







 本文精选2018年深度学习领域的重要进展,包括RFB模块的创新感受野模仿,知识蒸馏技术实现小模型高性能,ScSE模块的轻量化空间与通道加权,以及可变卷积的灵活应用。这些技术覆盖了从模型结构优化到训练策略的多个方面。
本文精选2018年深度学习领域的重要进展,包括RFB模块的创新感受野模仿,知识蒸馏技术实现小模型高性能,ScSE模块的轻量化空间与通道加权,以及可变卷积的灵活应用。这些技术覆盖了从模型结构优化到训练策略的多个方面。
【2018-新概念-深度学习-年度总结】:
一、RFB模块
文章地址:https://arxiv.org/abs/1711.07767 CVPR2017,虽然是2017年的,但是我还是要说
代码地址:https://github.com/ruinmessi/RFBNet
推荐代码地址:https://github.com/lzx1413/PytorchSSD
核心思想:
1、模仿人的感受野,虽然这个感念说的很高级,模块和inception差不多,但是效果确实非常好,这也告诉我们,给cnn更高的可解释性,能够很好的去提高模型能力,大自然鬼斧神工创造人类,我们能从大自然的妙笔中学到很多。
2、他的模块结构和inception结构比较像
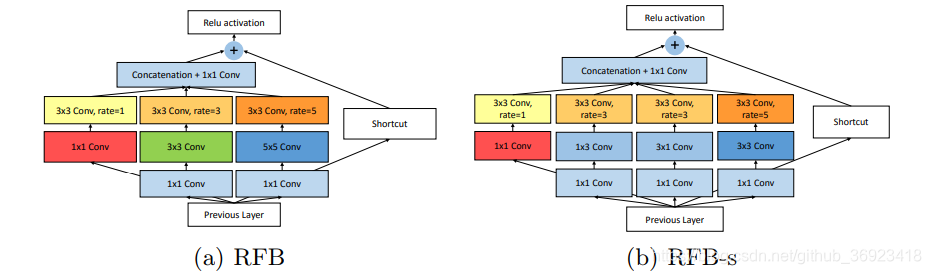
上图中rate代表了dilated convolution的dilated rate。
shortcut代表了![]() 公式后面的+x 或者说+Wx
公式后面的+x 或者说+Wx
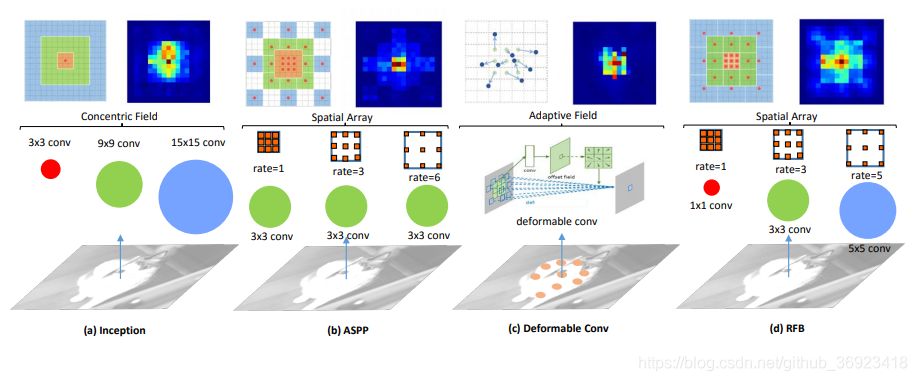
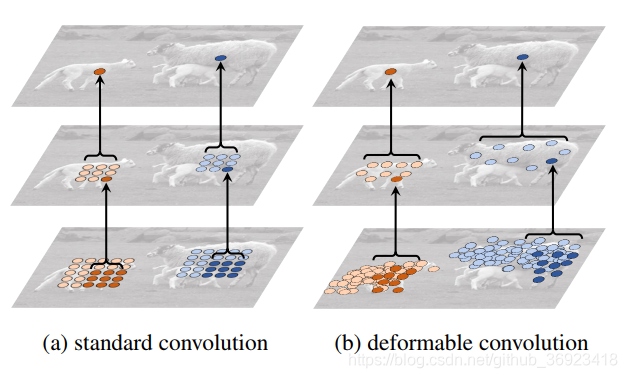
这是最近一些新内容的感受野对比,RFB的感受野从对比来看是比较不错的,但是deformable conv的感受野虽然小但是,也是因为他是”强有效感受野“。
而且,RFB这个模块没有改变SSD的基本结构,而是直接应用上去,效果有很大的提升!
二、知识蒸馏
这是一个训练手段,可以让我们的到最终效果较好的非常小的模型!!!我们选择“Fast Human Pose Estimation ” 这篇文章为例子!之所以会有知识蒸馏的存在,我们客观的知道CNN网络中会存在不少没有用的卷积核,所以也存在一些技术“模型压缩”、“模型裁剪”等。而知识蒸馏是,通过学习去用小模型学习大模型中的有用参数!
文章地址:https://arxiv.org/pdf/1811.05419.pdf
