








目录
1.大模型服务吞吐率
大模型服务吞吐率是指系统在单位时间内能够处理的大模型服务请求数或操作数,通常以每秒钟处理的请求数来衡量。其计算公式为:

其受多种因素影响:包括模型的复杂度、计算资源的分配、数据的并行度和模型并行度、硬件性能以及网络延迟等。例如,复杂的模型结构可能导致计算量增大,从而降低吞吐率;而增加计算资源、采用并行计算技术等则可能提高吞吐率。
与服务质量密切相关:较高的吞吐率通常意味着系统能够更快地响应用户的请求,提供更及时的服务,从而提升用户体验。在处理大规模并发请求时,高吞吐率可以减少用户的等待时间,避免系统出现卡顿或响应缓慢的情况。
2.投机采样
投机采样(Speculative Sampling)是一种加速语言生成的技术。它基于这样的想法:不是每次都让模型完整地生成一个 token(单词或子词),而是先使用一个小而快的 “草稿” 模型来推测可能的 token 序列。这个 “草稿” 模型比完整的大模型速度更快,但准确性可能稍差。
基于对大模型推理的两个关键观察,一是大多数容易生成的 tokens 其实用更少参数的模型也可以生成;二是大模型推理受限于内存带宽。所以采用 draft-and-verify 的方式,使用 drafter(小参数模型)一次生成多个候选 tokens,然后让大参数模型对所有生成的 tokens 并行验证,达到一次生成多个 tokens 的目标,从而提高吞吐率。
在推理阶段,给定输入序列,利用投机模型生成多个(通常是一个小批量)候选输出token。投机模型根据输入序列的特征和已生成的部分输出(如果有),按照其学习到的概率分布生成下一个可能的token列表。

