



在这篇博客文章中,我们将展示如何使用 gradio_client Python 库,该库允许开发者以编程方式向 Gradio 应用发出请求,通过创建一个示例 FastAPI 网络应用程序。我们将要构建的网络应用程序称为"Acapellify",它将允许用户上传视频文件作为输入,并返回一个没有伴奏音乐的视频版本。它还将展示一个生成视频的画廊。
先决条件
在我们开始之前,请确保您运行的是 Python 3.9 或更高版本,并且已经安装了以下库:
gradio_clientfastapiuvicorn
您可以从 pip 安装这些库:
$ pip install gradio_client fastapi uvicorn您还需要安装 ffmpeg。您可以通过在终端运行来检查是否已经安装了 ffmpeg:
$ ffmpeg version否则,请按照这些说明安装 ffmpeg。
第一步:编写视频处理函数
让我们从看似最复杂的部分开始 —— 使用机器学习从视频中移除音乐。
幸运的是,有一个现成的空间可以让这个过程更简单:https://huggingface.co/spaces/abidlabs/music-separation。这个空间接受一个音频文件,并生成两个独立的音频文件:一个包含原始剪辑中的乐器音乐,另一个包含所有其他声音。非常适合我们的客户使用!
打开一个新的 Python 文件,比如说 main.py ,然后从 gradio_client 中导入 Client 类,并将其连接到这个空间:
from gradio_client import Client
# 创建一个Client实例,指定了要使用的API服务为"abidlabs/music-separation"
client = Client("abidlabs/music-separation")
def acapellify(audio_path):
"""
使用指定的音乐分离服务,从提供的音频路径中分离出人声部分。
:param audio_path: 音频文件的路径。
:return: 分离出的人声音频的路径或结果。
"""
# 使用client的predict方法提交预测任务,指定api_name为"/predict"
# 这里预设"/predict"为该服务分离人声的API端点
result = client.predict(audio_path, api_name="/predict")
# 假设服务返回的结果是一个列表,其中第一个元素是我们需要的人声音频的路径或结果
return result[0]这就是所需的全部代码 -- 请注意 API 端点返回两个音频文件(一个没有音乐,一个只有音乐)在一个列表中,所以我们只返回列表的第一个元素。
注意:由于这是一个公共空间,可能还有其他用户在使用这个空间,这可能会导致体验缓慢。您可以用您自己的 Hugging Face 令牌复制这个空间,并创建一个只有您能访问的私人空间,以绕过队列。要做到这一点,只需将上面的前两行替换为:
from gradio_client import Client
client = Client.duplicate("abidlabs/music-separation", hf_token=YOUR_HF_TOKEN)其他一切保持不变!
现在,当然,我们正在处理视频文件,所以我们首先需要从视频文件中提取音频。为此,我们将使用 ffmpeg 库,它在处理音频和视频文件时做了很多繁重的工作。使用 ffmpeg 的最常见方式是通过命令行,我们将通过 Python 的 subprocess 模块调用它:
我们的视频处理工作流将包括三个步骤:
首先,我们开始通过使用
ffmpeg提取视频文件路径中的音频。然后,我们通过上面的
acapellify()函数传入音频文件。最后,我们将新音频与原始视频结合,制作出最终的无伴奏视频。
这是完整的 Python 代码,您可以将其添加到您的 main.py 文件中:
import subprocess
import os
from gradio_client import Client
# 假设acapellify函数已经定义好,并且可以调用
# def acapellify(audio_path):
# ... # acapellify函数的定义
def process_video(video_path):
"""
处理视频文件,将其音频部分替换为仅包含人声的音频。
:param video_path: 视频文件的路径。
:return: 新视频文件的名称。
"""
# 提取原视频文件名,去除扩展名后添加新的音频扩展名.m4a
old_audio = os.path.basename(video_path).split(".")[0] + ".m4a"
# 使用ffmpeg提取原视频的音频部分,保存为old_audio指定的文件
subprocess.run(['ffmpeg', '-y', '-i', video_path, '-vn', '-acodec', 'copy', old_audio])
# 调用acapellify函数处理提取的音频,获取只包含人声的音频文件路径
new_audio = acapellify(old_audio)
# 为新视频文件构造文件名,前面加上"acap_"前缀
new_video = f"acap_{os.path.basename(video_path)}"
# 使用ffmpeg结合原视频和新的人声音频生成新的视频文件
# 新视频文件保存在"static/"目录下
subprocess.call(['ffmpeg', '-y', '-i', video_path, '-i', new_audio, '-map', '0:v', '-map', '1:a', '-c:v', 'copy', '-c:a', 'aac', '-strict', 'experimental', f"static/{new_video}"])
return new_video
如果您想了解所有命令行参数,可以阅读 ffmpeg 文档,因为它们超出了本教程的范围。
步骤 2:创建一个 FastAPI 应用程序(后端路由)
接下来,我们将创建一个简单的 FastAPI 应用程序。如果您以前没有使用过 FastAPI,请查看一下精彩的 FastAPI 文档。否则,这个基本模板,我们添加到 main.py ,会看起来非常熟悉:
import os
import subprocess
from fastapi import FastAPI, File, UploadFile, Request
from fastapi.responses import HTMLResponse, RedirectResponse
from fastapi.staticfiles import StaticFiles
from fastapi.templating import Jinja2Templates
# 假设acapellify和process_video函数已经定义好
# def acapellify(audio_path):
# ... # acapellify函数的定义
# def process_video(video_path):
# ... # process_video函数的定义
app = FastAPI()
os.makedirs("static", exist_ok=True) # 确保有一个用来保存静态文件的目录
app.mount("/static", StaticFiles(directory="static"), name="static") # 将静态文件目录挂载至"/static"路径
