
ExecutorService用法 -
最后处理简单的并发场景
混合模式:在过渡期,可以与CompletableFuture等现有API共存。
这种渐进式采用策略类似于Jeep车型的迭代更新——保留经典设计元素的同时,逐步引入新技术和理念。
深度扩展与未来展望
结构化并发作为Java并发编程的新范式,其影响远超出API层面,将深刻改变开发者构建并发系统的思维方式。本节将探讨JEP 480的高级主题、潜在限制以及未来发展方向。
高级模式与技巧
掌握了基础用法后,让我们探索一些结构化并发的高级应用模式:
嵌套作用域:构建多级任务层次结构,实现更复杂的并发控制:
void processBatch(List<Item> batch) throws Exception {
try (var outerScope = new StructuredTaskScope.ShutdownOnFailure()) {
List<Subtask<Void>> subtasks = batch.stream()
.map(item -> outerScope.fork(() -> processItem(item)))
.toList();
outerScope.join();
outerScope.throwIfFailed();
}
}
void processItem(Item item) throws Exception {
try (var innerScope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<Validation> validation = innerScope.fork(() -> validate(item));
Subtask<Enrichment> enrichment = innerScope.fork(() -> enrich(item));
innerScope.join();
innerScope.throwIfFailed();
persist(validation.get(), enrichment.get());
}
}
这种嵌套结构类似于Jeep车队的分级指挥系统——大队分成若干小队,每个小队又有自己的内部组织。
超时控制:结合Future的超时机制,实现精细化的超时控制:
Response fetchWithTimeout(Duration timeout) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
Subtask<String> data = scope.fork(() -> fetchData());
Subtask<String> fallback = scope.fork(() -> fetchFromBackup());
scope.joinUntil(Instant.now().plus(timeout));
if (data.state() == Subtask.State.SUCCESS) {
return new Response(data.get());
} else if (fallback.state() == Subtask.State.SUCCESS) {
return new Response(fallback.get());
} else {
throw new TimeoutException("All attempts failed or timed out");
}
}
}
动态任务创建:根据运行时条件动态fork子任务:
void adaptiveProcessing(List<Data> dataList) throws Exception {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
List<Subtask<Result>> subtasks = new ArrayList<>();
for (Data data : dataList) {
if (needsProcessing(data)) {
subtasks.add(scope.fork(() -> process(data)));
}
}
scope.join();
scope.throwIfFailed();
List<Result> results = subtasks.stream()
.map(Subtask::get)
.toList();
// ...处理结果
}
}
与现有生态的整合
结构化并发需要与Java现有的并发生态整合:
与CompletableFuture互操作:
<T> CompletableFuture<T> toFuture(StructuredTaskScope<T> scope, Callable<T> task) {
CompletableFuture<T> future = new CompletableFuture<>();
scope.fork(() -> {
try {
T result = task.call();
future.complete(result);
return result;
} catch (Exception e) {
future.completeExceptionally(e);
throw e;
}
});
return future;
}
与Reactive Streams结合:将结构化并发作为底层实现,支持响应式编程模型:
Flux<Result> processConcurrently(List<Request> requests) {
return Flux.create(emitter -> {
try (var scope = new StructuredTaskScope.ShutdownOnFailure()) {
requests.forEach(request ->
scope.fork(() -> {
Result result = processRequest(request);
