




 本文介绍了价值函数在强化学习中的作用,阐述了状态价值函数的概念,以及如何通过动态规划和贝尔曼方程来评估策略和计算累积奖励。着重讲解了状态转移、轨迹和策略选择对价值函数的影响。
本文介绍了价值函数在强化学习中的作用,阐述了状态价值函数的概念,以及如何通过动态规划和贝尔曼方程来评估策略和计算累积奖励。着重讲解了状态转移、轨迹和策略选择对价值函数的影响。
这一次来由浅入深认识一下价值函数以及动态规划解决优化问题
首先我们要理解一下状态价值函数,这是bellman equation的第一次正式推导。
trajectory
作为一个trajectory,必须是一个完整的过程,也就是状态转移全部过程,从其实状态到终止状态,没有什么状态是达不到的,只是每种状态都会有代价或者是收益而已。
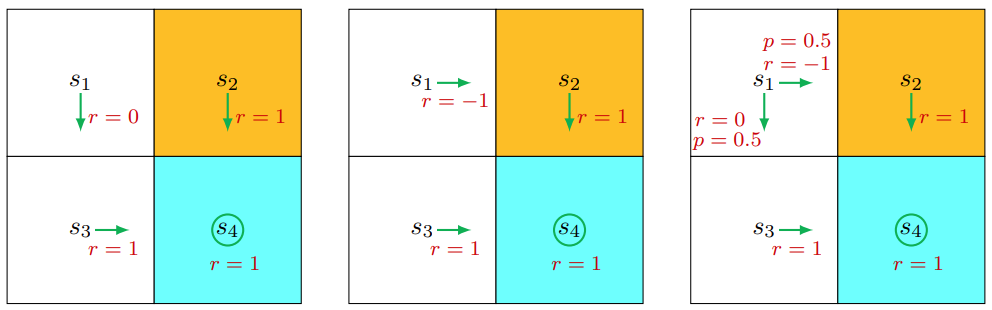
这里就展示了几条不同的trajectory,注意哈,trajectory可以是像第三种那样的有多条方向的
return
累计奖励是根据一条trajectory得到的,也就是说,针对每一种trajectory都会有一个return,它就是评价我的trajectory好不好的一种方式。所以说到这里,trajectory有点像策略的意思了。
viv_ivi
反应一个trajectory好不好,当然就是用到v价值函数了。
v1=r1+γr2+γ2r3+⋯v_1=r_1+\gamma r_2+\gamma^2r_3+\cdotsv1=r1+γr2+γ2r3+⋯
v2=r2+γr3+γ2r4+⋯v_2=r_2+\gamma r_3+\gamma^2r_4+\cdotsv2=r2+γr3+γ2r4+⋯
v3=r3+γr4+γ2r1+⋯v_3=r_3+\gamma r_4+\gamma^2r_1+\cdotsv3=r3+γr4+γ2r1+⋯
v4=r4+γr1+γ2r2+⋯v_4=r_4+\gamma r_1+\gamma^2r_2+\cdotsv4=r4+γr1+γ2r2+⋯
其实可以看的出来,他和return没有什么区别。它就是return存在的意义。
接下来做一个递归:
v1=r1+γr2+γ2r3+⋯=r1+γv2v_1=r_1+\gamma r_2+\gamma^2r_3+\cdots=r_1+\gamma v_2v1=r1+γr2+γ2r3+⋯=r1+γv2
v2=r2+γr3+γ2r4+⋯=r2+γv3v_2=r_2+\gamma r_3+\gamma^2r_4+\cdots=r_2+\gamma v_3v2=r2+γr3+γ2r4+⋯=r2+γv3
v3=r3+γr4+γ2r1+⋯=r3+γv4v_3=r_3+\gamma r_4+\gamma^2r_1+\cdots=r_3+\gamma v_4v3=r3+γr4+γ2r1+⋯=r3+γv4
v4=r4+γr1+γ2r2+⋯=r4+γv1v_4=r_4+\gamma r_1+\gamma^2r_2+\cdots=r_4+\gamma v_1v4=r4+γr1+γ2r2+⋯=r4+γv1
写成矩阵的形式就是:
[v1v2v3v4]=[v1v2v3v4]+γP[v1v2v3v4]\left[\begin{matrix}
v_1 \\ v_2 \\ v_3 \\ v_4 \end{matrix} \right]
=\left[\begin{matrix}v_1 \\ v_2 \\ v_3 \\ v_4 \end{matrix}\right]+\gamma P\left[\begin{matrix}
v_1 \\ v_2 \\ v_3 \\ v_4 \end{matrix} \right]v1v2v3v4=v1v2v3v4+γPv1v2v3v4
简写为:
v=v+γPv\pmb{v}=\pmb{v}+\gamma P \pmb{v}v=v+γPv
其实也就是两部分,即时奖励和未来奖励。
GtG_tGt
考虑一条trajectory:
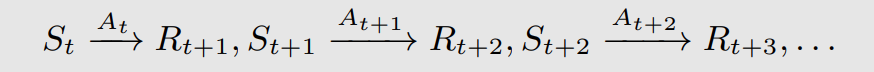
这里看起来是确定的action和reward,但是也可以是有转移概率的:
p(r∣s,a)p(r|s,a)p(r∣s,a)
位于状态s,采取动作a后的奖励r的概率
p(s′∣s,a)p(s'|s,a)p(s′∣s,a)
位于状态s,采取动作a后的状态s’的概率
当然,计算的G(t)G(t)G(t)用不到,它本身就是上面v函数的一个表示:
G(t)=Rt+1+γRt+2+γ2Rt+3+cdotsG(t)=R_{t+1}+\gamma R_{t+2}+\gamma^2 R_{t+3}+cdotsG(t)=Rt+1+γRt+2+γ2Rt+3+cdots
这个其实也是累计奖励。return和v函数和它有什么区别呢?下面介绍状态价值函数
Vπ(s)V_{\pi}(s)Vπ(s)
这里开始深入强化学习的本质了,所有的价值函数都不是用来玩的,状态价值看似只与状态有关,其实隐含着与策略有关,甚至可以写成是v(π,s)v(\pi,s)v(π,s),所以不要再觉得它没用了。
价值函数的定义式非常简单:
vπ(s)=E[Gt∣St=s]v_\pi(s)=\mathbb{E}[G_t|S_t=s]vπ(s)=E[Gt∣St=s]
也就是处于状态s时的累计奖励。千万注意它是基于策略的函数,不同的策略会得到不同的价值函数,这样我们就能评价策略的好坏
以下是一个具体的例子:

怎么说呢,如果策略是确定的,那么就只与s有关,但是如果是在选在策略的过程中,价值函数是一直都在变化的。
状态价值函数与bellman equation
状态价值函数可以进一步表示,将累计奖励GtG_tGt迭代展开:
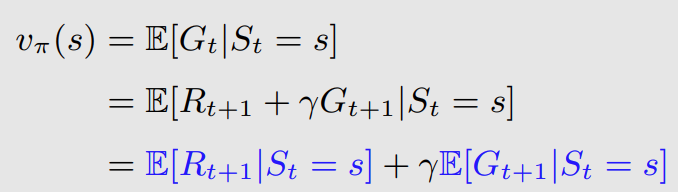
这样我们求的就变成了两个期望,期望就是加权平均,先看左边的式子,就是从状态s出发得到的r的期望,我们把它转化为标准的状态s,动作a的格式,并且引入在状态s动作a时的奖励概率来消除期望符号:
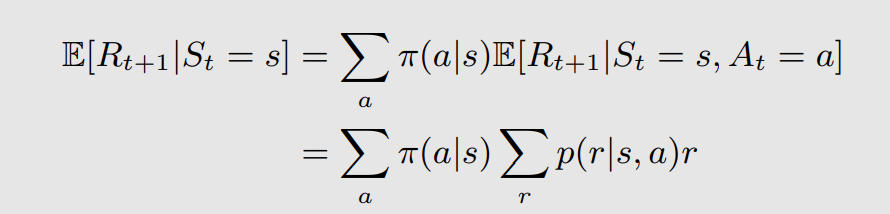
右边的式子也是一样的,主要目标是消除掉期望符号,于是通过状态转移概率来化简:
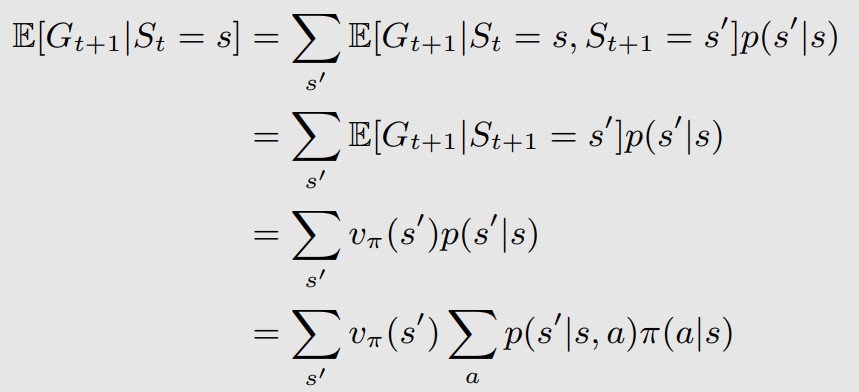
然后综合两者就得到了bellman公式了:
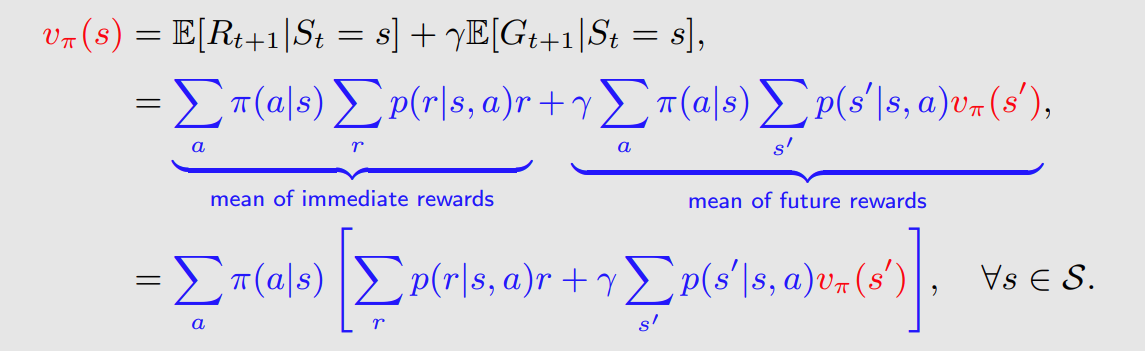
概率部分是模型,红色的是我们要求的价值函数,策略是用来评价的,所以计算时也是给定的。
以上就完成了bellman公式的分析过程。


















 3152
3152

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