templates = Jinja2Templates(directory="templates") # 设置Jinja2模板文件的目录
videos = [] # 初始化一个空列表用于存储处理后的视频文件名
@app.get("/", response_class=HTMLResponse)
async def home(request: Request):
"""
根处理函数,返回主页的HTML响应。
:param request: 请求对象,由FastAPI自动提供。
:return: 返回使用Jinja2渲染的home.html模板。
"""
return templates.TemplateResponse(
"home.html", {"request": request, "videos": videos}) # 渲染模板,并传入当前已处理的视频列表
@app.post("/uploadvideo/")
async def upload_video(video: UploadFile = File(...)):
"""
处理视频文件上传的路由。
:param video: 上传的视频文件。
:return: 重定向响应,导航回主页。
"""
# 将上传的视频文件保存到静态目录中
filepath = os.path.join("static", video.filename)
with open(filepath, "wb") as buffer:
buffer.write(video.file.read())
new_video = process_video(filepath) # 调用process_video函数处理视频文件
videos.append(new_video) # 将处理后的新视频文件名添加到videos列表中
return RedirectResponse(url='/', status_code=303) # 上传完成后重定向回主页在这个例子中,FastAPI 应用程序有两个路由: / 和 /uploadvideo/ 。
/ 路由返回一个 HTML 模板,用于显示所有已上传视频的画廊。
/uploadvideo/ 路由接受一个带有 UploadFile 对象的 POST 请求,该对象代表上传的视频文件。视频文件通过 process_video() 方法“无伴奏化”,并且输出视频被存储在一个列表中,该列表在内存中存储所有上传的视频。
请注意,这是一个非常基础的例子,如果这是一个生产应用程序,您将需要添加更多逻辑来处理文件存储、用户认证和安全考虑。

第三步:创建一个 FastAPI 应用程序(前端模板)
最后,我们创建我们网页应用的前端。首先,在与 main.py 相同的目录中创建一个名为 templates 的文件夹。然后在 templates 文件夹内创建一个模板, home.html 。以下是结果文件结构:
├── main.py
├── templates
│ └── home.html将以下内容写入 home.html :
<!DOCTYPE html> <html> <head> <title>Video Gallery</title>
<style> body { font-family: sans-serif; margin: 0; padding: 0;
background-color: #f5f5f5; } h1 { text-align: center; margin-top: 30px;
margin-bottom: 20px; } .gallery { display: flex; flex-wrap: wrap;
justify-content: center; gap: 20px; padding: 20px; } .video { border: 2px solid
#ccc; box-shadow: 0px 0px 10px rgba(0, 0, 0, 0.2); border-radius: 5px; overflow:
hidden; width: 300px; margin-bottom: 20px; } .video video { width: 100%; height:
200px; } .video p { text-align: center; margin: 10px 0; } form { margin-top:
20px; text-align: center; } input[type="file"] { display: none; } .upload-btn {
display: inline-block; background-color: #3498db; color: #fff; padding: 10px
20px; font-size: 16px; border: none; border-radius: 5px; cursor: pointer; }
.upload-btn:hover { background-color: #2980b9; } .file-name { margin-left: 10px;
} </style> </head> <body> <h1>Video Gallery</h1> {% if videos %}
<div class="gallery"> {% for video in videos %} <div class="video">
<video controls> <source src="{{ url_for('static', path=video) }}"
type="video/mp4"> Your browser does not support the video tag. </video>
<p>{{ video }}</p> </div> {% endfor %} </div> {% else %} <p>No
videos uploaded yet.</p> {% endif %} <form action="/uploadvideo/"
method="post" enctype="multipart/form-data"> <label for="video-upload"
class="upload-btn">Choose video file</label> <input type="file"
name="video" id="video-upload"> <span class="file-name"></span> <button
type="submit" class="upload-btn">Upload</button> </form> <script> //
Display selected file name in the form const fileUpload =
document.getElementById("video-upload"); const fileName =
document.querySelector(".file-name"); fileUpload.addEventListener("change", (e)
=> { fileName.textContent = e.target.files[0].name; }); </script> </body>
</html>第四步:运行您的 FastAPI 应用程序
最后,我们准备运行我们的 FastAPI 应用程序,由 Gradio Python 客户端提供支持!