emitter.next(result);
return result;
}));
scope.join();
emitter.complete();
} catch (Exception e) {
emitter.error(e);
}
});
}
潜在限制与应对策略
结构化并发虽强大,也有其适用边界:
-
长时间运行任务:不适合需要长期运行的后台任务,这类任务更适合专用管理机制。
-
非结构化场景:某些复杂并发模式可能难以用严格层次结构表达。
-
学习曲线:开发者需要适应新的编程思维模式。
应对策略包括:
-
明确区分结构化与非结构化并发场景
-
提供充分的培训和文档
-
逐步采用,不搞“一刀切”
这与Jeep车型定位的策略相似——明确区分纯粹越野车(如牧马人)和城市SUV(如指南者),针对不同需求提供不同解决方案。
未来发展方向
基于当前实现和行业趋势,结构化并发可能朝以下方向发展:
-
更丰富的关闭策略:除了
ShutdownOnFailure和ShutdownOnSuccess,可能增加更精细的控制策略。 -
与Project Loom深度集成:进一步优化与虚拟线程的协同。
-
监控与可观察性增强:提供更强大的任务监控和调试支持。
-
模式库发展:社区可能发展出一套结构化并发设计模式。
-
语言层面支持:未来可能引入语法糖进一步简化使用。
这些演进将如同Jeep品牌持续创新,从纯机械越野向电气化、智能化发展,同时保持核心DNA。
架构决策考量
对于架构师而言,是否采用结构化并发应考虑以下因素:
| 考量维度 | 适合场景 | 不适合场景 |
|---|---|---|
| 任务相关性 | 逻辑上相关的任务组 | 完全独立的任务 |
| 生命周期 | 明确有限的生命周期 | 长期运行的后台任务 |
| 错误处理 | 需要协调错误处理 | 各任务错误处理独立 |
| 团队技能 | 愿意学习新范式 | 维护老旧代码库 |
决策矩阵可表示为:
其中权重 根据组织具体情况确定。
总结与最佳实践指南
经过对JEP 480结构化并发的全面探讨,我们已深入理解了这一新范式的设计理念、实现机制和应用场景。现在,让我们总结关键收获,并提供在实际项目中采用结构化并发的最佳实践指南。
核心价值再认识
结构化并发为Java开发者带来了三大根本性改进:
-
可靠性与安全性提升:通过强制性的任务层次结构和自动化的资源清理,几乎消除了线程泄漏和取消延迟等问题。正如Jeep车队引入严格编队管理后,车辆丢失事故大幅减少。
-
代码可维护性增强:代码结构真实反映运行时行为,使并发逻辑更易于理解和维护。这类似于Jeep从专业越野向城市化转型后,吸引了更广泛的用户群体。
-
可观察性改进:明确的任务父子关系使调试和监控更加直观。如同Jeep车队每辆车都配备GPS追踪器,指挥中心能清晰掌握整个车队状态。
采用决策框架
是否采用结构化并发应考虑以下决策框架:
任务相关性分析:
-
高相关性任务组:强烈建议使用
-
独立任务:传统并发模型可能更简单
错误处理需求:
-
需要协调错误处理:结构化并发优势明显
-
错误处理独立:两者皆可
团队准备度评估:
-
愿意接受新概念:适合采用
-
维护老旧系统:谨慎渐进式引入
性能需求考量:
-
高吞吐量IO密集型:与虚拟线程完美配合
-
计算密集型:需评估协调开销
迁移路径建议
对于现有系统的迁移,建议采用以下渐进路径:
识别热点:找出代码中最复杂的并发逻辑,这些往往最能从结构化并发中获益。
外围试点:在非核心功能或新功能中先行试点,如:
-
并行服务调用
-
批量数据处理
-
请求扇出模式
模式替换:逐步用结构化并发替换以下传统模式:
-
ExecutorService+ 多Future -
手动
Thread创建与管理 -
复杂的
CompletableFuture组合
全面推广:在团队积累足够经验后,制定代码规范推广使用。
反模式与陷阱规避
使用结构化并发时需警惕以下反模式:
-
过度嵌套:避免创建过深的嵌套作用域,通常不超过2-3层。
-
作用域泄露:确保
StructuredTaskScope总是在try-with-resources中使用。 -
阻塞父任务:避免在fork和join之间执行耗时操作。
-
忽略子任务状态:始终检查子任务状态,适当处理失败情况。
-
混合并发模型:避免在同一代码块混用结构化并发和传统并发模型。
性能调优技巧
为了获得最佳性能表现:
-
合理设置作用域粒度:将密切相关任务分组到同一作用域。
-
利用虚拟线程:与JEP 444虚拟线程配合使用以获得最佳扩展性。
-
选择性关闭:根据场景选择合适的关闭策略(
ShutdownOnFailure或ShutdownOnSuccess)。 -
监控与调整:使用
Subtask状态信息监控性能,持续优化。
未来展望
结构化并发代表了并发编程范式的重要演进方向,其影响力可能超越Java生态:
-
编程模型融合:可能与响应式编程、函数式编程等范式找到更深层次的结合点。
-
语言设计影响:可能启发更多语言设计时考虑结构化并发的原则。
-
系统架构演进:可能催生新一代基于结构化并发原语的分布式系统架构。
如同Jeep品牌80年来的持续创新,从军用越野到民用全场景车型的演进,Java并发模型也将继续发展,而结构化并发无疑是这一演进道路上的重要里程碑。
最终建议
作为专业架构师,我们建议:
-
积极评估:在下一个适合的项目中尝试结构化并发,亲身体验其优势。
-
教育团队:组织内部培训,帮助团队理解这一新范式。
-
制定规范:建立结构化并发的使用规范,确保一致的应用方式。
-
分享经验:参与社区交流,分享实践经验和模式发现。
结构化并发不是万能的银弹,但在适合的场景下,它能显著提升并发代码的质量和可靠性。正如不是所有SUV都叫Jeep,不是所有并发问题都适合结构化并发,但当你需要组织和管理复杂并发任务时,它无疑是最优雅的解决方案之一。


















 1014
1014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