主模型对投机模型生成的候选 token 进行验证。主模型计算每个候选 token 在其自身概率分布下的概率。

但是投机采样,一般适用于GPU使用率小于60%的时候采用。
采用这种方法,其吞吐率可以表示为
假设大模型生成一个 token 的时间为T1,小模型生成n个候选 tokens 的时间为T2,大模型验证个候选 tokens 的时间为T3,在理想情况下,当T2+T3=T1时,就可以在接近大模型生成一个 token 的时间里面生成了n个 tokens,从而提高吞吐率。
3.增大batch size
增加batchsize,其主要是用于提高吞吐率公式中的分子参数。
在一定范围内,增大 batchsize 可以让模型一次处理更多的数据,从而更充分地利用计算资源,减少处理单个请求的平均时间,进而提高吞吐率。因为在处理多个样本时,模型中的许多计算可以并行进行,例如在计算矩阵乘法等操作时,批量数据可以在硬件层面实现并行计算,提高计算效率。
在增大 batchsize 之前,需要对硬件资源进行评估。主要考虑 GPU 的内存容量、计算核心数量以及 CPU 与 GPU 之间的数据传输带宽等因素。确定硬件能够支持的最大 batchsize 范围,避免因 batchsize 过大导致内存溢出或性能下降。
在实际使用时,从一个较小的合适 batchsize 开始,逐步增加 batchsize 的值,并在每次增加后进行性能测试。测试内容包括模型的训练速度、推理速度、内存占用情况以及输出质量(如训练时的损失函数值、推理时的生成准确性等)。
设原来的 batchsize 为m,处理时间为t1,吞吐率为R1=m/t1。增大后的 batchsize 为n,处理时间为t2,若t2的增加幅度小于n相对于m的增加幅度,则新的吞吐率R2=n/t2会大于R1。
但是增加batchsize的方法,其会带来单个用户的处理延迟。同时如果 batchsize 过大,会导致 GPU 内存不足,无法正常进行计算。
在训练过程中,过大的 batchsize 可能会使模型过拟合,或者使模型无法很好地适应小批量数据的分布变化。在推理过程中,过大的 batchsize 可能会增加延迟,因为需要等待整个 batch 的数据处理完成才能输出结果。
4.continuous batching
传统的静态批处理或动态批处理方式可能会导致 GPU 未得到充分利用。Continuous Batching 允许请求在到达时一起批量处理,当一个输入提示生成结束之后,就会在其位置将新的输入 prompt 插入进来,从而比静态批处理具备更高的 GPU 利用率,进而提高吞吐率。而 Continuous Batching 打破了这种固定长度的限制,它允许在一个批次中,当一个样本生成结束后,立即在其位置插入新的样本进行处理。这样可以动态地利用计算资源,避免了传统批处理方式中因为部分样本生成速度慢而导致的资源闲置问题。
用网络上比较流行的一个示意图表示:
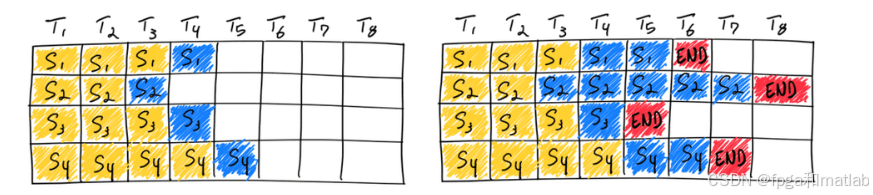
先看左图,在第一遍迭代中,每个序列从提示词(Y)中生成一个标记(Blue)。
再看右图,通过多次迭代后,由于每个序列在不同的迭代结束时产生不同的结束序列标记(Red)完成的序列具有不同的尺寸。
V
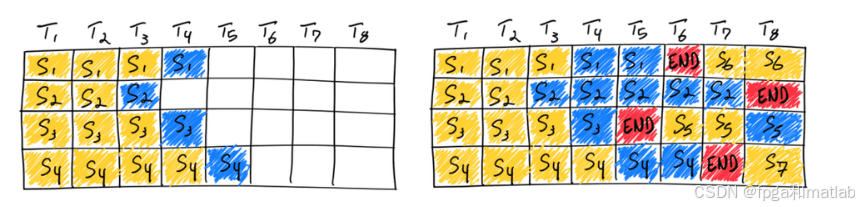
左图显示了单个迭代后的批,右图显示了多次迭代后的批。一旦一个序列产生结束序列标记(Red),则在其位置插入新的序列(如图中序列S5、S6和S7)。这实现了更高的 GPU 利用率,因为 GPU 不需要等待所有序列完成才开始新的一个。
这个有点类似FPGA开发过程中的流水线开发模式。
假设传统批处理方式下,一批次处理n个请求的总时间为Tbatch,其中每个请求的平均处理时间为tavg,则Tbatch=n*tavg。在 Continuous Batching 方式下,由于更高效的资源利用,假设处理n个请求的总时间为Tcbatch,对比上面两个图可以知道,Tcbatch<Tbatch,则吞吐率R2=n/Tcbatch会大于传统批处理方式下的吞吐率R1=n/Tbatch。
其python示意代码如下:
# Continuous Batching 的示例代码
def continuous_batching():
class ContinuousBatchingDataset:
def __init__(self, data):
self.data = torch.tensor(data, dtype=torch.float32)
self.queue = []
self.max_queue_size = 4 # 最大队列长度
self.current_index = 0
def add_to_queue(self, new_data):
if len(self.queue) < self.max_queue_size:
self.queue.append(new_data)
else:
self.queue[self.current_index] = new_data
self.current_index = (self.current_index + 1) % self.max_queue_size
def get_batch(self):
batch = torch.stack(self.queue)
return batch
# 示例数据,假设有 100 个样本,每个样本维度为 10
data = torch.randn(100, 10)
dataset = ContinuousBatchingDataset(data)
model = SimpleModel()
criterion = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
# 模拟添加数据到队列
for i in range(20): # 假设分 20 次添加数据
new_data = torch.randn(1, 10)
dataset.add_to_queue(new_data)
if len(dataset.queue) == dataset.max_queue_size:
batch = dataset.get_batch()
optimizer.zero_grad()
outputs = model(batch)
labels = torch.randint(0, 2, (dataset.max_queue_size,)) # 随机生成标签,这里只是示例
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
print(f"Batch processed with size {len(batch)}.")

















 860
860

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