打开终端并导航到包含 main.py 的目录。然后在终端运行以下命令:
$ uvicorn main:app你应该会看到一个像这样的输出:
Loaded as API: https://abidlabs-music-separation.hf.space ✔
INFO: Started server process [1360]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://127.0.0.1:8000 (Press CTRL+C to quit)就是这样!开始上传视频,你会收到一些“acapellified”的视频响应(根据你的视频长度,处理时间可能需要几秒到几分钟)。上传两个视频后,用户界面看起来是这样的:
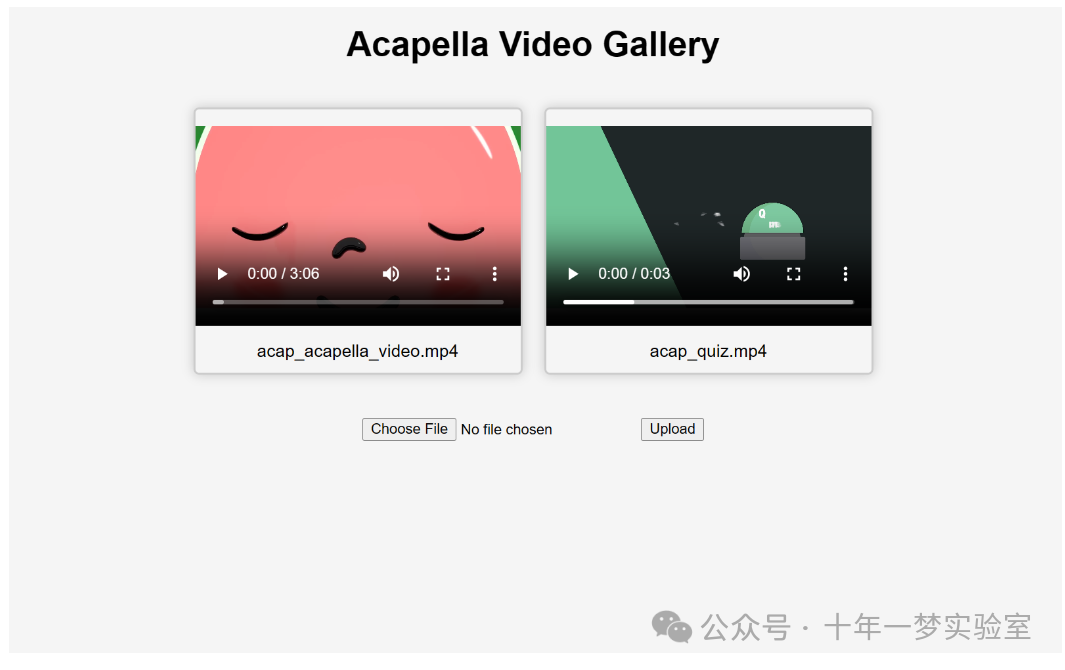
如果您想了解更多关于如何在项目中使用 Gradio Python 客户端,请阅读专用指南。

















 2787
2787

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