模块名称:Fast Pose Distillation (FPD) model training method
1、模块结构:
依然是基于Hourglass这个经典单人姿态估计模型做的改进!大量减少了小模型的通道数!
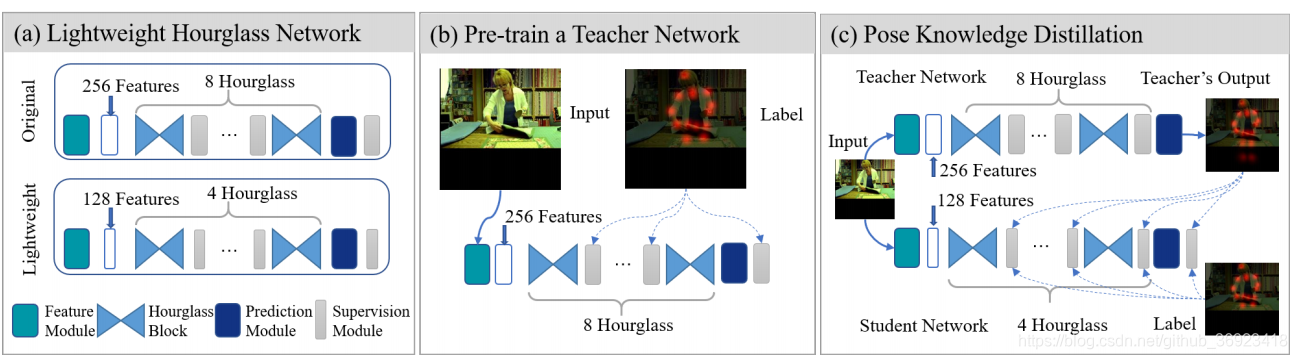
图a是两个单独的hourglass网络,一个大,一个小!首先训练那个比较大的网络去得到一个目前比较好的结果,然后通过图c的手段,去训练小网络,将大网络的有效学习成果传给小网络!
Student Network因此有两个label来源,一个是Groundtruth 另一个是Teacher Network的输出TOutput!
![]()
两部分的loss利用参数来平衡!
三、Spatial and Channel ‘Squeez e & Excitation’
文章地址:https://arxiv.org/pdf/1803.02579.pdf
文章名称:Concurrent Spatial and Channel ‘Squeeze & Excitation’ in Fully Convolutional Networks
代码地址:稍后更新!
1、模块结构
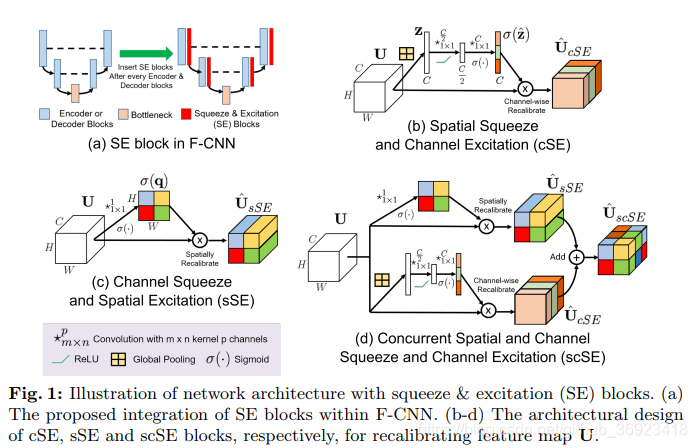
这个模块,有着很高的价值!非常轻量级的空间加权及通道加权方案!几乎可以用在所有现存的各种人物的CNN中!可以覆盖“分割”、“识别”、“分类”、“检测”等大多数计算机视觉任务!
这个模块最终整合为ScSE!也就是同时采用空间加权和通道加权!
空间加权:通过1*1卷积核,把feature maps 压缩成1通道,在经过sigmoid激活函数,变成空间加权map
通道加权:利用global pooling,这里我持中立态度,因为这部分feature maps比较大的话,global pooling可能不会有太好的效果;然后利用两个全连接层再通过sigmoid得到channel weights。
四、可变卷积 “Deformable Convolutional”
论文地址:https://arxiv.org/pdf/1703.06211.pdf
扩展包:https://github.com/oeway/pytorch-deform-conv
1、模块效果对比

















 3375
3375

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









