




 本文介绍了扩散模型,区分了其正向的加噪声过程和反向的去噪生成过程。与VAE的一次性编码解码不同,扩散模型通过分步骤进行自回归。着重讲解了噪声预测器的训练方法和推理过程,以及如何从高斯噪声图片逐渐恢复清晰图片。
本文介绍了扩散模型,区分了其正向的加噪声过程和反向的去噪生成过程。与VAE的一次性编码解码不同,扩散模型通过分步骤进行自回归。着重讲解了噪声预测器的训练方法和推理过程,以及如何从高斯噪声图片逐渐恢复清晰图片。
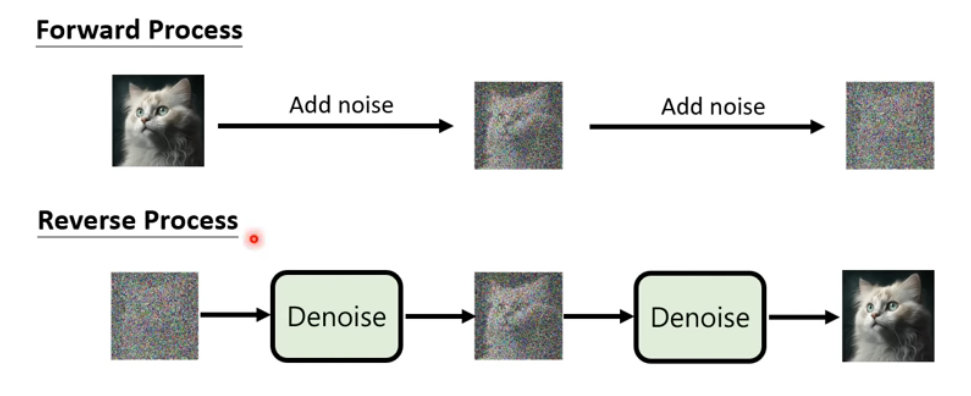
扩散模型分为正向过程和反向过程。
正向过程为一点点在图片上添加噪声的过程,反向过程为去噪声的过程。
图片的生成就是反向过程,给一张高斯噪声图片,逐步去噪生成图片。
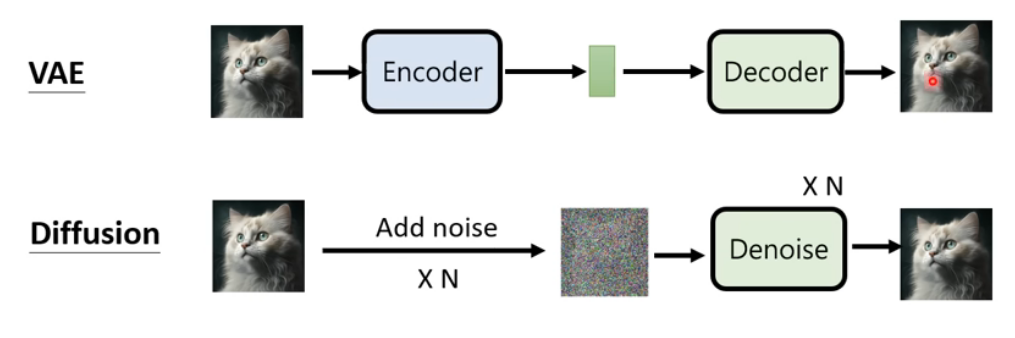
扩散模型和VAE的区别,
VAE是一步到位的(通过encoder-decoder),扩散模型要分成N个step, 是一个自回归过程。
扩散模型的训练过程
重复1到5行的过程,直到收敛。
每次采样一张图片
x
0
x_{0}
x0,t, 和高斯噪声图像
ϵ
\epsilon
ϵ。
α
t
ˉ
\bar{\alpha _{t} }
αtˉ是事先定义好的数字,你可以定义它随时间线性变小,也可以是cosine分布。在你采样 t 的时候,t 也同时对应了一个
α
t
ˉ
\bar{\alpha _{t} }
αtˉ。
ϵ
\epsilon
ϵ是高斯噪声图片,那么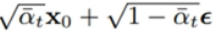 就表示在图片上添加噪声。
就表示在图片上添加噪声。
ϵ
θ
\epsilon_{\theta}
ϵθ可以理解为一个noise predictor, 它可以是一个网络,
i
n
p
u
t
input
input是加了噪声的图片和 t , 输出是一个噪声图片
ϵ
θ
(
i
n
p
u
t
)
\epsilon_{\theta}(input)
ϵθ(input),
根据采样的噪声
ϵ
\epsilon
ϵ和预测的噪声图片
ϵ
θ
(
i
n
p
u
t
)
\epsilon_{\theta}(input)
ϵθ(input)的误差来训练这个noise predictor,
使它能够输出尽可能接进
ϵ
\epsilon
ϵ的噪声。

上面的过程也说明了一个问题,
当你采样了 t, 是可以直接计算 t 时刻的加了噪声的图片的,
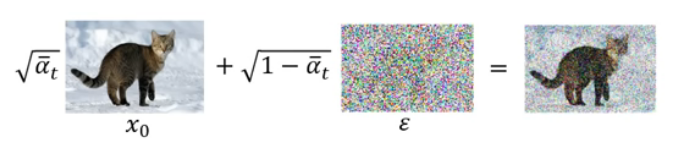
而不是想像中的这个样子:

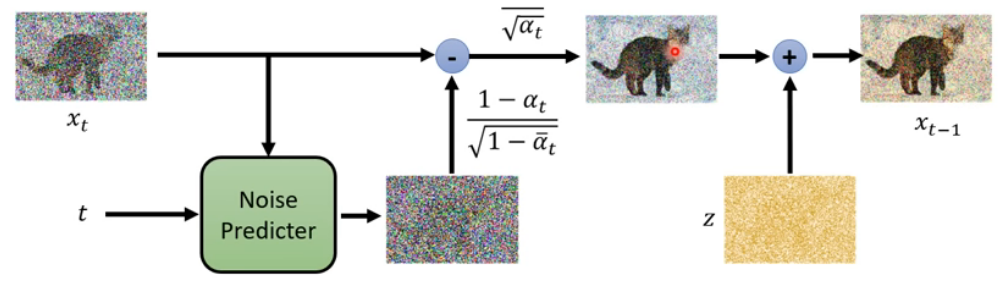
推理过程
前面提到了扩散模型有正向和反向过程,
在正向过程中,图片是
x
0
x_{0}
x0, 逐步加噪声,到T时刻的
x
T
x_{T}
xT是一个噪声图片。
推理过程是反向过程,根据高斯噪声的 x T x_{T} xT的得到图片 x 0 x_{0} x0.
ϵ
θ
\epsilon_{\theta}
ϵθ是前面训练过程中训练的noise predictor, 它的input为加了噪声的图片
x
t
x_{t}
xt和 t.
z
z
z也是一个采样的噪声图片。

上面的过程是这样的:
采样N次,直到得到清晰的
x
0
x_{0}
x0
公式推导部分待更新。



















 1808
1808

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











